第5章 Linux上管理文件系统
5.1 机械硬盘
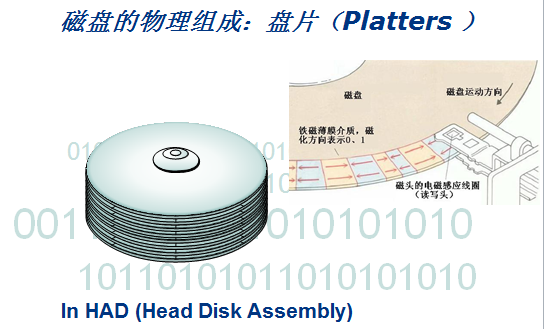
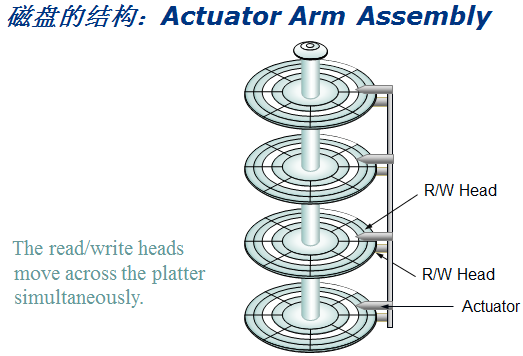
机械硬盘由多块盘片组成,它们都绕着主轴旋转。每块盘片上下方都有读写磁头悬浮在盘片上下方,它们与盘片的距离极小。在每次读写数据时盘片旋转,读写磁头被磁臂控制着不断的移动来读取其中的数据。
所有的盘片都是同时同步转动,所有的磁头也是同步移动。

磁盘在物理上划分了扇区、磁道和柱面。如果划分了分区,则分区是逻辑上柱面的分隔边界。
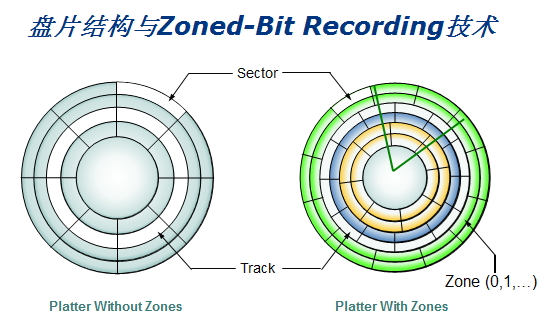
读写磁头在停止状态下,在盘片旋转时磁头扫过的一圈轨迹称为磁道,所有的磁道都是同心圆。从盘片外圈开始向内数,磁道号从0开始逐数增加。
每个磁道以512字节等分为多个弧段,每个弧段就是一个扇区。但是需要说明的是,扇区的大小并非一定是512字节。所以外圈磁道的扇区数较多,内圈磁道的扇区数较少,有些硬盘参数上写的磁道扇区数通常用一个范围来标识,如373-768表示最外圈磁道有768个扇区,最内圈有373个扇区,这就可以计算出每个磁道的字节数。
扇区上记录了物理数据、扇区号、磁头号(或者盘片号)及磁道号。

旧式磁盘的结构不分区(without zones),每个磁道扇区数相同,但是每个扇区仍然是512字节,也就是说磁性材料记录的0和1的数量是相同的。这种结构的缺点是外圈磁道的面积大,存储的数据分布宽松,内圈磁道面积小,存储的数据分布密集,这样就导致盘片外圈面积浪费。
新式磁盘结构进行了分区,将每个磁道等面积划分512字节的空间作为一个扇区,所以不同磁道扇区数不同。
现在的磁盘都是新式扇区划分结构。
将所有盘片相同磁道数的磁道划分为柱面。和磁道号的标记方式一样,从外向内从0开始逐数增加。
之所以划分柱面,是因为所有磁盘同步旋转,所有磁头同步移动,所有的磁头在任意一个时刻总是会出在同一个磁道同一个扇区上。读写数据时,任意一段数据总是按柱面来读写的。所以盘片数越多,读写所扫的扇区数就越少,所需的时间相对就越少,性能就越好。
向磁盘写数据是从外圈柱面向内圈柱面写的,只有写完一个柱面才写下一个柱面。

5.2 磁盘或分区容量计算
虽然现在的磁盘都是新式结构(每磁道扇区数不同),但是在磁盘信息上还是根据旧式结构来计算的,也就是说每个磁道扇区数相同,"扇区/磁道"的值说明每个磁道上有多少个扇区,也可以将其认为是新式结构下的平均值。
磁盘相关英文:
|
disk |
磁盘 |
|
heads |
磁头。Linux系统中查看到的heads一般包括很多虚拟磁头,实际的物理磁盘的一块盘片上下两面一面一磁头,即2个磁头。 |
|
sectors |
扇区。一磁道上划分多个扇形区域,一般默认一扇区512字节。 |
|
track |
磁道。盘片上一圈算一磁道。 |
|
cylinders |
柱面。所有盘片的同一半径的磁道组成一柱面。柱面数=盘片数*盘片上的磁道数。 |
|
units |
单元块。大小等于一个柱面大小。 |
磁盘或分区大小计算方法:
磁盘大小=units×柱面数(cylinders)
磁盘大小=磁头数(heads)×每磁道上的扇区数(sectors)×512×柱面数(cylinders)
例如:查看/dev/sda3。
[root@xuexi tmp]# fdisk -l /dev/sda3 Disk /dev/sda3: 19.1 GB, 19116589056 bytes # 总大小19G 255 heads, 63 sectors/track, 2324 cylinders # 磁头255 柱面2324 每磁道扇区数63(这是平均数) Units = cylinders of 16065 * 512 = 8225280 bytes # 单元块大小 Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x00000000
Units=255×63×512=16065×512=8225280
磁盘大小=255*63*2324*512=19115550720= 19.11555072GB,不用1024算,用1000算。
5.3 分区
分区是为了在逻辑上将某些柱面隔开形成边界。它是以柱面为单位来划分的,但是从CentOS 7开始,是按照扇区进行划分的。
在磁盘数据量非常大的情况下,划分分区的好处是扫描块位图等更快速:不用再扫描整块磁盘的块位图,只需扫描对应分区的块位图。
5.3.1 分区方法(MBR和GPT)
MBR格式的磁盘中,会维护磁盘第一个扇区——MBR扇区,在该扇区中第446字节之后的64字节是分区表,每个分区占用16字节,所以限制了一块磁盘最多只能有4个主分区(Primary,P),如果多于4个区,只能将主分区少于4个,通过建立扩展分区(Extend,E),然后在扩展分区建立逻辑分区(Logical,L)的方式来突破4个分区的限制,逻辑分区的数量不限制。
在Linux中,MBR格式的磁盘主分区号从1-4,扩展分区号从2-4,逻辑分区号从5开始。
例如,一块盘想分成6个分区,可以:
1P+5L:sda1+sda5+sda6+sda7+sda8+sda9
2P+4L:sda1+sda2+sda5+sda6+sda7+sda8
3P+3L:sda1+sda2+sda3+sda5+sda6+sda7
而GPT格式突破了MBR的限制,它不再限制只能存储4个分区表条目,而是使用了类似MBR扩展分区表条目的格式,它允许有128个主分区,这也使得它可以对超过2TB的磁盘进行分区。
5.3.2 MBR和GPT分区表信息
在MBR格式分区表中,MBR扇区占用512个字节,前446个字节是主引导记录,即boot loader。中间64字节记录着分区表信息,每个主分区信息占用16字节,因此最多只能有4个主分区,最后2个字节是有效标识位。如果使用扩展分区,则扩展分区对应的16字节记录的是指向扩展分区中扩展分区表的指针。
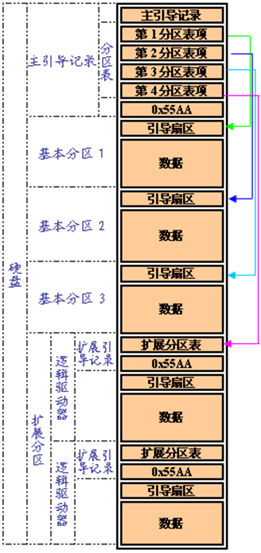
在MBR磁盘上,分区和启动信息是保存在一起的,如果这部分数据被覆盖或破坏,只能重建MBR。而GPT在整个磁盘上保存多个这部分信息的副本,因此它更为健壮,并可以恢复被破坏的这部分信息。GPT还为这些信息保存了循环冗余校验码(CRC)以保证其完整和正确,如果数据被破坏,GPT会发现这些破坏,并从磁盘上的其他地方进行恢复。
下面是GPT格式的分区表信息,大致约占17个字节。
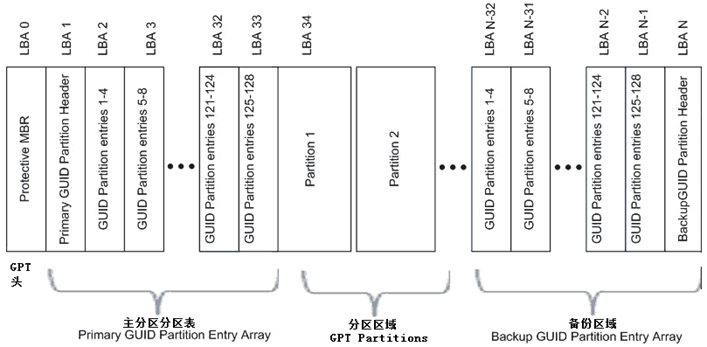
EFI部分可以分为4个区域:EFI信息区(GPT头)、分区表、GPT分区区域和备份区域。
- EFI信息区(GPT头):起始于磁盘的LBA1,通常也只占用这个单一扇区。其作用是定义分区表的位置和大小。GPT头还包含头和分区表的校验和,这样就可以及时发现错误。
- 分区表:分区表区域包含分区表项。这个区域由GPT头定义,一般占用磁盘LBA2~LBA33扇区,每扇区可存储4个主分区的分区信息,所以共能分128个主分区。分区表中的每个分区项由起始地址、结束地址、类型值、名字、属性标志、GUID值组成。分区表建立后,128位的GUID对系统来说是唯一的。
- GPT分区:最大的区域,由分配给分区的扇区组成。这个区域的起始和结束地址由GPT头定义。
- 备份区:备份区域位于磁盘的尾部,包含GPT头和分区表的备份。它占用GPT结束扇区和EFI结束扇区之间的33个扇区。其中最后一个扇区用来备份1号扇区的EFI信息,其余的32个扇区用来备份LBA2~LBA33扇区的分区表。
5.3.3 添加磁盘
正常情况下,添加磁盘后需要重启系统才能被内核识别,在/dev/下才有对应的设备号,使用fdisk -l才会显示出来。但是有时候不方便重启,所以下面介绍一种磁盘热插拔方式。更多热插和热拔方法见我的另一篇文章:Linux上磁盘热插拔。
[root@node1 ~]# ls /sys/class/scsi_host/ # 查看主机scsi总线号 host0 host1 host2
重新扫描scsi总线以热插拔方式添加新设备。
[root@node1 ~]# echo "- - -" > /sys/class/scsi_host/host0/scan [root@node1 ~]# echo "- - -" > /sys/class/scsi_host/host1/scan [root@node1 ~]# echo "- - -" > /sys/class/scsi_host/host2/scan [root@node1 ~]# fdisk -l # 再查看就有了
如果scsi_host目录系很多hostN目录,则使用循环来完成。
