阅读总结:State of Visio-Language-Action Research on ICLR 2026
 论文阅读Day1
论文阅读Day1
文章链接:https://mbreuss.github.io/blog_post_iclr_26_vla.html
What is a Vision-Language-Action Model?
文章提供了2种关于robot foundation policies的定义。
第一种:判断是否为VLA?
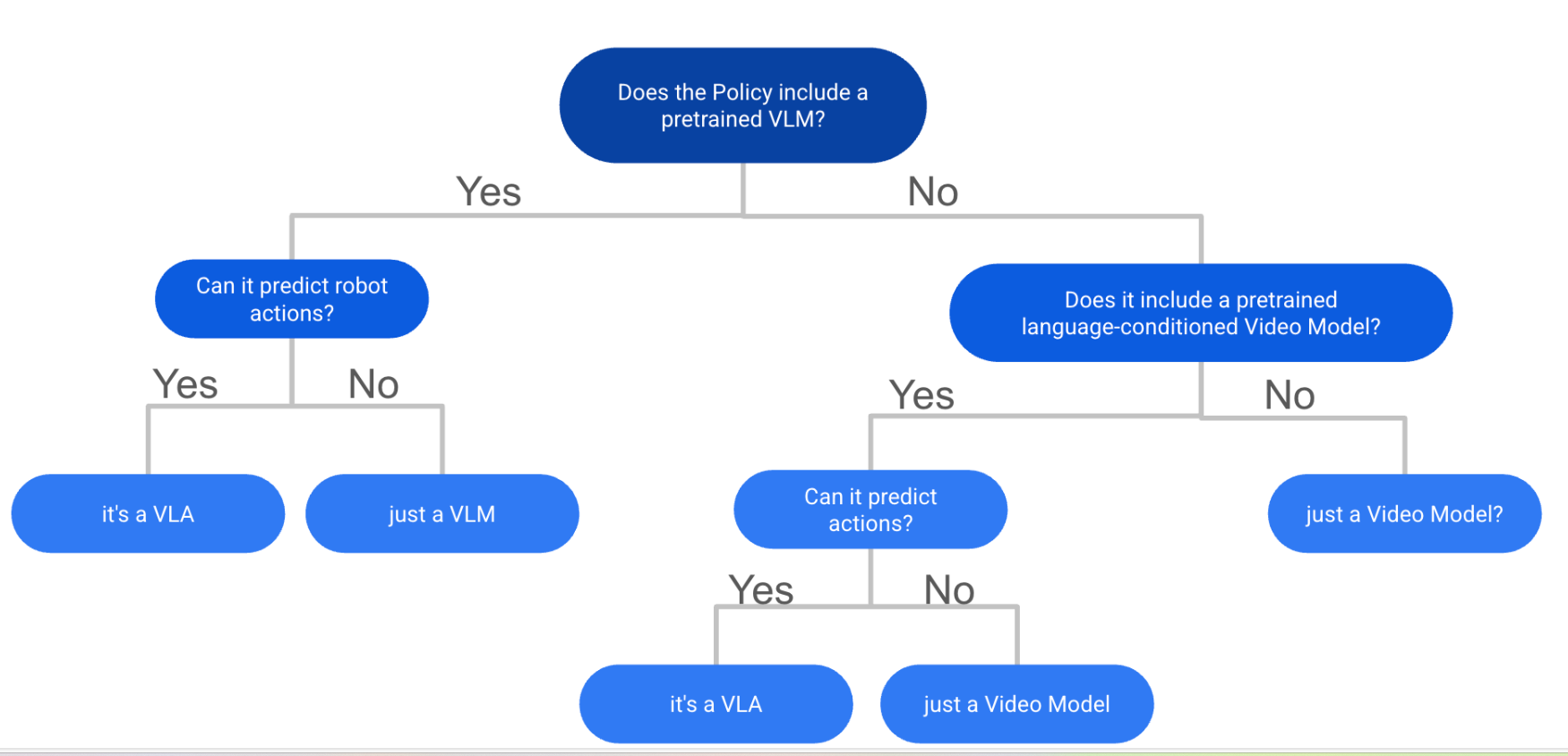
总结:VLA 是一种使用预训练骨干的模型,该骨干通过大规模视觉语言数据训练,随后通过生成控制命令进行训练。
(VLA = VLM + Action)
第二种:判断是否为LBM?
