
【线性回归】使用 PyTorch 手写一个线性回归从零开始的训练过程
一. 数据准备阶段
1. 导入库
%matplotlib inline
import random
import matplotlib.pyplot as plt
import torch
from d2l import torch as d2l

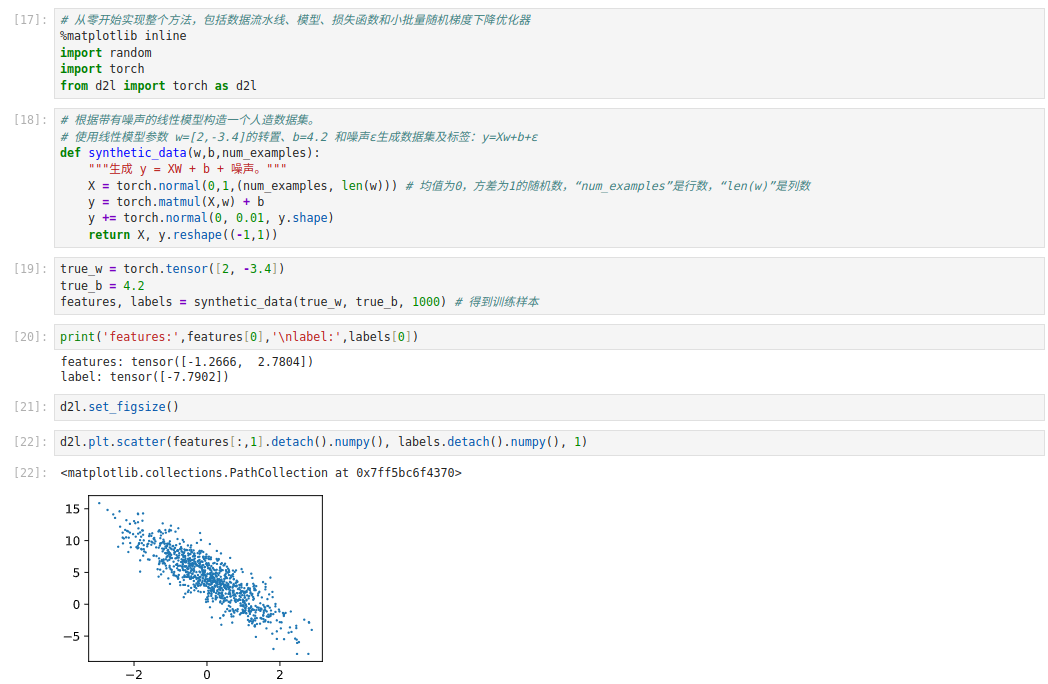
2. 合成数据
def synthetic_data(w, b, num_examples):
# 生成 y = Xw + b + 噪声
X = torch.normal(0, 1, (num_examples, len(w))) # 生成num_examples行、len(w)列的正态分布数据
y = torch.matmul(X, w) + b
# 加一点噪声
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)

3. 可视化数据
plt.scatter(features[:, 1].detach().numpy(), labels.detach().numpy(), 1)
plt.show()