[root@xuexi scsi_host]# ls /sys/class/scsi_host/ host0 host11 host14 host17 host2 host22 host25 host28 host30 host4 host7 host1 host12 host15 host18 host20 host23 host26 host29 host31 host5 host8 host10 host13 host16 host19 host21 host24 host27 host3 host32 host6 host9 [root@xuexi scsi_host]# for i in /sys/class/scsi_host/host*/scan;do echo "- - -" >$i;done
5.3.4 使用fdisk分区工具
fdisk工具用来分MBR磁盘上的区。要分GPT磁盘上的区,可以使用gdisk。parted工具对这两种格式的磁盘分区都支持。
如果一个存储设备已经分过区,那么它可能是mbr格式的,也可能是gpt格式的,如果已经是mbr格式的,则只能继续使用fdisk进行分区,如果已经是gpt格式的,则只能使用gdisk进行分区。当然,无论什么格式的都可以使用parted进行分区,只不过也只能划分和已存在分区格式一样的分区,因为无论何种格式的分区,它的分区表和分区标识是已经固定的。
使用fdisk分区,它只能实现MBR格式的分区。
[root@xuexi ~]# fdisk /dev/sdb # sdb后没加数字 Command (m for help): m # 输入m查看可用命令帮助 Command action a toggle a bootable flag b edit bsd disklabel c toggle the dos compatibility flag d delete a partition # 删除分区,如果删除扩展分区同时会删除里面的逻辑分区 l list known partition types # 列出分区类型 m print this menu # 显示帮助信息 n add a new partition # 创建新分区 o create a new empty DOS partition table p print the partition table # 输出分区信息 q quit without saving changes # 不保存退出 s create a new empty Sun disklabel t change a partition's system id # 修改分区类型 u change display/entry units v verify the partition table w write table to disk and exit # 保存分区信息并退出 x extra functionality (experts only)
新建第一个主分区:
Command (m for help): n # 添加分区 Command action e extended # 添加扩展分区 p primary partition (1-4) # 添加主分区 p # 输入p来创建第一个主分区 Partition number (1-4): 1 # 输入分区号,从1开始 First cylinder (1-1305, default 1): # 输入柱面号,不输人默认是1 Using default value 1 Last cylinder, +cylinders or +size{K,M,G} (1-1305, default 1305): +2G # 给第一个主分区/dev/sdb1分2G,也可以使用柱面号来指定大小。 Command (m for help): p # 第一个分区结束,p查看下已分区信息 Disk /dev/sdb: 10.7 GB, 10737418240 bytes 255 heads, 63 sectors/track, 1305 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x2d8d64eb Device Boot Start End Blocks Id System /dev/sdb1 1 262 2104483+ 83 Linux
新建扩展分区:
Command (m for help): n # 再建一个分区 Command action e extended p primary partition (1-4) e # 创建扩展分区 Partition number (1-4): 2 # 扩展分区号为2 First cylinder (263-1305, default 263): Using default value 263 Last cylinder, +cylinders or +size{K,M,G} (263-1305, default 1305): # 剩余空间全部给扩展分区 Using default value 1305 Command (m for help): p Disk /dev/sdb: 10.7 GB, 10737418240 bytes 255 heads, 63 sectors/track, 1305 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x2d8d64eb Device Boot Start End Blocks Id System /dev/sdb1 1 262 2104483+ 83 Linux /dev/sdb2 263 1305 8377897+ 5 Extended
新建扩展分区:
Command (m for help): n # 新建逻辑分区 Command action l logical (5 or over) # 这里不再是扩展分区标识e,只有l。 # 如果已有3个主分区,这里连l都没有 p primary partition (1-4) l # 新建逻辑分区 First cylinder (263-1305, default 263): # 这里也不能选逻辑分区号了 Using default value 263 Last cylinder, +cylinders or +size{K,M,G} (263-1305, default 1305): +3G Command (m for help): p Disk /dev/sdb: 10.7 GB, 10737418240 bytes 255 heads, 63 sectors/track, 1305 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x2d8d64eb Device Boot Start End Blocks Id System /dev/sdb1 1 262 2104483+ 83 Linux /dev/sdb2 263 1305 8377897+ 5 Extended /dev/sdb5 263 655 3156741 83 Linux
分区结束,保存。如果不保存,则按q。
Command (m for help): w The partition table has been altered! Calling ioctl() to re-read partition table. Syncing disks.
分区的过程,实质上是划分柱面以及修改分区表。
上面的fdisk操作全部是在内存中执行的,必须保存生效。保存后,内核还未识别该分区,可以查看/proc/partition目录下存在的文件,这些文件是能被内核识别的分区。运行partprobe或partx命令重新读取分区表让内核识别新的分区,内核识别后才可以格式化。而且分区结束时按w保存分区表有时候会失败,提示重启,这时候运行partprobe命令可以代替重启就生效。
[root@xuexi ~]# partprobe # 执行partprobe,下面一堆信息,不理它 Warning: WARNING: the kernel failed to re-read the partition table on /dev/sda (Device or resource busy). As a result, it may not reflect all of your changes until after reboot. Warning: Unable to open /dev/sr0 read-write (Read-only file system). /dev/sr0 has been opened read-only. Warning: Unable to open /dev/sr0 read-write (Read-only file system). /dev/sr0 has been opened read-only. Error: Invalid partition table - recursive partition on /dev/sr0.