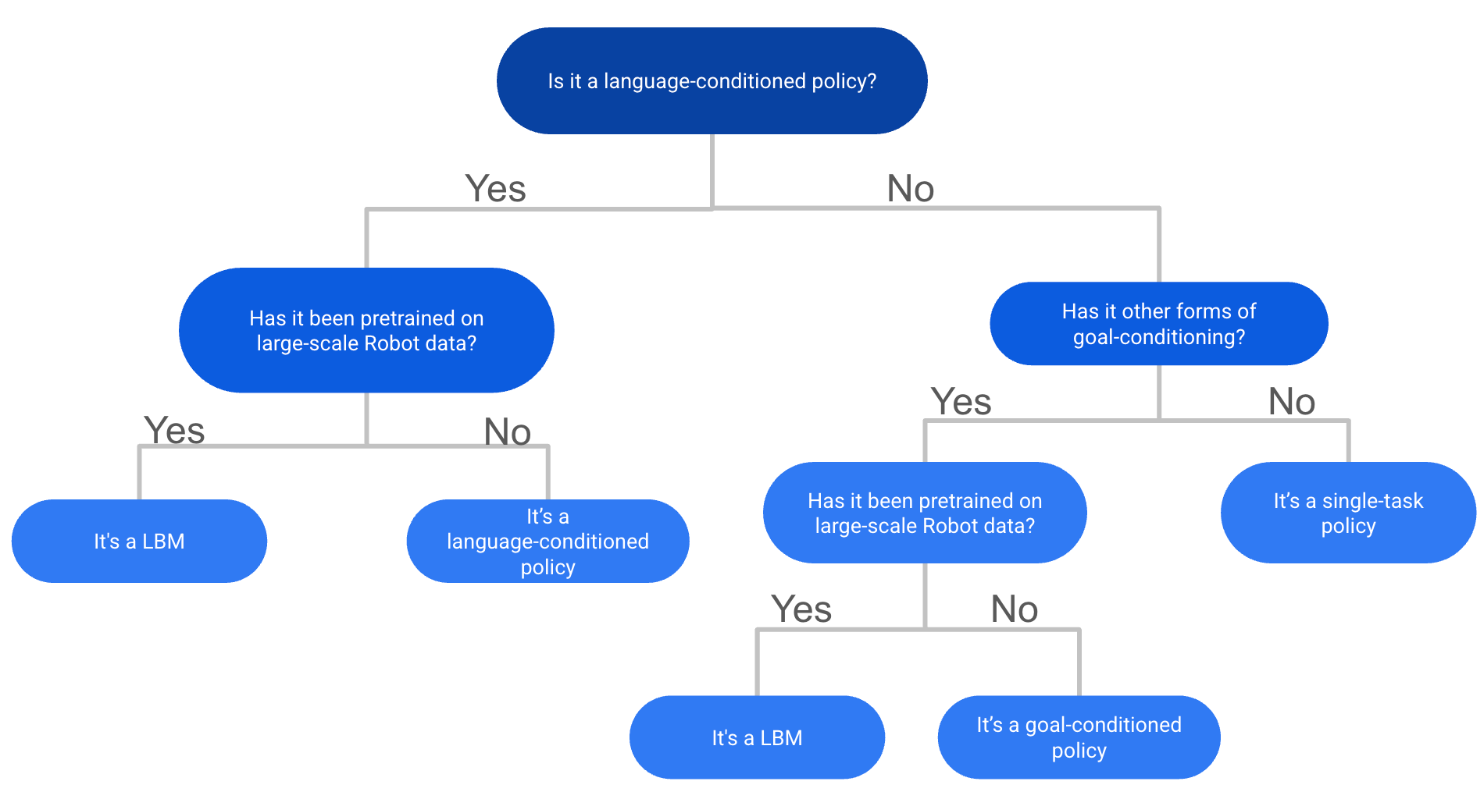
总结:LBM 是基于大规模多任务机器人演示数据训练的机器人策略,但它们不需要互联网规模的视觉语言预训练或 VLM 骨干网。
根据上述两种定义流程,你可以发现就是如果一个模型是VLA,那么它一定是LBM,但是LBM不一定是VLA。因为LBM可能没有试用版预训练的骨干模型。这两个术语共同涵盖了所有类型的robot foundation policies
The Explosive Growth of VLA Research
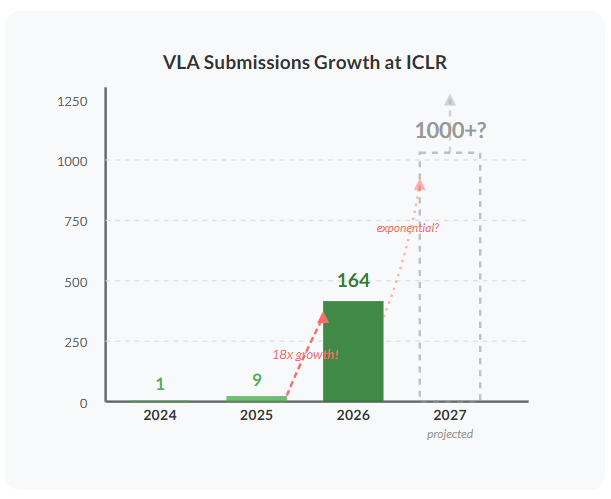
总结:VLA相关的研究正在变得热门
VLA Simulation Benchmark

最受欢迎的 VLA 模拟基准测试概述:LIBERO、SIMPLER 和 CALVIN
里面有一句话我非常认同:
It's also funny to note that LIBERO was designed as a life-long learning benchmark but 99% of models reporting results on it just train on the full dataset and don't do any continual learning. Based on these results it is impossible to say which model is better, as they are all very close to the ceiling anyways and you don't need internet scale pretraining to solve these.
哈哈哈,这个现象真实且有趣
总结:
①对于LIBERO数据集来说,已经被玩烂了,大量的VLA模型都可以在这个benchmark上表现到90%以上的成功率,作者表示即使是训练好的Diffusion Policy这种无需VLA参与的模型都可以在LIBERO上表现得很好。因为大部分在LIBERO上进行测试的模型都是在LIBERO上训练过的,约等于背答案差不多,只是大部分模型都在评测我在有限的step里面能否学的更好
②基准测试有三个主要版本:D(在 D 设置上训练并测试 D)、ABC(在 A、B、C 上训练并测试 D)和 ABCD(在 A、B、C、D 上训练并测试 D)。ABC 是最相关的,因为它测试对未见环境的泛化,ABCD 测试方法从更多样化数据中获益的程度,以及 D 测试微调。 对于 CALVIN,ABC 得分高于 4 是标准,超过 4.5 分则是 SOTA 标准。 对于 D 版本来说,3.75 是标准,4 以上则非常好。 对于 ABCD 版本,4.5 以上的结果具有相关性。
ICLR 2026 VLA Research Trends
1. 离散 VLA 扩散
为什么选择离散扩散?与自回归模型相比,扩散模型可以并行生成序列,这对于离散动作标记生成来说是一大优势。 你不必重复100次战术,只需几次前传就能生成长篇动作序列。
重要论文:
DISCRETE DIFFUSION VLA: BRINGING DISCRETE DIFFUSION TO ACTION DECODING IN VISION-LANGUAGE-ACTION POLICIES
离散扩散 VLA:将离散扩散引入视觉-语言-行动策略中的动作解码
