论文阅读:VLM4VLA
 Daily Paper Day 2
Daily Paper Day 2
(2026-01-06) VLM4VLA: Revisiting vision-language-models in vision-language-action models
Author: Jianke Zhang; Xiaoyu Chen; Qiuyue Wang; Mingsheng Li; Yanjiang Guo; Yucheng Hu; Jiajun Zhang; Shuai Bai; Junyang Lin; Jianyu Chen; |
Journal: , 2026. |
Journal Tags: |
Local Link: Zhang 等 - 2026 - VLM4VLA Revisiting vision-language-models in vision-language-action models.pdf |
Abstract: Vision-Language-Action (VLA) models, which integrate pretrained large VisionLanguage Models (VLMs) into their policy backbone, are gaining significant attention for their promising generalization capabilities. This paper revisits a fundamental yet seldom systematically studied question: how VLM choice and competence translate to downstream VLA policies performance? We introduce VLM4VLA, a minimal adaptation pipeline that converts general-purpose VLMs into VLA policies using only a small set of new learnable parameters for fair and efficient comparison. Despite its simplicity, VLM4VLA proves surprisingly competitive with more sophisticated network designs. Through extensive empirical studies on various downstream tasks across three benchmarks, we find that while VLM initialization offers a consistent benefit over training from scratch, a VLM’s general capabilities are poor predictors of its downstream task performance. This challenges common assumptions, indicating that standard VLM competence is necessary but insufficient for effective embodied control. We further investigate the impact of specific embodied capabilities by fine-tuning VLMs on seven auxiliary embodied tasks (e.g., embodied QA, visual pointing, depth estimation). Contrary to intuition, improving a VLM’s performance on specific embodied skills does not guarantee better downstream control performance. Finally, modality-level ablations identify the visual module in VLM, rather than the language component, as the primary performance bottleneck. We demonstrate that injecting control-relevant supervision into the vision encoder of the VLM yields consistent gains, even when the encoder remains frozen during downstream fine-tuning. This isolates a persistent domain gap between current VLM pretraining objectives and the requirements of embodied action-planning. |
Tags: |
Note Date: 2026/1/29 11:33:36 |
📜 Research Core
Tips: What was done, what problem was solved, innovations and shortcomings?
⚙️ Content
-
VLM初始化比从头训练有持续优势,但VLM的通用能力(如VQA基准)不能有效预测下游任务性能。
-
在具体具身任务上微调VLM(如具身QA、深度估计)不会改善下游控制性能。
-
模态级分析表明,视觉编码器是性能瓶颈,注入控制相关监督能提升效果,即使编码器在微调时冻结。
💡 Innovations
-
最小化适配管道:VLM4VLA引入仅<1%新参数,使用简单MLP头和L1/L2损失,避免扩散模型的随机性,实现公平VLM比较。
-
系统性评估维度:从通用能力、具身特定能力和模态级分析三个角度全面测试VLM对VLA的影响。
-
视觉差距分析:通过实验验证视觉编码器需微调的根本原因(语义鸿沟而非仅模拟-真实差距)。
🧩 Shortcomings
-
未在物理机器人上实验:限于仿真环境,因硬件公平性和可复现性挑战。但文档指出视觉差距问题在真实世界中同样存在。
