深度学习 - 卷积神经网络之卷积、填充、步长介绍
一 计算机视觉
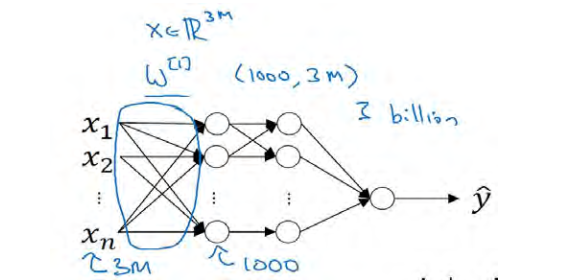
把神经网络应用于计算机视觉时,有一个很大的挑战,就是数据的输入可能会非常大。举个例子,在过去的课程中,你们一般操作的都是 64×64 的小图片,实际上,它的数据量是 64×64×3,因为每张图片都有 3 个颜色通道。如果计算一下的话,可得知数据量为 12288,所以我们的特征向量。 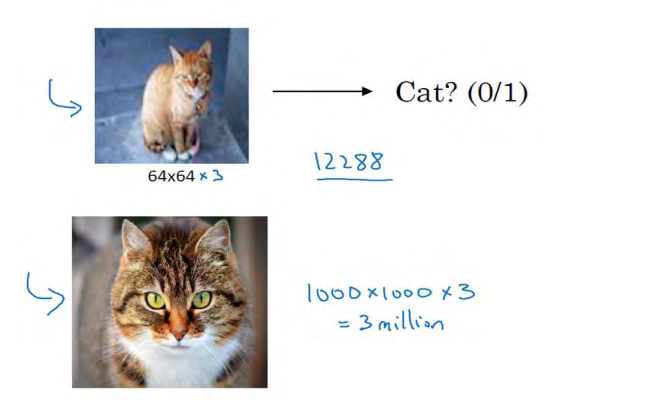
如果你要操作更大的图片,比如一张 1000×1000 的图片,它足有 1 兆那么大,但是特征向量的维度达到了 1000×1000×3,因为有 3 个 RGB 通道,所以数字将会是 300 万。
二 边缘检测
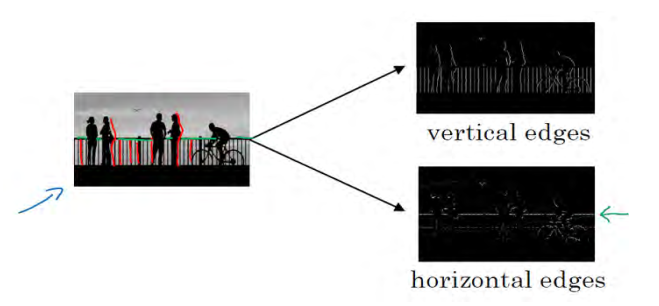
让我们举个例子,给了这样一张图片,让电脑去搞清楚这张照片里有什么物体,你可能做的第一件事是检测图片中的垂直边缘。比如说,在这张图片中的栏杆就对应垂直线,与此同时,这些行人的轮廓线某种程度上也是垂线,这些线是垂直边缘检测器的输出。同样,你可能也想检测水平边缘,比如说这些栏杆就是很明显的水平线,它们也能被检测到,结果在这。所以如何在图像中检测这些边缘?