总结:利用 OpenVLA 应用离散扩散动作预测(Discrete Diffusion Action Prediction),快速生成基于分块的离散动作令牌。还提出了自适应解码进行推断。 LIBERO + SIMPLER 取得了强劲的效果。
dVLA: DIFFUSION VISION-LANGUAGE-ACTION MODEL WITH MULTIMODAL CHAIN-OF-THOUGHT
dVLA:具有多模态思维链的扩散视觉-语言-行动模型
总结:简而言之,另一款采用未来帧和文本+动作共生的离散扩散 VLA,因其相较于 AR 模型的快速并行采样优势而实现。 基本上 ECoT + 离散扩散做得不错。 在 LIBERO+的真实世界实验中也有不错的成果。
DIVA: DISCRETE DIFFUSION VISION-LANGUAGE-ACTION MODELS FOR PARALLELIZED ACTION GENERATION
DIVA:用于并行动作生成的离散扩散视觉-语言-动作模型
总结:DR: 另一个离散扩散 VLA,同样专注于在推理过程中替换代币以提升性能。
UNIFIED DIFFUSION VLA: VISION-LANGUAGE-ACTION MODEL VIA JOINT DISCRETE DENOISING DIFFUSION PROCESS
统一扩散 VLA:通过联合离散去噪扩散过程进行视觉-语言-动作模型
总结:生成未来帧和离散动作,同时实现分块因果掩蔽。CALVIN、LIBERO 和 SIMPLER 的成绩都不错。
2. 推理 VLA 与具身思维链(ECoT)
推理对提升 VLA 的泛化和性能具有很大潜力,尽管 VLA 仍难以应对复杂任务和分布外场景。受大型语言模型中链式思维提示成功的启发,越来越多的人对将类似理念应用于虚拟语言表达(VLA)的兴趣日益增长。核心理念是将动作生成与中间的视觉和文本推理步骤连接起来,帮助 VLA 更好地扎根并理解任务和环境。这些推理迹也更具解释性,可用于调试和理解 VLA 的行为。
重要论文:
ACTIONS AS LANGUAGE: FINE-TUNING VLMS INTO VLAS WITHOUT CATASTROPHIC FORGETTING
作为语言的动作:在不导致灾难性遗忘的情况下,将 VLMS 微调为 VLA
总结:他们没有直接用离散动作标记微调 VLM 变成 VLA,这会导致灾难性的遗忘,而是用子任务、动作和中间的动作规划(如“向左移动”)重新标记机器人数据集。 该训练方法能够弥合 VLM 的领域差距,同时不会降低预训练后在其他 VQA 基准测试中的性能。 最后,廉价的 LORA 微调足以在保持 VLM 推理能力的同时,获得强有力的动作预测结果。
VISION-LANGUAGE-ACTION INSTRUCTION TUNING: FROM UNDERSTANDING TO MANIPULATION
视觉-语言-行动指令调谐:从理解到做
总结:简而言之:InstructVLA 提出了一个两阶段的视觉-语言-动作指令调优流水线,旨在保留预训练 VLM 的多模态推理,同时增加精确作:(1)预训练动作专家和潜在动作接口,然后(2)指令调谐一个基于 MoE 的 VLM,使其在文本推理和潜在动作生成之间切换。 它强调与动作专家解耦多模推理与动作生成,以避免灾难性遗忘,并引入基于指令的 SIMPLER 基准测试以测试跟随指令的 VLA。
EMBODIED-R1: REINFORCED EMBODIED REASONING FOR GENERAL ROBOTIC MANIPULATION