-
实验范围限制:主要评估1B-10B参数VLM,超大模型覆盖不足;辅助任务类型可能未涵盖所有具身技能。
🔁 Research Content
💧 Data
👩🏻💻 Method
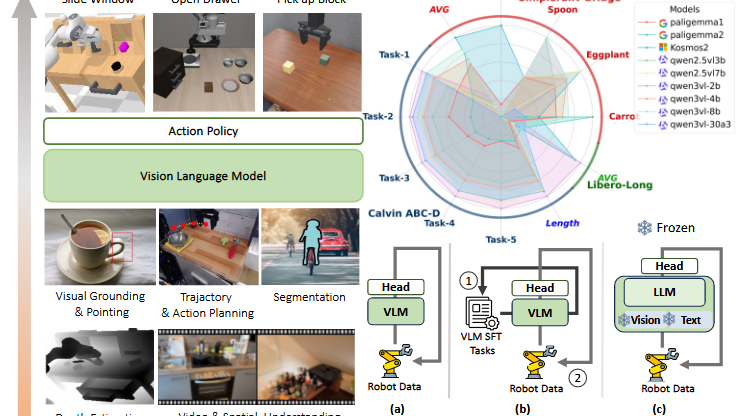
VLM4VLA框架:将VLM封装为VLA,通过可学习ActionQuery令牌提取具身知识,由MLP头解码动作块。公式:action = MLP(VLM([视觉嵌入, 文本嵌入, ActionQuery]))。
训练目标:使用Huber损失(位置)和二元交叉熵损失(状态),避免扩散损失的不稳定性。
公平设置:统一超参数(批量大小、学习率)、提示格式适配各VLM预训练风格。
🔬 Experiment
实验设计围绕3个标准:
-
公平性、可复现性——使用相同架构、相同的训练设置
-
最小化设计——将VLM封装在一个简单有效的VLA框架中
-
隔离VLM核心能力——仅使用视觉-语言输入,排除本体感觉
不同 VLMS 在 VLM4VLA 上的表现如下:
-
基线模型:
-
VLM基线:包括Qwen系列(通用型)、Paligemma(适配性)、Kosmos( grounding专注),规模1B-30B。
-
VLA基线:OpenVLA(离散动作)、pi0(基于Paligemma)、ThinkAct(使用状态信息)。
-
-
主要结果:
-
Calvin ABC-D:Qwen系列表现最佳,如Qwen2.5VL-7B完成4.057个任务(表1)。VLM预训练至关重要(附录A.2.5显示从头训练性能崩溃)。
-
SimplerEnv Bridge和Libero-10:Kosmos-2在Simpler上成功率最高(60.4%),Paligemma系列优于Qwen(表2)。性能与VLM通用能力相关性低。
-
-
相关性分析:Calvin任务与VQA基准高度相关(r=0.839),但Simpler和Libero无显著相关性(图3),表明VLA需求超越当前VLM能力。
辅助任务对VLA性能的影响:
-
测试任务:包括Robopoint(指向任务)、Vica-332k(空间理解)、Bridgevqa、Robo2vlm、Robobrain2、Omni-Generation(生成任务)、VQA-Mix。
-
发现:
-
所有微调VLM均未超过原始基线,多数性能略有下降(图4)。
-
例外:Vica-332k(数据广泛)和VQA-Mix(通用数据)退化最小,表明VLA需要广泛能力而非狭窄具身技能。
-
生成任务(如深度估计)无益,挑战了当前具身VQA任务的有效性。
-
不同VLM模块的重要性:
在VLM4VLA训练期间,视觉编码器和词嵌入冻结时,三种模型的性能。
-
冻结实验(表3):
-
冻结视觉编码器导致性能显著下降(如Qwen2.5VL-7B在Calvin上从4.057降至2.823)。
-
冻结词嵌入影响微弱,表明视觉模块是瓶颈。
-
-
原因:视觉编码器预训练特征与具身场景未对齐,需微调以适应新视觉信号。
VLM与VLA之间的视觉差距分析
-
假设差距来源:
-
真实图像 vs. 模拟渲染:预训练中的VLM视觉信息可能缺乏桌面模拟渲染;视觉编码器(例如ViT)可能缺乏对作中遇到的模拟图像的有效高层级语义表示
-
视觉-语言理解 vs. 低层动作控制:VLM视觉编码器编码的视觉特征更符合QA式任务中典型的语言输出目标,而机器人中的低层动作控制则需要不同的视觉提示和表现。
-
-
实验验证:在真实世界BridgeV2数据上微调VLM,并注入动作信息(使用FAST tokenizer)。
- 结果(表4):仅微调LLM(冻结视觉)无改善;微调视觉编码器显著提升性能(Simpler从27.6%至45.7%)。
-
结论:差距主要源于语义鸿沟——VLM视觉特征优化于理解任务,而非控制所需细粒度表示,非仅模拟-真实差异。
📜 Conclusion
-
VLM预训练对VLA必要(从头训练性能崩溃),但当前VLM能力与具身需求存在显著差距。
-
视觉编码器是核心瓶颈,需注入控制相关监督;辅助任务微调无效,建议优先保障通用能力。
-
未来应缩小VLM预训练与低层动作控制之间的视觉表征鸿沟。
🤔 Personal Summary
Tips: What aspects did you question, how do you think it can be improved?
🙋♀️ Key Records
“Inconsistencies across benchmarks suggest that VLA policies require capabilities beyond those currently pursued by VLMs.” (Zhang 等, 2026, p. 3) (pdf) 基准测试之间的不一致表明,VLA策略需要超越VLM目前所追求的能力。
因为VLM所准求的VQA的性能跟VLA所在乎的低级动作驱动之间存在着语义鸿沟。所以越好的VLM不见得放在VLA上会更好。
“Interestingly, this conclusion also partially explains the phenomena observed in Sec. 4.2—namely, why various embodied VQA tasks, whether designed in simulation or in the real world, fail to improve a VLM’s performance on VLA” (Zhang 等, 2026, p. 11) (pdf) 有趣的是,这一结论也部分解释了第4.2节观察到的现象——即为何各种具象VQA任务,无论是在模拟中设计还是现实世界,都未能提升VLM在VLA上的性能
因为添加的具身VQA任务都只包含视觉语义信息,没有和低级动作信息结合。由于二者存在gap,所以无论添加多少具身VQA任务辅助微调VLM,都不会取得很好的效果,除非在具身VQA任务中添加动作信息。
Grounding Tasks是一类要求AI模型将语言元素精确关联到视觉世界具体位置的任务,例如:
输入:“画面中最大的那只狗” 输出:[[边框坐标]]
📌 To be resolved
💭 Thought Inspiration
VLM视觉特征与动作控制的语义对齐是未来VLA的方向
VLA开发应该有限评估VLM骨干,而不是设计复杂的策略头。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号