也可指定在/dev/sdb上重加载分区表,省的无法读取正忙的/dev/sda磁盘,给出上面一堆信息。
[root@xuexi ~]# partprobe /dev/sdb
分区之后再使用fdisk -l查看新的分区状态。
将上面分区所需要使用的命令总结如下,以后便于使用脚本分区。
- s fdisk /dev/sdb # 选择要分区的设备
- n # 创建分区
- p/e/l # 选择分区类型
如果主分区数有3个,且已经划分了扩展分区,再继续分区时将只能划分逻辑分区,这种情况下l选项会直接跳过进入下一个阶段。
- s N # 指定分区号
- \n # 指定起始柱面号,使用默认值就直接回车即换行
- +N # 指定分区大小为N
- w # 分区结束保存退出
- partprobe /dev/sdb &>/dev/null # 重读分区表
- fdisk -l | grep "^/dev/sdb" &>/dev/null # 检查分区状态
5.3.5 使用gdisk分区工具
gdisk用来划分gpt分区,需要单独安装这个工具包。
shell> yum -y install gdisk
分区的时候直接带上设备即可。以下是对新硬盘划分gpt分区的过程。
[root@xuexi ~]# gdisk /dev/sdb GPT fdisk (gdisk) version 0.8.10 Partition table scan: MBR: not present BSD: not present APM: not present GPT: not present Creating new GPT entries. Command (? for help): ? b back up GPT data to a file c change a partition's name d delete a partition # 删除分区 i show detailed information on a partition # 列出分区详细信息 l list known partition types # 列出所以已知的分区类型 n add a new partition # 添加新分区 o create a new empty GUID partition table (GPT) # 创建一个新的空的guid分区表 p print the partition table # 输出分区表信息 q quit without saving changes # 退出gdisk工具 r recovery and transformation options (experts only) s sort partitions t change a partition's type code # 修改分区类型 v verify disk w write table to disk and exit # 将分区信息写入到磁盘 x extra functionality (experts only) ? print this menu
添加一个新分区。
Command (? for help): n Partition number (1-128, default 1): First sector (34-41943006, default = 2048) or {+-}size{KMGTP}: Last sector (2048-41943006, default = 41943006) or {+-}size{KMGTP}: +10G Current type is 'Linux filesystem' Hex code or GUID (L to show codes, Enter = 8300): Changed type of partition to 'Linux filesystem' Command (? for help): p Disk /dev/sdb: 41943040 sectors, 20.0 GiB Logical sector size: 512 bytes Disk identifier (GUID): F8AE925F-515F-4807-92ED-4109D0827191 Partition table holds up to 128 entries First usable sector is 34, last usable sector is 41943006 Partitions will be aligned on 2048-sector boundaries Total free space is 20971453 sectors (10.0 GiB) Number Start (sector) End (sector) Size Code Name 1 2048 20973567 10.0 GiB 8300 Linux filesystem Command (? for help): i # 查看分区详细信息 Using 1 Partition GUID code: 0FC63DAF-8483-4772-8E79-3D69D8477DE4 (Linux filesystem) Partition unique GUID: B2452103-4F32-4B60-AEF7-4BA42B7BF089 First sector: 2048 (at 1024.0 KiB) Last sector: 20973567 (at 10.0 GiB) Partition size: 20971520 sectors (10.0 GiB) Attribute flags: 0000000000000000 Partition name: 'Linux filesystem'
保存分区表到磁盘。
Command (? for help): w Final checks complete. About to write GPT data. THIS WILL OVERWRITE EXISTING PARTITIONS!! Do you want to proceed? (Y/N): Y OK; writing new GUID partition table (GPT) to /dev/sdb. The operation has completed successfully.
执行partprobe重新读取分区表信息。
[root@server2 ~]# partprobe /dev/sdb
gdisk还有几个expert only的命令,其实没什么专家不专家可用的,咱们需要知道的是命令何时能用,它们的作用是什么?
在gdisk交互过程命令行下,按下x表示进入扩展功能模式,该模式下的功能大部分都和gpt分区表相关,在不是非常了解gpt分区表结构的时候不建议做修改动作,但是查看信息类是没问题的。以下是扩展功能模式下的命令。
Command (? for help): x Expert command (? for help): ? a set attributes c change partition GUID d display the sector alignment value e relocate backup data structures to the end of the disk g change disk GUID h recompute CHS values in protective/hybrid MBR i show detailed information on a partition l set the sector alignment value m return to main menu n create a new protective MBR o print protective MBR data p print the partition table q quit without saving changes r recovery and transformation options (experts only) s resize partition table # 修改分区表大小,注意不是分区大小 t transpose two partition table entries u Replicate partition table on new device # 将分区表导出 v verify disk w write table to disk and exit z zap (destroy) GPT data structures and exit # 损毁gpt上的数据 ? print this menu
5.3.6 使用parted分区工具
parted支持mbr格式和gpt格式的磁盘分区。它的强大在于可以一步到位而不需要不断的交互式输入(也可以交互式)。
parted分区工具是实时的,所以每一步操作都是直接写入磁盘而不是写进内存,它不像fdisk/gdisk还需要w命令将内存中的结果保存到磁盘中。
[root@xuexi ~]# parted /dev/sdc GNU Parted 2.1 Using /dev/sdc Welcome to GNU Parted! Type 'help' to view a list of commands. (parted) help align-check TYPE N check partition N for TYPE(min|opt) alignment check NUMBER do a simple check on the file system(centos 7上已删除该功能) cp [FROM-DEVICE] FROM-NUMBER TO-NUMBER copy file system to another partition(centos 7上已删除该功能) help [COMMAND] print general help, or help on COMMAND mklabel,mktable LABEL-TYPE create a new disklabel (partition table) mkfs NUMBER FS-TYPE make a FS-TYPE file system on partition NUMBER (centos 7上已删除改该功能) mkpart PART-TYPE [FS-TYPE] START END make a partition mkpartfs PART-TYPE FS-TYPE START END make a partition with a file system(centos 7上已删除该功能) move NUMBER START END move partition NUMBER(centos 7上已删除该功能) name NUMBER NAME name partition NUMBER as NAME print [devices|free|list,all|NUMBER] display the partition table,available devices,free space, all found partitions,or a particular partition quit exit program rescue START END rescue a lost partition near START and END resize NUMBER START END resize partition NUMBER and its file system(修改分区大小(centos 7上已删除该功能)) rm NUMBER delete partition NUMBER (删除分区) select DEVICE choose the device to edit (重选磁盘进入parted状态) set NUMBER FLAG STATE change the FLAG on partition NUMBER(设置分区状态,如将其off或on) toggle [NUMBER [FLAG]] toggle the state of FLAG on partition NUMBER(修改文件系统类型,如swap、lvm) unit UNIT set the default unit to UNIT(修改默认单位,kB/MB/GB等) version display the version number and copyright information of GNU Parted