具身-R1:强化具身推理,用于通用机器人作
总结:DR:R1 是一个指向型 VLM,用于具身推理:它通过两阶段的强化精细调优(RFT)课程,在新的 Embodied-Points-200K 数据集上训练 Qwen2.5-VL 基础。 它使用与身体无关的中间 REG(指向被指对象)、RRG(指向关系定义的位置)、OFG(指向功能部件,如手柄)、VTG(输出一列点作为视觉轨迹/轨迹)。 在具备基准测试和指向基准测试上表现强劲,并以中介路径点为 SIMPLER 的规划工具。
HYBRID TRAINING FOR VISION-LANGUAGE-ACTION MODELS
视觉-语言-行动模型的混合训练
总结:简而言之: 将 ECoT 预训练分解为思考、行动和跟随的几个子任务,从而能够通过快速推理保持性能优势。 类似的发现是,与 ECoT 的协同训练能更好地表现动作预测。
3. New Tokenizers 3. 新的分词器
我们指挥具有高频连续控制值的机器人(例如关节角度、夹持器状态)。然而,视觉语言模型在离散令牌上工作最为有效。简单地微调 VLM 以回归连续动作往往表现不佳,且常常导致灾难性遗忘,因为新目标与模型的预训练表示不匹配。
这些分词器的核心理念是将连续动作序列转换为 VLM 可预测的紧凑离散令牌——保持准确性和平滑性,同时最小化计算和集成负担。理想的动作分词器应快速,能在长动作块中实现高压缩比,输出平滑的长视野,并且无需修改即可切换到现有的 VLM 架构中。
重要论文:
FASTER: TOWARD POWERFUL AND EFFICIENT AUTOREGRESSIVE VISION–LANGUAGE–ACTION MODELS WITH LEARNABLE ACTION TOKENIZER AND BLOCK-WISE DECODING
更快:迈向强大高效的自回归视野-语言-动作模型,配备可学习的动作分词器和分块解码
总结:简而言之: 引入一种名为 FASTer 的新型离散动作分词器,结合了残差向量定量(RVQ)与使用 DCT 的频率 L1 损耗以及时域 L1 损耗,以提升性能。 还能补丁沿时间轴和分组的动作维度轴(例如基位运动、臂关节)。它的压缩比高于 FAST,在 SIMPLER 和 LIBERO 上的结果也很强劲。
OMNISAT: COMPACT ACTION TOKEN, FASTER AUTOREGRESSION FOR VISION-LANGUAGE-ACTION MODELS
OMNISAT:紧凑动作令牌,视觉-语言-动作模型的更快自回归
总结:DR: 另一个用于 VLA 的分词器,利用我们 BEAST 论文中关于 B 样条的概念,以紧凑表示连续动作块。 它采用两阶段编码过程:首先,将不同实例的不同动作块长度对齐为归一化的固定长度表示。 接下来,它使用基于 B 样条的编码器来获得归一化动作块的紧凑表示。最后,VQ-VAE 用于获得离散的令牌。 LIBERO 和 SIMPLER 的成绩良好,且在所有基准测试中均优于 FAST 和 BEAST。
4. 高效的 VLA
今年有几篇有趣的论文试图用不同的方法来解决这个问题。一般来说,可以将它们分为两类:通过制作更小的 VLA 或更好的标记器等方式,提高训练和模型的效率。或者专注于通过更好的量化、蒸馏或类似方法来提高推断效率。
重要论文:
HYPERVLA: EFFICIENT INFERENCE IN VISION- LANGUAGE-ACTION MODELS VIA HYPERNETWORKS
