
redis整合Spring集群搭建及业务中的使用
1.redis安装
Redis是c语言开发的。
安装redis需要c语言的编译环境。如果没有gcc需要在线安装。yum install gcc-c++
安装步骤:
第一步:redis的源码包上传到linux系统。
第二步:解压缩redis。
第三步:编译。进入redis源码目录。make
第四步:安装。make install PREFIX=/usr/local/redis
PREFIX参数指定redis的安装目录。一般软件安装到/usr目录下
详细安装步骤,以及后台运行的配置 点此 linux上安装redis
2.Redis-cli 客户端连接redis
找到安装redis的文件夹中的bin目录.执行以下命令
[root@localhost bin]# ./redis-cli
默认连接localhost运行在6379端口的redis服务。
[root@localhost bin]# ./redis-cli -h 192.168.25.153 -p 6379
-h:连接的服务器的地址
-p:服务的端口号
关闭redis:[root@localhost bin]# ./redis-cli shutdown
3.Redis五种数据类型
redis五种数据类型及命令操作 点此 reids基本命令
4.Redis的持久化方案
redis持久化方法点此 redis持久化方案
5.Redis集群的搭建
5.1 redis-cluster架构图
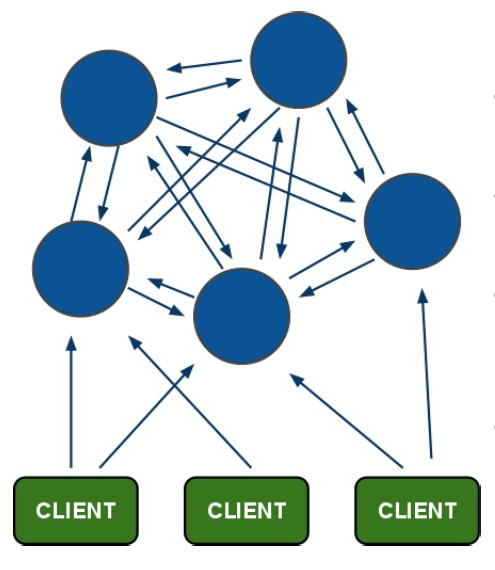
redis的每个节点上都保存有其他节点的信息,并且相互通信,客户端连接集群时,随机连接
5.2redis-cluster投票:容错
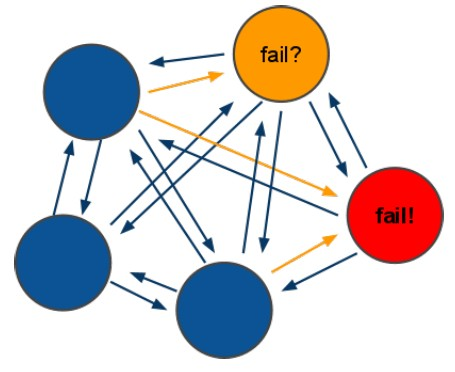
1. redis每个节点之间每隔一段时间就会相互的ping一下,对方收到ping后会回复pong,如上图,如果黄色的节点ping红色的节点时,红色节点没给回复,黄色节点就会以为红色节点已经挂了,接着其他节点去ping红色节点,如果多数节点没有收到回信,则判断红色节点已挂,投票容错就这样.
2. 因为redis的投票容错机制,所以redis的集群至少应该有三个及以上的节点
3.Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value 时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点如下图,所以理论上redis的节点可以有16384个
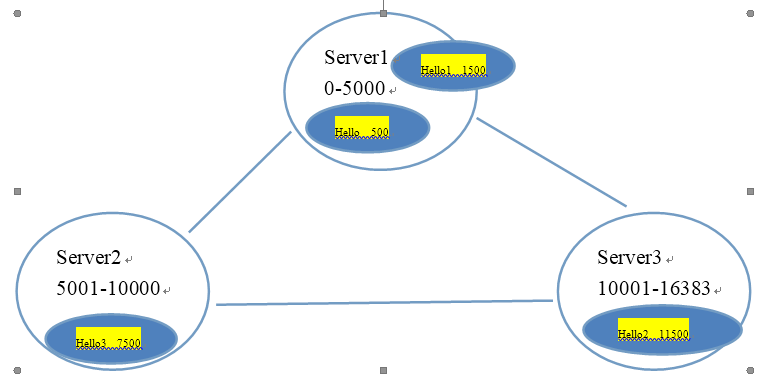
5.3. Redis集群的搭建
Redis集群中至少应该有三个节点。要保证集群的高可用,需要每个节点有一个备份机。 redis主从复制 如果使用ruby搭建redis集群,从节点不用手动配置,ruby会自动分配
Redis集群至少需要6台服务器(3台是主节点,3台是对应的备份节点)。
搭建伪分布式。可以使用一台虚拟机运行6个redis实例。需要修改redis的端口号7001-7006
5.3.1. 集群搭建环境
1、使用ruby脚本搭建集群。需要ruby的运行环境。
安装ruby
yum install ruby
yum install rubygems
2、安装ruby脚本运行使用的包。
[root@localhost ~]# gem install redis-3.0.0.gem
Successfully installed redis-3.0.0
1 gem installed
Installing ri documentation for redis-3.0.0...