看一个例子,这是一个 6×6 的灰度图像。因为是灰度图像,所以它是 6×6×1 的矩阵,而不是 6×6×3 的,因为没有 RGB 三通道。为了检测图像中的垂直边缘,你可以构造一个 3×3矩阵。
对这个 6×6 的图像进行卷积运算, 卷积运算用“∗”来表示, 用 3×3的过滤器对其进行卷积
。
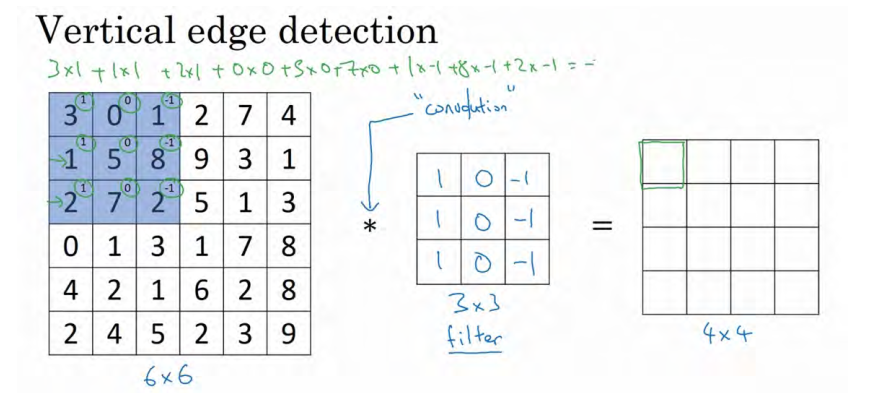
这个卷积运算的输出将会是一个 4×4 的矩阵,你可以将它看成一个 4×4 的图像。下面来说明是如何计算得到这个 4×4 矩阵的。为了计算第一个元素,在 4×4 左上角的那个元素,使用 3×3 的过滤器,将其覆盖在输入图像,如下图所示。然后进行元素乘法(element-wiseproducts)运算
。计算如下3x1+0x0+1x(-1)+1x1+5x0+8x(-1)+2x1+7x0+2x(-1)=-5。
把蓝色的方块,向右移动一步,同理,我们就能够得到第一行第二列的值。
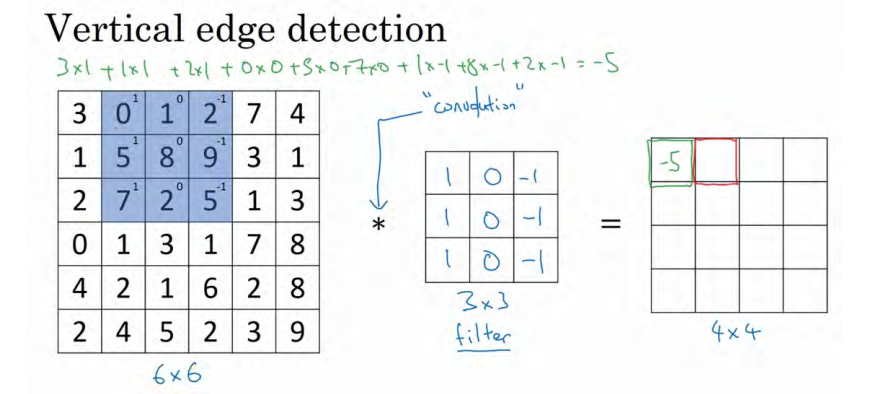
继续向右移动,直到把蓝色方块移动到最右边,到此,我们会得到如下结果:
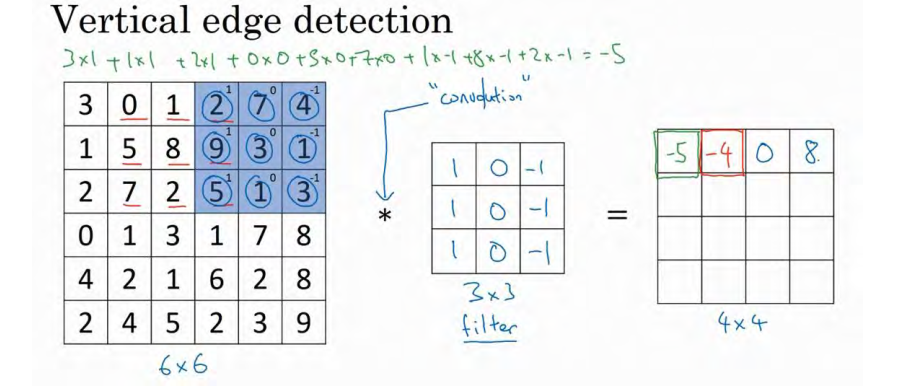
接下来为了得到下一行的元素,现在把蓝色块下移,现在蓝色块在这个位置 :
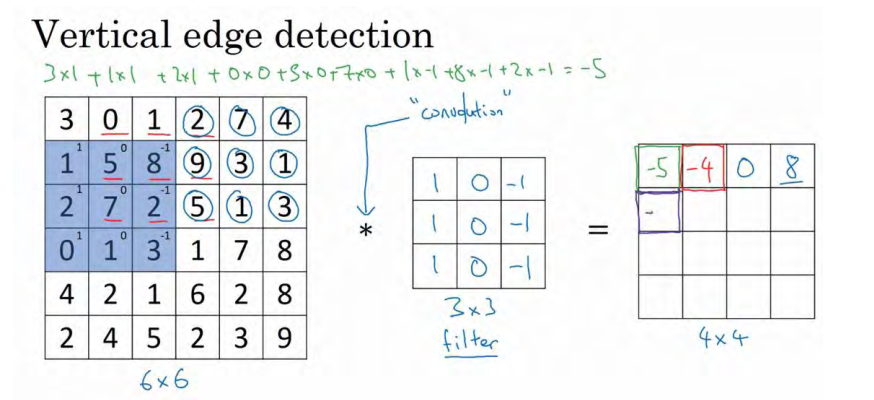
重复进行元素乘法,然后加起来。通过这样做得到-10。再将其右移得到-2,接着是 2,3。以此类推,这样计算完矩阵中的其他元素。
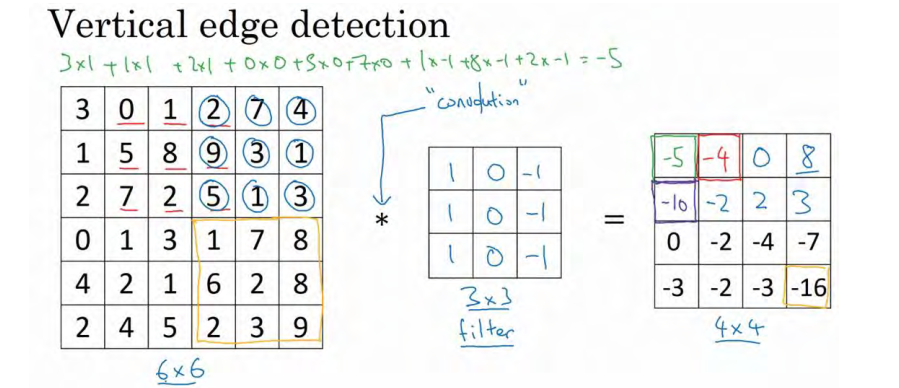