HYPERVLA:视觉中的高效推断——通过超网络实现的语言-动作模型
总结:DR:HyperVLA 利用超网络生成基于语言指令和初始图像的小型任务特定策略,通过仅在执行时激活紧凑生成的策略而非大型 VLA 模型,显著降低推理成本并保持性能。
AUTOQVLA: NOT ALL CHANNELS ARE EQUAL IN VISION-LANGUAGE-ACTION MODEL’S QUANTIZATION
AUTOQVLA:视觉-语言-行动模型的量化中,并非所有通道都相同
总结:简而言之: 分析 OpenVLA 的量化,并提出了改进的量化方法,以在仅满足原始 VRAM 要求 30%的情况下维持性能。
5. VLA 的强化学习
将 VLA 从现实中 70-80%的成功率提升到 99%仍然是一个悬而未决的问题。现实学习有很大希望缩小这一差距。虽然之前有很多尝试,但还没有哪种方法成为首选。
重要论文:
SELF-IMPROVING VISION-LANGUAGE-ACTION MODELS WITH DATA GENERATION VIA RESIDUAL RL
通过残差强化学习生成数据的自我改进视觉-语言-行动模型
总结: 残差强化学习法,通过冻结的 VLA 和小残差策略收集更多数据。剩余干预用于获得更多高质量的恢复行为数据。 最后,VLA 通过 SFT 进行微调。LIBERO 的成绩达到了 99%。
PROGRESSIVE STAGE-AWARE REINFORCEMENT FOR FINE-TUNING VISION-LANGUAGE-ACTION MODELS
渐进式阶段感知强化,用于微调视觉-语言-动作模型
总结:简而言之: 该方法将机器人任务拆分为语义阶段(Reach→Grasp→Transport→Place),并为每个阶段分配奖励,而非整个轨迹。它使用 STA-TPO 进行离线偏好学习,STA-PPO 进行在线强化学习,两者均在阶段层面运行。 Bridge SIMPLER 的评分为 98%。
6.VLA + 视频预测
视频生成模型学习丰富的时间动态和物理交互表示,这可能为机器人控制提供有用的先验。继 2024 年 ICLRGR-1 论文的强劲成果,展示了基于视频的政策潜力后,这一子领域的兴趣不断增长。 这些策略通常分为两类:(1)从已预训练图像/视频生成的 VLM 开始,然后继续训练未来帧和动作预测;或者(2)从视频基础模型出发并修改以生成动作。
由于大多数最先进的视频基础模型基于扩散/流量,这些策略通常难以应对缓慢的推断速度。总体来看,结果表明视频生成及其所需的物理理解和语言基础,为机器人学习提供了宝贵的先验条件。
重要论文:
DISENTANGLED ROBOT LEARNING VIA SEPARATE FORWARD AND INVERSE DYNAMICS PRETRAINING
通过分别的正向动力学和逆动力学预训练进行解缠机器人学习
总结:DR: 通过预训练分开的正向和逆动力学模型,引入了一种新的机器人学习方法。 第二阶段,它们再次合并,进行保单的联合微调。在 CALVIN 上,SIMPLER 低调的成绩不错。
UNIFIED VISION–LANGUAGE–ACTION MODEL
统一的愿景-语言-行动模型