常用的命令是mklabel/rm/print/mkpart/help/quit,至于parted中一些看上去很好的功能如mkfs/mkpartfs/resize等可能会损毁当前数据而不够安全,所以只要使用它的5个常用命令即可。
parted分区的前提是磁盘已经有分区表(partition table)或磁盘标签(disk label),否则将显示"unrecognised disk label",这是和fdisk/gdisk不同的地方,所以需要先使用mklabel创建标签或分区表,最常见的标签(分区表)为"msdos"和"gpt",其中msdos分区就是MBR格式的分区表,也就是会有主分区、扩展分区和逻辑分区的概念和限制。
下面使用parted对/dev/sdc创建msdos的新分区。
[root@xuexi ~]# parted /dev/sdc GNU Parted 2.1 Using /dev/sdb Welcome to GNU Parted! Type 'help' to view a list of commands. (parted) mklabel # 创建磁盘分区标签(分区表类型) New disk label type? msdos # 选择msdos即MBR类型 # 上面的两步也可以直接一步进行:(parted) mklabel msdos (parted) mkpart # 开始进行分区 Partition type? primary/extended? p # 创建主分区 File system type? [ext2]? ext4 # 创建ext4文件系统 # (注意,这里虽然指明了文件系统,但没有任何意义,后面还是需要手动格式化并选择文件系统类型) Start? 1 # 分区开始位置,默认是M为单位,表示从1M开始,也可直接指定1G这种方式 End? 1024 # 分区结束位置,1024-1=1023M (parted) p # print,查看分区信息 Model: VMware, VMware Virtual S (scsi) Disk /dev/sdc: 21.5GB Sector size (logical/physical): 512B/512B Partition Table: msdos Number Start End Size Type File system Flags 1 1049kB 1024MB 1023MB primary # 可以一步完成一个命令中的多个动作 (parted) mkpart p ext4 1026M 4096M # 可以一步完成,也可以一步完成到任何位置,然后继续交互下一步 # 可能会提示分区未对齐"Warning: The resulting partition is not properly aligned for best performance.",忽略它 (parted) mkpart e 4098 -1 # 创建扩展分区,注意创建扩展分区时不指定文件系统类型;-1表示剩余的全部分配给该分区 (parted) p Model: VMware, VMware Virtual S (scsi) Disk /dev/sdc: 21.5GB Sector size (logical/physical): 512B/512B Partition Table: msdos Number Start End Size Type File system Flags 1 1049kB 1024MB 1023MB primary 2 1026MB 4096MB 3070MB primary 3 4098MB 21.5GB 17.4GB extended lba (parted) mkpart l ext4 4099 8194 # 创建逻辑分区,指定ext4 (parted) mkpart l ext4 8195 -1 # 继续创建逻辑分区 (parted) p Model: VMware, VMware Virtual S (scsi) Disk /dev/sdc: 21.5GB Sector size (logical/physical): 512B/512B Partition Table: msdos Number Start End Size Type File system Flags 1 1049kB 1024MB 1023MB primary 2 1026MB 4096MB 3070MB primary 3 4098MB 21.5GB 17.4GB extended lba 5 4099MB 8194MB 4095MB logical 6 8195MB 21.5GB 13.3GB logical (parted) rm 5 # 删除5号分区 (parted) p Model: VMware, VMware Virtual S (scsi) Disk /dev/sdc: 21.5GB Sector size (logical/physical): 512B/512B Partition Table: msdos Number Start End Size Type File system Flags 1 1049kB 1024MB 1023MB primary 2 1026MB 4096MB 3070MB primary 3 4098MB 21.5GB 17.4GB extended lba 5 8195MB 21.5GB 13.3GB logical (parted) quit # 退出parted工具 Information: You may need to update /etc/fstab. # 提示你要更新/etc/fstab中的配置,说明该工具是可以在线分区的
mkfs和mkpartfs等命令不完善,下面的警告信息已经给出了提示。
(parted) mkfs 1 WARNING: you are attempting to use parted to operate on (mkfs) a file system. parted's file system manipulation code is not as robust as what you'll find in dedicated, file-system-specific packages like e2fsprogs. We recommend you use parted only to manipulate partition tables, whenever possible. Support for performing most operations on most types of file systems will be removed in an upcoming release. Warning: The existing file system will be destroyed and all data on the partition will be lost. Do you want to continue? parted: invalid token: 1 Yes/No? n
使用parted工具进行的分区无需运行partprobe重新读取分区表,内核会即时识别已经分区的分区信息。如下所示。
[root@xuexi tmp]# cat /proc/partitions | grep "sdc" 8 32 20971520 sdc 8 33 999424 sdc1 8 34 2998272 sdc2 8 35 1 sdc3 8 37 12967936 sdc5
一定要注意,虽然parted工具中指定了文件系统,但是并没有意义,它仍需要手动进行格式化并指定分区类型。实际上,在parted中文件系统是可以不用指定的,即使是非交互模式下也可以省略。
5.3.7 fdisk/gdisk以及parted非交互式操作分区
使用非交互分区时,最重要的是待分的区的起始点不能是已使用的。可以使用lsblk或fdisk -l或parted DEV print来判断将要从哪个地方开始分区。其实parted在非交互分区是最佳的工具,不仅是因为其书写方式简洁,而且待分区的起点如不合理它会自动提示是否要自动调整。
5.3.7.1 parted实现非交互
parted命令只能一次非交互一个命令中的所有动作。如下所示:
parted /dev/sdb mklabel msdos # 设置硬盘flag parted /dev/sdb mkpart primary ext4 1 1000 # Mbr格式分区,分别是partition type/fstype/start/end parted /dev/sdb mkpart 1 ext4 1M 10240M # gpt格式分区,分别是name/fstype/start/end parted /dev/sdb mkpart 1 10G 15G # 省略fstype的交互式分区 parted /dev/sdb rm 1 # 删除分区 parted /dev/sdb p # 输出信息
如果不确定分区的起点大小,可以加上-s选项使用script模式,该模式下parted将回答一切默认值,如yes、no。
shell> parted -s /dev/sdb mkpart 3 14G 16G Warning: You requested a partition from 14.0GB to 16.0GB. The closest location we can manage is 15.0GB to 16.0GB. Is this still acceptable to you? Information: You may need to update /etc/fstab.
5.3.7.2 fdisk实现非交互
fdisk实现非交互的原理是从标准输入中读取,每读取一行传递一次操作。
所以可以有两种方式:使用echo和管道传递;将操作写入到文件中,从文件中读取。
例如:下面的命令创建了两个分区。使用默认值时传递空行即可。
echo -e "n\np\n1\n\n+5G\nn\np\n2\n\n+1G\nw\n" | fdisk /dev/sdb
如果要传递的操作很多,则可以将它们写入到一个文件中,从文件中读取。
echo -e "n\np\n1\n\n+5G\nn\np\n2\n\n+1G\nw\n" >/tmp/a.txt fdisk /dev/sdb </tmp/a.txt
5.3.7.3 gdisk实现非交互
原理同fdisk。例如:
echo -e "n\n1\n\n+3G\n\nw\nY\n" | gdisk /dev/sdb
上面传递的各参数意义为:新建分区,分区number为1,使用默认开始扇区位置,分区大小+3G,使用默认分区类型,保存,确认。
5.4 格式化分区
分区结束后就需要格式化创建文件系统了,格式化分区的过程就是创建文件系统的过程。可以使用mkfs(make filesystem)工具进行格式化,也可以使用该工具家族的其他工具如mkfs.ext4/mkfs.xfs等专门针对文件系统的工具。
要查看支持的文件系统类型,只需简单的输入mkfs然后按两下tab键,就可以列出各文件系统对应的格式化命令,这些就是支持的文件系统类型。
CentOS 6上支持的:
[root@xuexi ~]# mkfs
mkfs mkfs.cramfs mkfs.ext2 mkfs.ext3 mkfs.ext4 mkfs.ext4dev mkfs.msdos mkfs.vfat
CentOS 7上支持的:
[root@server2 ~]# mkfs
mkfs mkfs.btrfs mkfs.cramfs mkfs.ext2 mkfs.ext3 mkfs.ext4 mkfs.fat mkfs.minix mkfs.msdos mkfs.vfat mkfs.xfs