为什么这个可以做垂直边缘检测呢?让我们来看另外一个例子。为了讲清楚,我会用一个简单的例子。这是一个简单的 6×6 图像,左边的一半是 10,右边一般是 0。如果你把它当成一个图片,左边那部分看起来是白色的,像素值 10 是比较亮的像素值,右边像素值比较暗,我使用灰色来表示 0,尽管它也可以被画成黑的。图片里,有一个特别明显的垂直边缘在图像中间,这条垂直线是从黑到白的过渡线,或者从白色到深色。
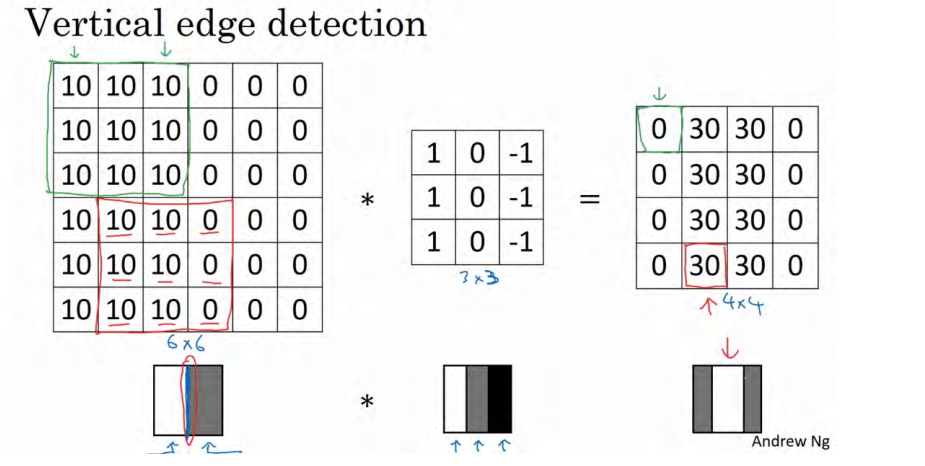
所以,当你用一个 3×3 过滤器进行卷积运算的时候,这个 3×3 的过滤器可视化为下面这个样子,在左边有明亮的像素,然后有一个过渡, 0 在中间,然后右边是深色的。如果把最右边的矩阵当成图像,它是这个样子。在中间有段亮一点的区域,对应检查到这个 6×6 图像中间的垂直边缘。这里的维数似乎有点不正确,检测到的边缘太粗了。因为在这个例子中,图片太小了。如果你用一个 1000×1000 的图像,而不是 6×6 的图片,你会发现其会很好地检测出图像中的垂直边缘。 在这个 6×6 图像的中间部分,明亮的像素在左边,深色的像素在右边,就被视为一个垂直边缘,卷积运算提供了一个方便的方法来发现图像中的垂直边缘 。
三 更多边缘检测
上一小节中,你已经见识到用卷积运算实现垂直边缘检测,在本节,你将学习如何区分正边和负边,这实际就是由亮到暗与由暗到亮的区别,也就是边缘的过渡。你还能了解到其他类型的边缘检测以及如何去实现这些算法,而不要总想着去自己编写一个边缘检测程序,让我们开始吧。
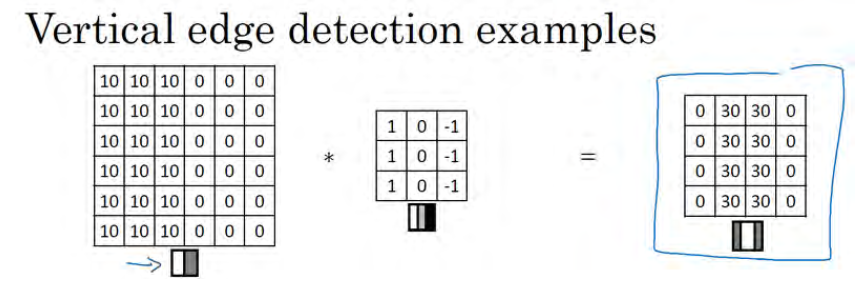
还是上一个小节中的例子,这张 6×6 的图片,左边较亮,而右边较暗,将它与垂直边缘检测滤波器进行卷积,检测结果就显示在了右边这幅图的中间部分。