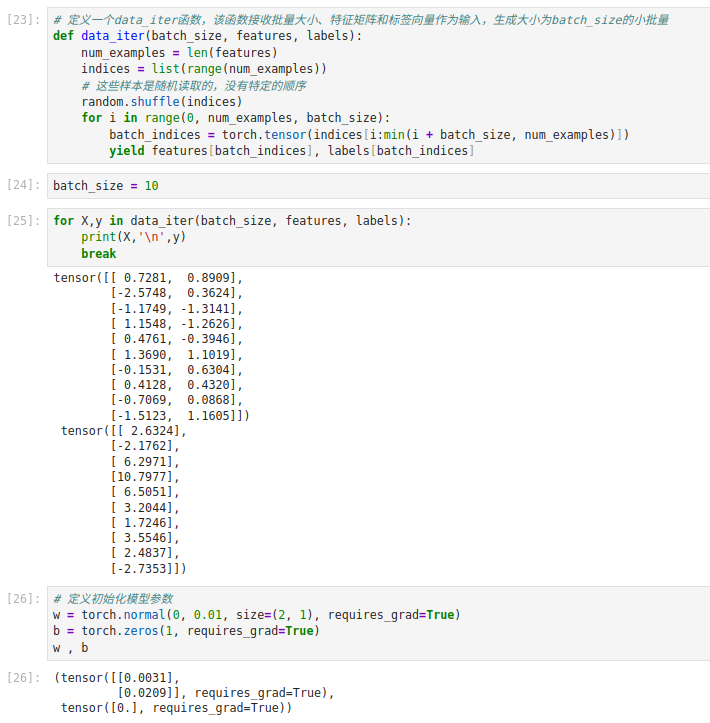
二. 定义批量读取函数 (mini-batch)
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices) # 将索引打乱,随机取样
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(indices[i: i + batch_size])
yield features[batch_indices], labels[batch_indices]

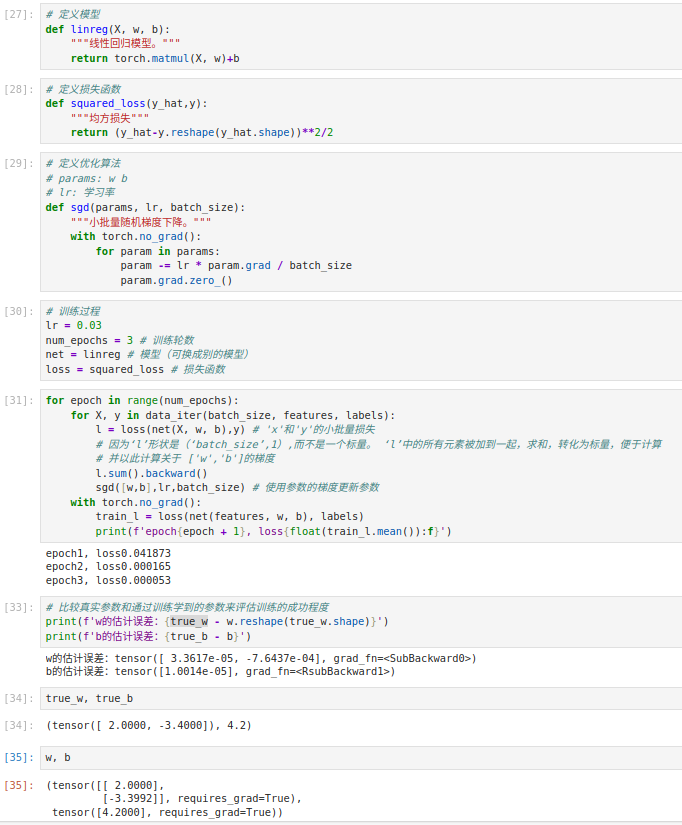
三. 模型定义与损失函数
1. 线性模型
def linreg(X, w, b):
return torch.matmul(X, w) + b
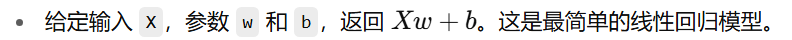
2. 损失函数
def squared_loss(y_hat, y):
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2

3. 小批量随机梯度下降
def sgd(params, lr, batch_size):
with torch.no_grad(): # 关闭求梯度的上下文
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_() # 梯度清零

四. 训练过程
lr = 0.03
num_epochs = 3
batch_size = 10
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
# 1. 计算模型输出
y_hat = linreg(X, w, b)
# 2. 计算损失
l = squared_loss(y_hat, y)
# 3. 反向传播
l.sum().backward()
# 4. 参数更新
sgd([w, b], lr, batch_size)
# 每个epoch结束后,打印一下训练误差
train_l = squared_loss(linreg(features, w, b), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')

五. 结果查看
print(true_w, '\n', w)
print(true_b, '\n', b)

六. 整体流程图(示意)



 浙公网安备 33010602011771号
浙公网安备 33010602011771号