5.4.1 mkfs工具
mkfs [-t fstype] 分区
该工具非常简单,它只需指定一个可选的"-t"选项指定要创建的文件系统类型,如果省略则默认创建ext2文件系统。该工具指定的"-t"选项其实是在调用对应文件系统专属的格式化工具。
5.4.2 mke2fs工具
mkfs.ext2/mkfs.ext3/mkfs.ext4或mkfs -t extX其实都是在调用mke2fs工具。
该工具创建文件系统时,会从/etc/mke2fs.conf配置中读取默认的配置项。
mke2fs [ -c ] [ -b block-size ] [ -f fragment-size ] [ -g blocks-per-group ] [ -G number-of-groups ]
[ -i bytes-per-inode ] [ -I inode-size ] [ -j ] [ -N number-of-inodes ] [ -m reserved-blocks-percentage ]
[ -q ] [ -r fs-revision-level ] [ -v ] [ -L volume-label ] [ -S ] [ -t fs-type ] device [ blocks-count ] 选项说明: -t fs-type :指定要创建的文件系统类型(ext2,ext3 ext4),若不指定,则从/etc/mke2fs.conf中获取默认的文件系统类型。 -b block-size :指定每个block的大小,有效值有1024、2048和4096,单位是字节。 -I inode-size :指定inode大小,单位为字节。必须为2的幂次方,且大于等于128字节。值越大,说明inode的集合体inode table占用越多的空 间,这不仅会挤占文件系统中的可用空间,还会降低性能,因为要扫描inode table需要消耗更多时间,但是在linux kernel 2.6.10 之后,由于使用inode存储了很多扩展的额外属性,所以128字节已经不够用了,因此ext4默认的inode size已经变为256,尽管 inode大小增大了,但因为使用inode存储扩展属性带来的性能提升远高于inode size变大导致的负面影响,所以仍建议使用256字 节的inode。 -i bytes-per-inode :指定每多少个字节就为其分配一个inode号。值越大,说明一个文件系统中分配的inode号越少,更适用于存储大量大文件,值越 小,inode号越多,更适用于存储大量小文件。该值不能小于一个block的大小,因为这样会造成inode多余。 注意,创建文件系统后该值就不能再改变了。 -c :创建文件系统前先检查设备是否有bad blocks。 -f fragment-size :指定fragments的大小,单位字节。 -g blocks-per-group:指定每个块组中的block数量。不建议修改此项。 -G number-of-groups:该选项用于ext4文件系统(严格地说是启用了flex_bg特性),指定虚拟块组(即一个extent)中包含的块组个数,必须为2的幂次方。 对于ext4文件系统来说,使用extent的功能能极大提升其性能。 -j :创建带有日志功能的文件系统,即ext3。如果要指定关于日志方面的设置,在-j的基础上再使用-J指定,不过一般默认即可,具体可 指定的选项看man文档。 -L new-volume-label:指定卷标名称,名称不得超出16字节。 -m reserved-blocks-percentage:指定文件系统保留block数量的比例,保留一部分block,可以降低物理碎片。默认比例为5%。 -N number-of-inodes :强制指定该文件系统应该分配多少个inode号,它会覆盖通过计算得出inode数量的结果(根据block大小、数量和每多少字节分配 一个inode得出Inode数量),但是不建议这么做。 -q :安静模式,可用于脚本中 -S :重建superblock和group descriptions。在所有的superblock和备份的superblock都损坏时有用。它会重新初始化superblock和 group descriptions,但不会改变inode table、bmap和imap(若真的改变,该分区数据就全丢了,还不如重新格式化)。在重建 superblock后,应该执行e2fsck来保证文件系统的一致性。但要注意,应该完全正确地指定block的大小,其改选项并不能完全保 证数据不丢失。 -v :输出详细执行过程
所以,有可能用到的选项也就"-t"指定文件系统类型,"-b"指定block大小,"-I"指定inode大小,"-i"指定分配inode的比例。
例如:
shell> mke2fs -t ext4 -I 256 /dev/sdb2 -b 4096 mke2fs 1.41.12 (17-May-2010) Filesystem label= OS type: Linux Block size=4096 (log=2) Fragment size=4096 (log=2) Stride=0 blocks, Stripe width=0 blocks 655360 inodes, 2621440 blocks 131072 blocks (5.00%) reserved for the super user First data block=0 Maximum filesystem blocks=2684354560 80 block groups 32768 blocks per group, 32768 fragments per group 8192 inodes per group Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632 Writing inode tables: done Creating journal (32768 blocks): done Writing superblocks and filesystem accounting information: done This filesystem will be automatically checked every 39 mounts or 180 days, whichever comes first. Use tune2fs -c or -i to override.
提示使用tune2fs修改自动检测文件系统的频率。见下文。
5.4.3 tune2fs修改ext文件系统属性
该工具其实没什么太大作用,文件系统创建好后很多属性是固定不能修改的,能修改的属性很有限,且都是无关紧要的。
但有些时候还是可以用到它做些事情,例如刚创建完ext文件系统后会提示修改自检时间。
tune2fs [ -c max-mount-counts ] [ -i interval-between-checks ] [ -j ] device -j:将ext2文件系统升级为ext3; -c:修改文件系统最多挂载多少次后进行自检,设置为0或-1将永不自检; -i:修改过了多少时间进行自检。时间单位可以指定为天(默认)/月/星期[d|m|w],设置为0将永不自检。
例如:tune2fs -i 0 /dev/sdb1
5.4.4 为实验而生:快速创建文件系统
有时候仅仅为了实验而插入新磁盘、扫描SCSI设备、再分区、格式化,整个过程挺麻烦的。
好在,有更为便捷的方式:
dd if=/dev/zero of=sdx bs=1M count=32 mke2fs sdx
现在sdx文件就是一个ext家族的文件系统了,相当于已经格式化的/dev/sdxN,它可以直接拿来挂载使用。
mount sdx /mnt/sdx
还可以使用mkisofs命令工具快速将目录创建成一个可挂载的镜像文件:
mkdir -p foo/bar/baz
mkisofs -o test.iso foo # 将foo打包成iso镜像
现在,test.iso镜像文件也可以直接挂载使用:
mount test.iso /mnt/test
5.5 查看文件系统状态信息
5.5.1 lsblk
lsblk(list block devices)用于列出设备及其状态,主要列出非空的存储设备。其实它只会列出/sys/dev/block中的主次设备号文件,且默认只列出非空设备。
[root@server2 ~]# lsblk
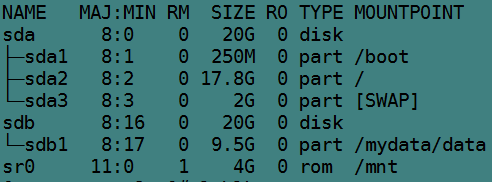
其中上面的几列意义如下:
NAME:设备名称;
MAJ:MIN:主设备号和此设备号;
RM:是否为可卸载设备,1表示可卸载设备。可卸载设备如光盘、USB等。并非能够umount的就是可卸载的;
SIZE:设备总空间大小;
RO:是否为只读;
TYPE:是磁盘disk,还是分区part,亦或是rom,还有loop设备;
mountpoint:挂载点。
[root@server2 ~]# lsblk /dev/sdb NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sdb 8:16 0 20G 0 disk ├─sdb1 8:17 0 9.5G 0 part /mydata/data └─sdb2 8:18 0 3G 0 part [root@server2 ~]# lsblk /dev/sdb1 NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sdb1 8:17 0 9.5G 0 part /mydata/data
另外常用的一个选项是"-f",它可以查看到文件系统类型,和文件系统的uuid和挂载点。
[root@xuexi ~]# lsblk -f NAME FSTYPE LABEL UUID MOUNTPOINT sda ├─sda1 ext4 77b5f0da-b0f9-4054-9902-c6cdacf29f5e /boot ├─sda2 ext4 f199fcb4-fb06-4bf5-a1b7-a15af0f7cb47 / └─sda3 swap 6ae3975c-1a2a-46e3-87f3-d5bd3f1eff48 [SWAP] sr0 sdb ├─sdb1 ext4 95e5b9d5-be78-43ed-a06a-97fd1de9a3fe ├─sdb2 ext2 45da2d94-190a-4548-85bb-b3c46ae6d9a7 └─sdb3
每个已经格式化的文件系统都有其类型和uuid,而没有格式化的设备(如/dev/sdb3),将只显示一个Name结果,表示该设备还未进行格式化。
5.5.2 blkid
虽然它有不少比较强大的功能,但一般只用它一个功能,就是查看器文件系统类型和uuid。
[root@xuexi ~]# blkid /dev/sda1: UUID="77b5f0da-b0f9-4054-9902-c6cdacf29f5e" TYPE="ext4" /dev/sda2: UUID="f199fcb4-fb06-4bf5-a1b7-a15af0f7cb47" TYPE="ext4" /dev/sda3: UUID="6ae3975c-1a2a-46e3-87f3-d5bd3f1eff48" TYPE="swap" /dev/sdb1: UUID="95e5b9d5-be78-43ed-a06a-97fd1de9a3fe" TYPE="ext4" /dev/sdb2: UUID="45da2d94-190a-4548-85bb-b3c46ae6d9a7" TYPE="ext2" [root@xuexi ~]# blkid /dev/sdb1 /dev/sdb1: UUID="95e5b9d5-be78-43ed-a06a-97fd1de9a3fe" TYPE="ext4"
5.5.3 parted /dev/sda print和fdisk -l