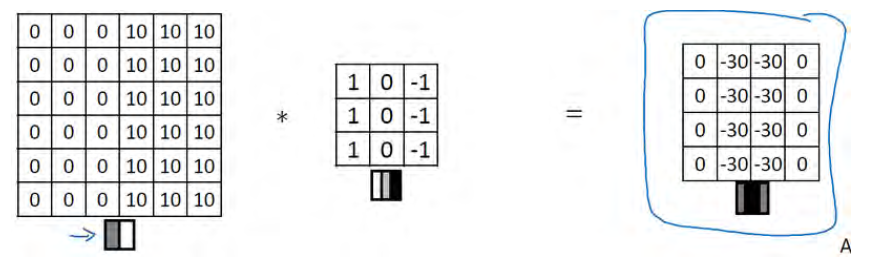
现在这幅图有什么变化呢?它的颜色被翻转了,变成了左边比较暗,而右边比较亮。现在亮度为 10 的点跑到了右边,为 0 的点则跑到了左边。如果你用它与相同的过滤器进行卷积,最后得到的图中间会是-30,而不是 30。如果你将矩阵转换为图片,就会是该矩阵下面图片的样子。现在中间的过渡部分被翻转了,之前的 30 翻转成了-30,表明是由暗向亮过渡,而不是由亮向暗过渡
之前我们讲解的3x3的过滤器,能够对垂直边缘进行检测,现在我们再来看看右边这个过滤器,我想你应该猜出来了,它能让你检测出水平的边缘。提醒一下,一个垂直边缘过滤器是一个 3×3 的区域,它的左边相对较亮,而右边相对较暗。相似的,右边这个水平边缘过滤器也是一个 3×3 的区域,它的上边相对较亮,而下方相对较暗
。

这里还有个更复杂的例子,左上方和右下方都是亮度为 10 的点。如果你将它绘成图片,右上角是比较暗的地方,这边都是亮度为 0 的点,我把这些比较暗的区域都加上阴影。而左上方和右下方都会相对较亮。如果你用这幅图与水平边缘过滤器卷积,就会得到右边这个矩阵。
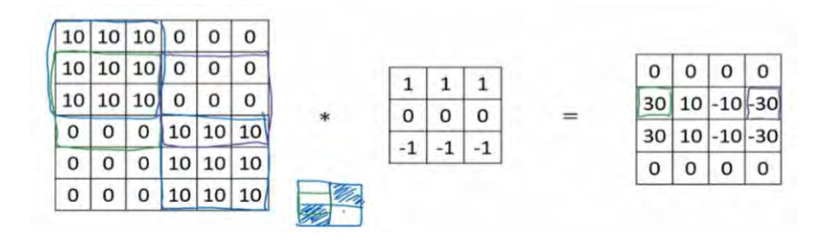
再举个例子,这里的 30(右边矩阵中绿色方框标记元素)代表了左边这块 3×3 的区域(左边矩阵绿色方框标记部分),这块区域确实是上边比较亮,而下边比较暗的,所以它在这里发现了一条正边缘。而这里的-30(右边矩阵中紫色方框标记元素)又代表了左边另一块区域(左边矩阵紫色方框标记部分),这块区域确实是底部比较亮,而上边则比较暗,所以在这里它是一条负边。