总结:DR: 将视觉、语言和动作建模为单一交错的离散令牌流(VQ 图像令牌+FAST/DCT 动作令牌),并训练一个自回归的 8.5B 级 VLA。 UniVLA 有两个训练阶段用于将 VLM 转换为 VLA:首先是带有文本和图像的后序列 VLM,用于预测未来帧;随后是精细调优阶段,预测视觉和动作令牌。 主要强调训练后阶段,以更好地将 VLM 表示与机器人任务对齐。 CALVIN、LIBERO 和 SimplerEnv-Bridge 的结果都很强劲。
COSMOS POLICY: FINE-TUNING VIDEO MODELS FOR VISUOMOTOR CONTROL AND PLANNING
宇宙政策:微调视频模型以实现视觉运动控制与规划
总结:简而言之: 微调了 NVIDIA 的 Cosmos 视频基金会模型以实现动作预测。 核心思想是将未来动作块或价值函数估计等额外模态注入潜在令牌序列。 LIBERO 的结果不错,而且他们也有与 Pi0.5 的现实世界对比。
7. VLA 的评估与基准测试
VLA 基准测试的现状相当饱和,鉴于基准测试数量有限且大多数论文仅与其他少数基线比较,很难判断哪个模型更优。幸运的是,有几家提交尝试通过引入新的 VLA 基准来弥合这一差距。其他想法包括用真实 2sim 世界模型测试生成环境中的策略。
重要论文:
ROBOTARENA ∞: UNLIMITED ROBOT BENCHMARKING VIA REAL-TO-SIM TRANSLATION
ROBOTARENA ∞:通过实测到模拟的无限机器人基准测试
总结:DR: 引入了一个新的 Real2Sim 基准测试框架,其评分系统类似于 RoboArena。 它提供利用物理引擎、实二模拟转换和人工反馈的自动环境构建和评估。 他们使用 real2sim 翻译流水线,结合大量基础模型和可微分渲染和基于 VLM 的任务进度评分。 乍一看非常有趣,我也很期待自己试试。
ROBOCASA365: A LARGE-SCALE SIMULATION FRAMEWORK FOR TRAINING AND BENCHMARKING GENERALIST ROBOTS
ROBOCASA365:用于训练和基准测试通用机器人的大规模仿真框架
总结:DR: 在最初的 RoboCasa 模拟和基准测试基础上扩展,新增了 365 个任务,覆盖 2k+厨房场景,以及超过 2000 小时的远程作数据。 任务设置看起来很棒,数据规模也很有希望,只是希望他们测试的基础策略比只有3个多。
WORLDGYM: WORLD MODEL AS AN ENVIRONMENT FOR POLICY EVALUATION
WORLDGYM:作为政策评估环境的世界模型
总结:DR:WorldGym 提议使用动作条件视频生成模型(世界模型)作为评估机器人策略的环境,策略在生成的世界中展开,并由提供奖励的视觉语言模型进行评估。
8. 跨行动空间学习
使用带有动作标签的人类自我视频进行预训练 VLA 的兴趣也日益增长。像 EgoDex 今年早些时候发布的数据集,现在支持了更多在这方面的研究。今年有几篇有趣的论文提交,试图用不同的方法解决这个问题。它们要么专注于 VLA 的架构细节以更好地处理异构动作空间,要么通过图像空间中的运动等额外抽象来实现更好的传输。
重要论文:
X-VLA: SOFT-PROMPTED TRANSFORMER AS SCALABLE CROSS-EMBODIMENT VISION-LANGUAGE-ACTION MODEL
X-VLA:软提示变换器作为可扩展的跨身体视觉-语言-动作模型