shell> parted /dev/sdb p Model: VMware, VMware Virtual S (scsi) Disk /dev/sdb: 21.5GB Sector size (logical/physical): 512B/512B Partition Table: gpt Disk Flags: Number Start End Size File system Name Flags 1 1049kB 10.2GB 10.2GB ext4 2 10.2GB 13.5GB 3221MB ext2 Linux filesystem
shell> fdisk -l /dev/sda Disk /dev/sda: 21.5 GB, 21474836480 bytes, 41943040 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk label type: dos Disk identifier: 0x000cb657 Device Boot Start End Blocks Id System /dev/sda1 * 2048 514047 256000 83 Linux /dev/sda2 514048 37847039 18666496 83 Linux /dev/sda3 37847040 41943039 2048000 82 Linux swap / Solaris
虽然fdisk和gdisk分别是mbr和gpt格式的专用工具,但是仅用于查看信息还是可以的。parted能兼容两者,所以也可以。
5.5.4 file -s
[root@xuexi ~]# file -s /dev/sdb2 /dev/sdb2: Linux rev 1.0 ext2 filesystem data (large files)
5.5.5 du
du命令用于评估文件的空间占用情况,它会统计每个文件的大小,统计时会递归统计目录中的文件,也就是说,它会遍历整个待统计目录,所以统计速度上可能并不理想。
du [OPTION]... [FILE]... 选项说明: -a, --all:列出目录中所有文件的统计信息,默认只会列出目录中子目录的统计信息,而不列出文件的统计信息 -h, --human-readable:人性化显示大小 -0, --null:以空字符结尾,即"\0"而非换行的"\n" -S, --separate-dirs:不包含子目录的大小 -s, --summarize:对目录做总的统计,不列出目录内文件的大小信息 -c,--total:对给出的文件或目录做总计。在统计非同一个目录文件大小时非常有用。见下文例子。 -d,--max-depth:指定显示时的目录深度,默认会递归显示所有层次
--max-depth=N:只列出给定层次的目录统计,如果N=0,则等价于"-s" -x, --one-file-system:忽略不同文件系统上的文件,不对它们进行统计 -X, --exclude-from=FILE:从文件中读取要排除的文件 --exclude=PATTERN:指定要忽略不统计的文件
注意:
(1).上面的选项中,有些是不列出某些项,有些是不统计某些项,它们是不一样的。
(2).如果要统计的目录下挂载了一个文件系统,那么这个文件系统的大小也会被计入该目录的大小中。
[root@xuexi ~]# du -sh /etc 29M /etc
[root@xuexi ~]# du -ah /tmp 4.0K /tmp/b.txt 4.0K /tmp/a 4.0K /tmp/.ICE-unix 4.0K /tmp/testdir/subdir 0 /tmp/testdir/a.log 8.0K /tmp/testdir 24K /tmp
[root@xuexi ~]# du -h --max-depth=1 /usr 15M /usr/include 383M /usr/lib64 132K /usr/local 391M /usr/share 4.0K /usr/etc 118M /usr/lib 44M /usr/libexec 49M /usr/src 32M /usr/sbin 4.0K /usr/games 75M /usr/bin 1.1G /usr
[root@xuexi ~]# du -h --max-depth=1 --exclude=/usr/lib64 /usr 15M /usr/include 132K /usr/local 391M /usr/share 4.0K /usr/etc 118M /usr/lib 44M /usr/libexec 49M /usr/src 32M /usr/sbin 4.0K /usr/games 75M /usr/bin 721M /usr
# 统计家目录下除隐藏文件外的各文件、目录大小 [root@xuexi ~]# du -h --max-depth=1 --exclude=".*" ~ # 统计家目录下大于1M的文件 [root@xuexi ~]# du -h --max-depth=1 -t 1M ~
搜索符合条件的文件,然后统计它们的总大小。结合find使用,效果极佳。
[root@xuexi ~]# find /boot/ -type f -name "*.img" -print0 | xargs -0 du -ch 28K /boot/grub2/i386-pc/core.img 4.0K /boot/grub2/i386-pc/boot.img 592K /boot/initrd-plymouth.img 44M /boot/initramfs-0-rescue-d13bce5e247540a5b5886f2bf8aabb35.img 17M /boot/initramfs-3.10.0-327.el7.x86_64.img 16M /boot/initramfs-3.10.0-327.el7.x86_64kdump.img 76M total
请注意"-c"和"-s"统计的区别。
[root@xuexi ~]# find /boot/ -type f -name "*.img" -print0 | xargs -0 du -sh 28K /boot/grub2/i386-pc/core.img 4.0K /boot/grub2/i386-pc/boot.img 592K /boot/initrd-plymouth.img 44M /boot/initramfs-0-rescue-d13bce5e247540a5b5886f2bf8aabb35.img 17M /boot/initramfs-3.10.0-327.el7.x86_64.img 16M /boot/initramfs-3.10.0-327.el7.x86_64kdump.img
5.5.6 df
df用于报告磁盘空间使用率,默认显示的大小是1K大小block数量,也就是以k为单位。
和du不同的是,df是读取每个文件系统的superblock信息,所以评估速度非常快。由于是读取superblock,所以如果目录下挂载了另一个文件系统,是不会将此挂载的文件系统计入目录大小的。注意,du和df统计的结果是不一样的,如果对它们的结果不同有兴趣,可参考我的另一篇文章:详细分析du和df的统计结果为什么不一样。
如果用df统计某个文件的空间使用情况,将会转而统计该文件所在文件系统的空间使用情况。
df [OPTION]... [FILE]... 选项说明: -h:人性化转换大小的显示单位 -i:统计inode使用情况而非空间使用情况 -l, --local:只列出本地文件系统的使用情况,不列出网络文件系统信息 -T, --print-type:同时输出文件系统类型 -t, --type=TYPE:只列出给定文件系统的统计信息 -x, --exclude-type=TYPE:指定不显示的文件系统类型的统计信息
示例:
[root@server2 ~]# df -hT Filesystem Type Size Used Avail Use% Mounted on /dev/sda2 xfs 18G 2.3G 16G 13% / devtmpfs devtmpfs 904M 0 904M 0% /dev tmpfs tmpfs 913M 0 913M 0% /dev/shm tmpfs tmpfs 913M 8.6M 904M 1% /run tmpfs tmpfs 913M 0 913M 0% /sys/fs/cgroup /dev/sda1 xfs 247M 110M 137M 45% /boot tmpfs tmpfs 183M 0 183M 0% /run/user/0 /dev/sdb1 ext4 9.3G 37M 8.8G 1% /mydata/data
[root@server2 ~]# df -i Filesystem Inodes IUsed IFree IUse% Mounted on /dev/sda2 18666496 106474 18560022 1% / devtmpfs 231218 388 230830 1% /dev tmpfs 233586 1 233585 1% /dev/shm tmpfs 233586 479 233107 1% /run tmpfs 233586 13 233573 1% /sys/fs/cgroup /dev/sda1 256000 330 255670 1% /boot tmpfs 233586 1 233585 1% /run/user/0 /dev/sdb1 625856 14 625842 1% /mydata/data
5.5.7 dumpe2fs
用于查看ext类文件系统的superblock及块组信息。使用-h选项将只显示superblock信息。
以下是ext4文件系统superblock的信息。
[root@xuexi ~]# dumpe2fs -h /dev/sda2 dumpe2fs 1.41.12 (17-May-2010) Filesystem volume name: <none> Last mounted on: / Filesystem UUID: f199fcb4-fb06-4bf5-a1b7-a15af0f7cb47 Filesystem magic number: 0xEF53 Filesystem revision #: 1 (dynamic) Filesystem featurs: has_journal ext_attr resize_inode dir_index filetype needs_recovery exent flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize Filesystem flags: signed_directory_hash Default mount options: user_xattr acl Filesystem state: clean Errors behavior: Continue Filesystem OS type: Linux Inode count: 1166880 Block count: 4666624 Reserved block count: 233331 Free blocks: 4196335 Free inodes: 1111754 First block: 0 Block size: 4096 Fragment size: 4096 Reserved GDT blocks: 1022 Blocks per group: 32768 Fragments per group: 32768 Inodes per group: 8160 Inode blocks per group: 510 Flex block group size: 16 Filesystem created: Sat Feb 25 11:48:47 2017 Last mount time: Tue Jun 6 18:13:10 2017 Last write time: Sat Feb 25 11:53:49 2017 Mount count: 6 Maximum mount count: -1 Last checked: Sat Feb 25 11:48:47 2017 Check interval: 0 (<none>) Lifetime writes: 2657 MB Reserved blocks uid: 0 (user root) Reserved blocks gid: 0 (group root) First inode: 11 Inode size: 256 Required extra isize: 28 Desired extra isize: 28 Journal inode: 8 Default directory hash: half_md4 Directory Hash Seed: d4e6493a-09ef-41a1-9d66-4020922f1aa9 Journal backup: inode blocks Journal features: journal_incompat_revoke Journal size: 128M Journal length: 32768 Journal sequence: 0x00001bd9 Journal start: 23358