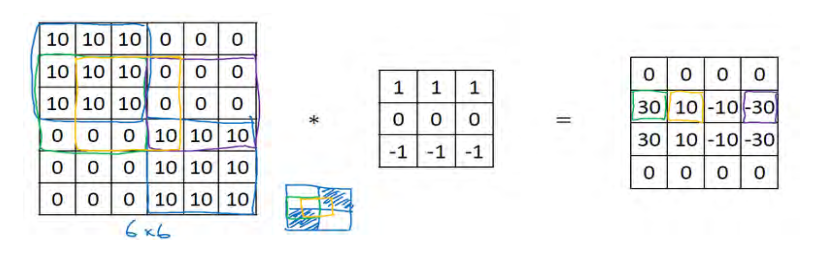
再次强调,我们现在所使用的都是相对很小的图片,仅有 6×6。但这些中间的数值,比如说这个 10(右边矩阵中黄色方框标记元素)代表的是左边这块区域(左边 6×6 矩阵中黄色方框标记的部分)。这块区域左边两列是正边,右边一列是负边, 正边和负边的值加在一
起得到了一个中间值。但假如这个一个非常大的 1000×1000 的类似这样棋盘风格的大图,就不会出现这些亮度为 10 的过渡带了,因为图片尺寸很大,这些中间值就会变得非常小。
总而言之,通过使用不同的过滤器,你可以找出垂直的或是水平的边缘。但事实上,对于这个 3×3 的过滤器来说,我们使用了其中的一种数字组合 。
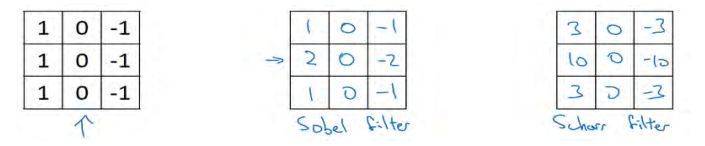
但在历史上,在计算机视觉的文献中,曾公平地争论过怎样的数字组合才是最好的,上图中间的叫做 Sobel 的过滤器,它的优点在于增加了中间一行元素的权重,这使得结果的鲁棒性会更高一些。
但计算机视觉的研究者们也会经常使用其他的数字组合,比如上图右边这个,这叫做 Scharr 过滤器,它有着和之前完全不同的特性,实际上也是一种垂直边缘检测,如果你将其翻转 90 度,你就能得到对应水平边缘检测。
随着深度学习的发展,我们学习的其中一件事就是当你真正想去检测出复杂图像的边缘,你不一定要去使用那些研究者们所选择的这九个数字,但你可以从中获益匪浅。把这矩阵中的 9 个数字当成 9 个参数,并且在之后你可以学习使用反向传播算法,其目标就是去理解这9 个参数