总结:DR: 针对不同数据集使用软提示令牌实现跨动作空间学习。 这些软提示令牌是 VLA 可学习的读出令牌。 LIBERO、CALVIN、SIMPLER RoboTwin 和 VLABench 的成绩都非常好。还有非常有见地的缩放分析。
XR-1: TOWARDS VERSATILE VISION-LANGUAGE-ACTION MODELS VIA LEARNING UNIFIED VISION-MOTION REPRESENTATIONS
XR-1:通过学习统一的视觉-运动表征,迈向多功能视觉-语言-行动模型
总结:DR:XR-1 引入了统一视觉-运动编码(UVMC),这是一种离散潜在表示,通过双分支 VQ-VAE 和共享代码本共同编码视觉动力学和机器人运动。这有助于从人机演示中更好地进行协同预训练。 在现实世界对 Groot-N.1.5 和 Pi0 的实验中进行了测试,效果良好。
HIMOE-VLA: HIERARCHICAL MIXTURE-OF-EXPERTS FOR GENERALIST VISION–LANGUAGE–ACTION POLICIES
HIMOE-VLA:专家层级混合,支持通用愿景-语言-行动政策
总结:DR: 用层级专家混合变换器替代 Pi 风格的动作专家,以更好地适应新的实体。 它将标准积木与两种 MoE 积木交错:动作空间 MoE 和异构平衡 MoE,以更好地处理不同的动作空间。 在多项实验中改进了 Pi0。
9. 其他有趣论文
HAMLET: SWITCH YOUR VISION-LANGUAGE-ACTION MODEL INTO A HISTORY-AWARE POLICY
哈姆雷特:将你的愿景-语言-行动模型转变为一个历史意识的政策
总结:简而言之: 引入了即插即用的内存模块,带有瞬间标记,用于捕捉前一时间步的时间数据。一种提出的内存模块通过时间聚合代币,实现历史条件预测。
COMPOSE YOUR POLICIES! IMPROVING DIFFUSION-BASED OR FLOW-BASED ROBOT POLICIES VIA TEST-TIME DISTRIBUTION-LEVEL COMPOSITION
制定你的保单!通过测试时间分发层级组合改进基于扩散或流量的机器人策略
总结:简而言之: 引入一种在测试时组合基于流/扩散的 VLA 策略的方法,以提升单个策略的性能。 作者利用凸优化和测试时搜索组合多项策略的评分,以提升性能。
VLM4VLA: REVISITING VISION-LANGUAGE-MODELS IN VISION-LANGUAGE-ACTION MODELS
VLM4VLA:在视觉语言行动模型中重新审视视觉语言模型
总结:总结: 比较了许多 VLM 作为 VLA 骨干选择,发现下游性能与标准基准测试中的 VLM 性能无相关性。 这也印证了我自己尝试各种 VLM 骨干的经验。然而,论文仍仅限于基准测试,未测试真实机器人的结果。
@misc{reuss2025state-vla-iclr26,
title = {State of VLA Research at ICLR 2026},
author = {Reuss, Moritz},
year = {2025},
month = {October},
howpublished = {\url{https://mbreuss.github.io/blog_post_iclr_26_vla.html}},
note = {Blog post},
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号