其中一个块组信息。
[root@xuexi ~]# dumpe2fs /dev/sda2 | tail -7 dumpe2fs 1.41.12 (17-May-2010) Group 142: (Blocks 4653056-4666623) [INODE_UNINIT, ITABLE_ZEROED] Checksum 0x64ce, unused inodes 8160 Block bitmap at 4194318 (+4294508558), Inode bitmap at 4194334 (+4294508574) Inode table at 4201476-4201985 (+4294515716) 13568 free blocks, 8160 free inodes, 0 directories, 8160 unused inodes Free blocks: 4653056-4666623 Free inodes: 1158721-1166880
5.6 挂载和卸载文件系统
在此,只简单介绍mount和umount的用法,至于实现挂载和卸载的机制和原理细节,参看挂载文件系统的细节。
5.6.1 mount
mount用来显示挂载信息或者进行文件系统挂载,它的功能及其的强大(强大到离谱),它不仅支持挂载非常多种文件系统,如ext/xfs/nfs/smbfs/cifs (win上的共享目录)等,还支持共享挂载点、继承挂载点(父子关系)、绑定挂载点、移动挂载点等等功能。在本文只介绍其最简单的挂载功能。
不同的文件系统挂载选项是有所差别的,在挂载过程中如果出错,应该man mount并查看对应文件系统的挂载选项。
mount并非只能挂载文件系统,也可以将目录挂载到另一个目录下,其实它实现的是目录"硬链接",默认情况下,是无法对目录建立硬链接的,但是通过mount可以完成绑定,绑定后两个目录的inode号是完全相同的,但尽管建立的是目录的"硬链接",但其实也仅是拿来当软链接用。
以下是ext类文件系统的选项,可能有些选项是不支持其他文件系统的。
mount # 将显示当前已挂载信息 mount [-t 欲挂载文件系统类型 ] [-o 特殊选项] 设备名 挂载目录
选项说明: -a 将/etc/fstab文件里指定的挂载选项重新挂载一遍。 -t 支持ext2/ext3/ext4/vfat/fat/iso9660(光盘默认格式)。 不用-t时默认会调用blkid来获取文件系统类型。 -n 不把挂载记录写在/etc/mtab文件中,一般挂载会在/proc/mounts中记录下挂载信息,然后同步到/etc/mtab,指定-n表示不同步该挂载信息。 -o 指定挂载特殊选项。下面是两个比较常用的: loop 挂载镜像文件,如iso文件 ro 只读挂载 rw 读写挂载 auto 相当于mount -a dev 如果挂载的文件系统中有设备访问入口则启用它,使其可以作为设备访问入口 default rw,suid,dev,exec,auto,nouser,async,and relatime async 异步挂载,只写到内存 sync 同步挂载,通过挂载位置写入对方硬盘 atime 修改访问时间,每次访问都修改atime会导致性能降低,所以默认是noatime noatime 不修改访问时间,高并发时使用这个选项可以减少磁盘IO nodiratime 不修改文件夹访问时间,高并发时使用这个选项可以减少磁盘IO exec/noexec 挂载后的文件系统里的可执行程序是否可执行,默认是可以执行exec, 优先级高于权限的限定 remount 重新挂载,此时可以不用指定挂载点。 suid/nosuid 对挂载的文件系统启用或禁用suid,对于外来设备最好禁用suid _netdev 需要网络挂载时默认将停留在挂载界面直到加载网络了。使用_netdev可以忽略网络正常挂载。如NFS开机挂载。 user 允许普通用户进行挂载该目录,但只允许挂载者进行卸载该目录 users 允许所有用户挂载和卸载该目录 nouser 禁止普通用户挂载和卸载该目录,这是默认的,默认情况下一个目录不指定user/users时,将只有root能挂载
一般user/users/nouser都用在/etc/fstab中,直接在命令行下使用这几个选项意义不是很大。
例如:
(1).挂载CentOS的安装镜像到/mnt。
mount /dev/cdrom /mnt
其实/dev/cdrom是/dev/sr0的一个软链接,/dev/sr0是光驱设备,所以也可以用/dev/sr0进行挂载。
mount /dev/sr0 /mnt
(2).重新挂载。
[root@xuexi ~]# mount -t ext4 -o remount /dev/sdb1 /data1
(3).重新挂载文件系统为可读写。
mount -t ext4 -o rw remount /dev/sdb1 /data1
(4).挂载windows的共享目录。
win上共享文件的文件系统是cifs类型,要在Linux上挂载,必须得有mount.cifs命令,如果没有则安装cifs-utils包。
假设win上共享目录的unc路径为\\192.168.100.8\test,共享给的用户名和密码分别为long3:123,要挂在linux上的/mydata目录上。
shell> mount.cifs -o username="long3",password="123" //192.168.100.8/test /mydata
注意,如果是比较新版本的win10(2017年之后更新的版本)或较新版本的win server,直接mount.cifs会报错:
[root@xuexi ~]# mount.cifs -o username="long3",password="123" //192.168.100.8/test /mnt mount error(112): Host is down Refer to the mount.cifs(8) manual page (e.g. man mount.cifs)
这是因为2017年微软的一个补丁禁用了SMBv1协议,通过smbclient的报告可知:
[root@xuexi ~]# yum -y install samba-client [root@xuexi ~]# smbclient -L //192.168.100.8 Enter root's password: protocol negotiation failed: NT_STATUS_CONNECTION_RESET
因此,在mount的时候指定cifs(SMB)的版本号为2.0即可。
[root@xuexi ~]# mount.cifs -o username="long3",password="123",vers=2.0 //192.168.100.8/test /mnt
但是需要注意,在CentOS 4,5,6下的模块cifs.ko版本(较低)只能使用SMBv1协议,因此即使指定版本号也一样无效。只有在CentOS 7上才能使用SMBv2或SMBv3。
(5).基于ssh挂载远程目录。
如何基于ssh像NFS一样挂载远程主机上的目录?可以通过sshfs工具,该工具在fuse-sshfs包中,这个包在epel源中提供。
yum -y install fuse-sshfs
例如,挂载192.168.100.8上的根目录到本地的/mnt上。
sshfs 192.168.100.8:/ /mnt
卸载时直接umount即可。
关于sshfs,详细内容见:https://www.cnblogs.com/f-ck-need-u/p/9104950.html
(6).挂载目录到另一个目录下。挂载目录时,挂载目录和挂载点的inode是相同的,它们两者的内容也是完全相同的。
mount --bind /mydata /mnt
(7).查看某个目录是否是挂载点,使用mountpoint命令。
[root@xuexi ~]# mountpoint /mydata/ /mydata/ is a mountpoint [root@xuexi ~]# echo $? 0 [root@xuexi ~]# mountpoint /mnt /mnt is not a mountpoint [root@xuexi ~]# echo $? 1
挂载的参数信息存放在/proc/mounts(是/proc/self/mounts的软链接)中,在/proc/self/mountstats和/proc/mountinfo里则记录了更详细的挂载信息。
[root@xuexi ~]# cat /proc/mounts rootfs / rootfs rw 0 0 proc /proc proc rw,relatime 0 0 sysfs /sys sysfs rw,relatime 0 0 devtmpfs /dev devtmpfs rw,relatime,size=491000k,nr_inodes=122750,mode=755 0 0 devpts /dev/pts devpts rw,relatime,gid=5,mode=620,ptmxmode=000 0 0 tmpfs /dev/shm tmpfs rw,relatime 0 0 /dev/sda2 / ext4 rw,relatime,barrier=1,data=ordered 0 0 /proc/bus/usb /proc/bus/usb usbfs rw,relatime 0 0 /dev/sda1 /boot ext4 rw,relatime,barrier=1,data=ordered 0 0 none /proc/sys/fs/binfmt_misc binfmt_misc rw,relatime 0 0
文件系统是需要驱动支持的,没有驱动的文件系统也无法挂载,Linux中支持的文件系统驱动在/lib/modules/$(uname -r)/kernel/fs下。
[root@xuexi ~]# ls /lib/modules/$(uname -r)/kernel/fs/ autofs4 cachefiles configfs dlm exportfs ext3 fat fuse jbd jffs2 mbcache.ko nfs_common nls ubifs xfs btrfs cifs cramfs ecryptfs ext2 ext4 fscache gfs2 jbd2 lockd nfs nfsd squashfs udf
5.6.2 直接挂载镜像文件
有时候需要挂载CentOS的镜像文件,在虚拟机中经常是将镜像放入虚拟机的CD/DVD虚拟光驱中,然后在Linux上对/dev/cdrom进行挂载。其实/dev/cdrom是/dev/sr0的一个软链接,/dev/sr0是Linux中的光驱,所以上面的过程相当于是将镜像文件通过虚拟软件的虚拟光驱和linux的光驱连接起来,这样只需要挂载Linux中的光驱就可以了。但是,在非虚拟环境中没有虚拟光驱,而且在Linux中的一个镜像文件难道一定要拷贝到主机上通过虚拟光驱进行连接吗?