。通过数据反馈,让神经网络自动去学习它们,我们会发现神经网络可以学习一些低级的特征,例如这些边缘的特征。尽管比起那些研究者们,我们要更费劲一些,但确实可以动手写出这些东西。不过构成这些计算的基础依然是卷积运算,使得反向传播算法能够让神经网络学习任何它所需要的 3×3 的过滤器,并在整幅图片上去应用它。
除了检测边缘外,我们想检测到更多的特征怎么办?多个隐藏层让深度神经网络能够表示数据中更为复杂的特征,例如:在用深度卷积神经网络(CNN)进行人脸识别时,较为底层的隐藏层首先提取的是图片中一些边缘和界面的特征,随着层级的提高,图片中一些纹理的特征可能会显现,而随着层级继续提高,一些具体的对象将会显现,例如:眼睛、鼻子、耳朵等,再到更高层时,整个人脸的特征也就被提取了出来。在一个深度神经网络上,较高层的特征是低层特征的组合,而随着神经网络从低层到高层,其提取的特征也越来越抽象、越来越涉及“整体”的性质。
四 Padding
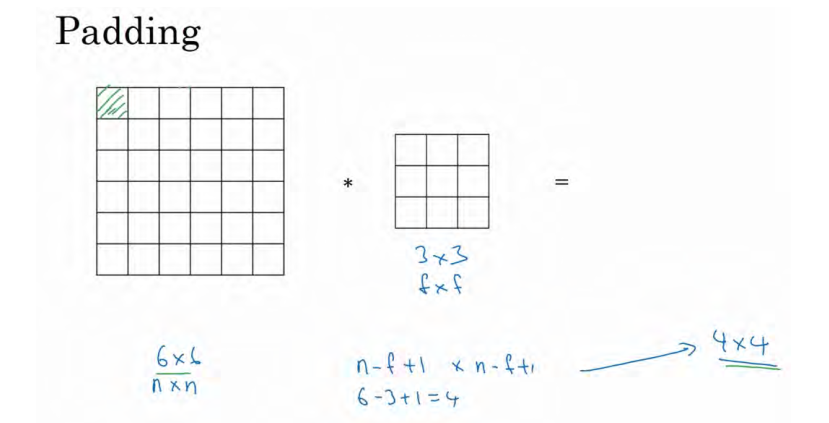
之前我们讲到,如果你用一个 3×3 的过滤器卷积一个 6×6 的图像,你最后会得到一个 4×4 的输出,也就是一个 4×4 矩阵。这背后的数学解释是,如果我们有一个nxn的图像,用fxf的滤波器
做卷积,最后你会得到一个(n-f+1)x(n-f+1)的输出。
这么做会有两个缺点:
- 第一个缺点是每次做卷积操作,你的图像就会缩小
- 第二个缺点时,如果你注意角落边缘的像素,这个像素点(绿色阴影标记)只被一个输出所触碰或者使用,因为它位于这个 3×3 的区域的一角。但如果是在中间的像素点,比如这个(红色方框标记),就会有许多 3×3 的区域与之重叠。所以那些在角落或者边缘区域的像素点在输出中采用较少,意味着你丢掉了图像边缘位置的许多信息。