mount是一个极其强大的挂载工具,它支持挂载很多种文件类型,其中就支持挂载镜像文件,其实它连挂载目录都支持。
mount -o loop CentOS-6.6-x86_64-bin-DVD2.iso /mnt [root@xuexi ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT loop0 7:0 0 1.2G 0 loop /mnt sda 8:0 0 20G 0 disk ├─sda1 8:1 0 250M 0 part /boot ├─sda2 8:2 0 17.8G 0 part / └─sda3 8:3 0 2G 0 part [SWAP] sr0 11:0 1 1024M 0 rom
5.6.3 umount
umount 设备名或挂载目录 umount -lf 强制卸载
卸载时,既可以使用设备名也可以使用挂载点卸载。有时候挂载网络系统(如NFS)时,设备名很长,这时候可以使用挂载点来卸载就方便多了。
如果用户正在访问某个目录或文件,使得卸载一直显示Busy,使用fuser -v DIR可以知道谁正在访问该目录或文件。
[root@xuexi ~]# fuser -v /root USER PID ACCESS COMMAND /root: root 37453 ..c.. bash
使用-k选项kill掉正在使用目录或文件的进程,使用-km选项kill掉文件系统上的所有进程,然后再umount。
[root@xuexi ~]# fuser -km /mnt/cdrom;umount /mnt/cdrom
5.6.4 开机自动挂载/etc/fstab
通过将挂载选项写入到/etc/fstab中,系统会自动挂载该文件中的配置项。但要注意,该文件在开机的前几个过程中就被读取,所以配置错误很可能会导致开机失败。

其中最后两列,它们分别表示备份文件系统和开机自检,一般都可以设置为0。
由于能用的备份工具众多,没人会在这里设置备份,所以备份列设置为0。
最后一列是开机自检设置列,开机自检调用的是fsck程序,所有有些ext类文件系统作为"/"时,可能会设置为1,但是fsck是不支持xfs文件系统的,所以对于xfs文件系统而言,该项必须设置为0。
其实无需考虑那么多,直接将这两列设置为0就可以了。
5.6.5 修复错误的/etc/fstab
万一/etc/fstab配置错误,导致开机无法加载。这时提示输入root密码进入单人维护模式,只不过担任模式下根文件系统是只读的,哪怕是root也无法直接修改/etc/fstab,所以应该将"/"文件系统进行重新挂载。
执行下面的命令,重挂载根分区,并给读写权限,再去修改错误的fstab文件记录,再重启。
[root@xuexi ~]# mount -n -o remount,rw /
5.6.7 按需自动挂载(autofs)
使用autofs实现需要挂载时就挂载,不需要挂载时5分钟后自动卸载。但是在实际环境中基本不会使用按需挂载。
autofs是一个服务程序,需要让其运行在后台,可以用来挂NFS,也可挂本地的文件系统。
默认不装autofs,需要自己装。
[root@xuexi ~]# yum install -y autofs
autofs实现按需挂载的方式是指定监控目录,可在其配置文件/etc/auto.master中指定。
/etc/auto.master里面只有两列:第一列是监控目录;第二列是记录挂载选项的文件,该文件可以随便取名。
[root@xuexi ~]# cat /etc/auto.master /share /etc/auto.mount # 监控/share目录,使用/etc/auto.nfs记录挂载选项
上述监控的/share目录,其实这是监控的父目录,在此目录下的目录如/share/data目录可以作为挂载点,当访问到/share/data时就被监控到,然后会按照挂载选项将挂载设备挂载到/share/data上。
上述配置中配置的挂载选项文件是/etc/auto.mount,所以建立此文件,写入挂载选项。
[root@xuexi ~]# cat /etc/auto.mount #cd -fstype=iso9660,ro,nosuid,nodev :/dev/cdrom # the following entries are samples to pique your imagination #linux -ro,soft,intr ftp.example.org:/pub/linux #boot -fstype=ext2 :/dev/hda1 #floppy -fstype=auto :/dev/fd0 #floppy -fstype=ext2 :/dev/fd0 #e2floppy -fstype=ext2 :/dev/fd0 #jaz -fstype=ext2 :/dev/sdc1 #removable -fstype=ext2 :/dev/hdd
该文件有3列:
第一列指定的是在/etc/auto.master指定的/share下的目录/share/data,它是真正的被监控路径,也是挂载点。可使用相对路径data表示/share/data。
第二列是mount的选项,前面使用一个"-"表示,该列可有可无。
第三列是待挂载设备,可以是NFS服务端的共享目录,也可以本地设备。
[root@xuexi ~]# vim /etc/auto.mount data -rw,bg,soft,rsize=32768,wsize=32768 192.168.100.61:/data
上面的配置表示当访问到/share/data时,自动使用参数(rw,bg,soft,rsize=32768,wsize=32768)挂载远端192.168.100.61的/data目录到/share/data上。
剩下的步骤就是启动autofs服务。
[root@xuexi data]# /etc/init.d/autofs restart
5.7 swap分区
虽说个人电脑上基本已经无需设置swap分区了,但是在服务器上还是应该准备swap分区,以做到有备无患和防止众多"玄学"问题。
5.7.1 查看swap使用情况
[root@xuexi ~]# free total used free shared buffers cached Mem: 1906488 349376 1557112 200 16920 200200 -/+ buffers/cache: 132256 1774232 Swap: 2097148 0 2097148 [root@xuexi ~]# free -m # 以MB显示 total used free shared buffers cached Mem: 1861 341 1520 0 16 195 -/+ buffers/cache: 129 1732 # 这个是真正的可用内存空间 Swap: 2047 0 2047 # 这个是swap空间,发现一点都没被用
使用mount/lsblk等可以查看出哪个分区在充当swap分区。使用swapon -s也可以直接查看出。
[root@server2 ~]# swapon -s Filename Type Size Used Priority /dev/sda3 partition 2047996 37064 -1
5.7.2 添加swap分区
(1).可以新分一个区,在分区时指定其分区的ID号为SWAP类型。
mbr和gpt格式的磁盘上这个ID可能不太一样,不过一般gpt中的格式是在mbr格式的ID后加上两位数的数值,如mbr中swap的类型ID为82,在gpt中则是8200,在mbr中linux filesystem类型的ID为83,在gpt中则为8300,在mbr中lvm的ID为8e,在gpt中为8e00。
(2).格式化为swap分区:mkswap
[root@xuexi ~]# mkswap /dev/sdb5 Setting up swapspace version 1, size = 1951096 KiB no label, UUID=02e5af44-2a16-479d-b689-4e100af6adf5
(3).加入swap分区空间(swapon):
[root@xuexi ~]# swapon /dev/sdb5 [root@xuexi ~]# free -m total used free shared buffers cached Mem: 1861 343 1517 0 16 196 -/+ buffers/cache: 131 1730 Swap: 3953 0 3953
(4).取消swap分区空间(swapoff):
[root@xuexi ~]# swapoff /dev/sdb5 [root@xuexi ~]# free -m total used free shared buffers cached Mem: 1861 343 1518 0 16 196 -/+ buffers/cache: 130 1731 Swap: 0 0 0
(5).开机自动加载swap分区:
修改/etc/fstab,加上一行。
/dev/sda3 swap swap defaults 0 0
Linux系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
Shell系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
网站架构系列文章:http://www.cnblogs.com/f-ck-need-u/p/7576137.html
MySQL/MariaDB系列文章:https://www.cnblogs.com/f-ck-need-u/p/7586194.html
Perl系列:https://www.cnblogs.com/f-ck-need-u/p/9512185.html
Go系列:https://www.cnblogs.com/f-ck-need-u/p/9832538.html
Python系列:https://www.cnblogs.com/f-ck-need-u/p/9832640.html
Ruby系列:https://www.cnblogs.com/f-ck-need-u/p/10805545.html
操作系统系列:https://www.cnblogs.com/f-ck-need-u/p/10481466.html
精通awk系列:https://www.cnblogs.com/f-ck-need-u/p/12688355.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号