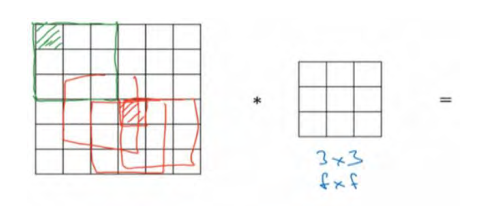
为了解决这些问题,你可以在卷积操作之前填充这幅图像。 在这个案例中,你可以沿着图像边缘再填充一层像素。
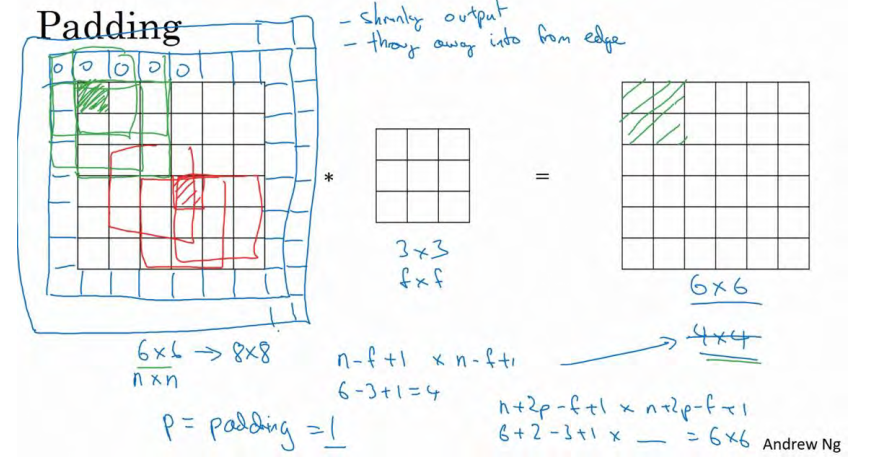
习惯上,你可以用 0 去填充,如果 p是填充数量,在这个案例中p=1,因为我们在周围都填充了一个像素点,输出也就变成了
(n+2p-f+1)x(n+2p-f+1),即6x6输出和输入一样。这个涂绿的像素点(左边矩阵)影响了输出中的这些格子(右边矩阵)。这样一来,丢失信息或者更准确来说角落或图像边缘的信息发挥的作用较小的这一缺点就被削弱了。
如果你想的话,也可以填充两个像素点, 实际上你还可以填充更多像素 。
至于选择填充多少像素,通常有两个选择,分别叫做 Valid 卷积和 Same 卷积。
Valid 卷积意味着不填充,这样的话,如果你有一个nxn的图像,和f xf的过滤器做卷积,你会得到(n-f+1)x(n-f+1)维的输出。
Same 卷积,那意味你填充后,你的输出大小和输入大小是一样的
。根据公式n-f+1,当你填充p个像素点,图像原有的n变成了n+2p,最后输出变成了n+2p-f+1。因此如果你有一个nxn的图像,用p个像素填充,输出的大小就是(n+2p-f+1)x(n+2p-f+1)。如果要是使n+2p-f+1=n,那么p=(f-1)/2,所以当f是一个奇数的时候,只要选择相应的填充尺寸,你就能确保得到和输入相同尺寸的输出。
(推荐使用奇数的过滤器)
五 卷积步长
卷积中的步幅是另一个构建卷积神经网络的基本操作。 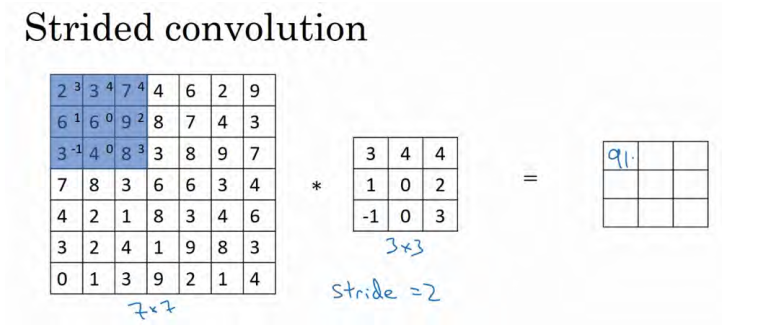
如果你想用 3×3 的过滤器卷积这个 7×7 的图像,和之前不同的是,我们把步幅设置成了2。你还和之前一样取左上方的 3×3 区域的元素的乘积,再加起来,最后结果为 91 。

只是之前我们移动蓝框的步长是 1,现在移动的步长是 2,我们让过滤器跳过 2 个步长,注意一下左上角,这个点移动到其后两格的点,跳过了一个位置。然后你还是将每个元素相乘并求和,你将会得到的结果是 100。

现在我们继续,将蓝色框移动两个步长,你将会得到 83 的结果。当你移动到下一行的 时候,你也是使用步长 2 而不是步长 1,所以我们将蓝色框移动到这里: 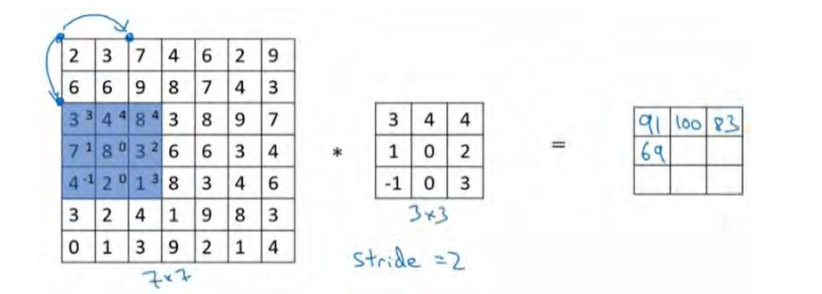
注意到我们跳过了一个位置,得到 69 的结果,现在你继续移动两个步长,会得到 91,127,最后一行分别是 44, 72, 74。
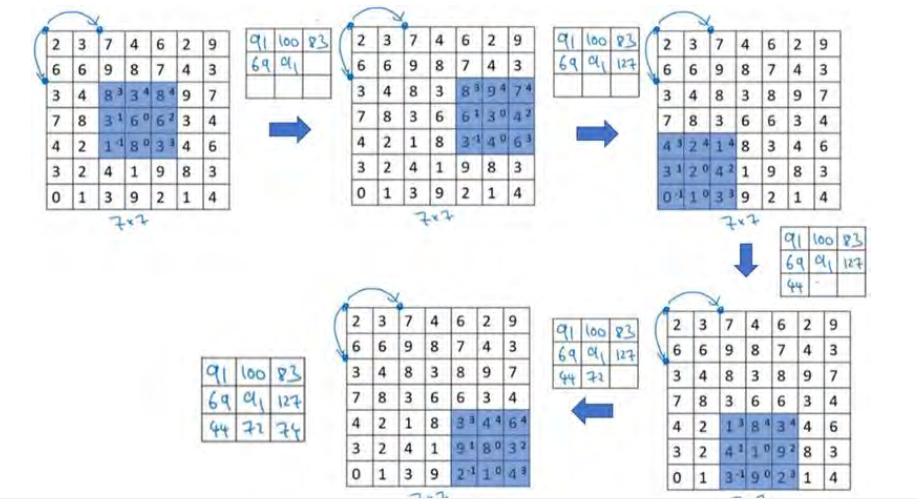
所以在这个例子中,我们用 3×3 的矩阵卷积一个 7×7 的矩阵,得到一个 3×3 的输出。输入和输出的维度是由下面的公式决定的。 如果你用一个 fxf的过滤器和nxn的图像做卷积,padding设置为p,stride设置为s,输出则为(n+2p-f)/s+1 x (n+2p-f)/s+1。

现在只剩下最后的一个细节了,如果商不是一个整数怎么办?在这种情况下,我们向下取整,即
向下取整到最近的整数
,这个原则实现的方式是,你只在蓝框完全包括在图像或填充完的图像内部时,才对它进行运算。如果有任意一个蓝框移动到了外面,那你就不要进行相乘操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号