Installing RDoc documentation for redis-3.0.0...
[root@localhost ~]#
在redis解压文件夹的src目录下有一个redis-trib.rb文件之后需要用
[root@localhost ~]# cd redis-3.0.0/src
[root@localhost src]# ll *.rb
-rwxrwxr-x. 1 root root 48141 Apr 1 2015 redis-trib.rb
5.3.1. 搭建步骤
需要6台redis服务器。搭建伪分布式。
需要6个redis实例。
需要运行在不同的端口7001-7006
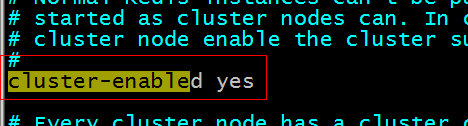
第一步:创建6个redis实例,将我们之前安装的redis中的bin目录拷贝六份,并改好名称.修改每个实例运行的端口。需要修改redis.conf配置文件。配置文件中还需要把cluster-enabled yes前的注释去掉(表示是支持集群)。
第二步:启动每个redis实例。这里可以创建一个sh脚本,运行脚本来启动六个redis
脚本内容如下
.
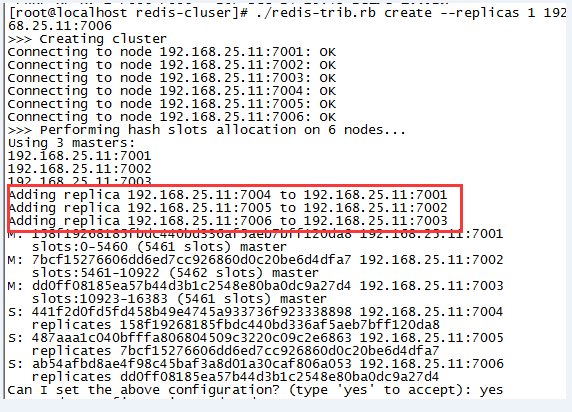
第三步:使用ruby脚本搭建集群。将redis解压文件夹的src目录下有一个redis-trib.rb文件复制到我们放redis集群的文件夹中,使用以下命令
--replicas 1 表示每个节点有一个备份机



./redis-trib.rb create --replicas 1 192.168.25.153:7001 192.168.25.153:7002 192.168.25.153:7003 192.168.25.153:7004 192.168.25.153:7005 192.168.25.153:7006
运行命令后

6. 集群的使用方法
redis连接集群(单机版的不用加参数 -c)
[root@localhost redis-cluster]# redis01/redis-cli -p 7002 -c -c:代表连接的是redis集群
redis连接redis单机版和集群版,点此 redis连接redis单机版和集群版
7.业务中使用redis进行缓存
redis不适用于大数据,适用于高并发的程序
1.查询内容列表时添加缓存。
1、查询数据库之前先查询缓存。
2、查询到结果,直接响应结果。
3、查询不到,缓存中没有需要查询数据库。
4、把查询结果添加到缓存中。
5、返回结果。
一般都使用hash数据类型,使用hash时,可以将保存的内容进行归类
INDEX_CONTENT分类
cid hash的字段
JsonUtils.objectToJson(tbContents) cid对应的值
jedisClient.hset(INDEX_CONTENT,cid+"", JsonUtils.objectToJson(tbContents));
2.缓存同步
我们在对数据库进行增删改的时候缓存中的数据没有变化,显然这种情况下,下一次查询出来的数据肯定错误,所以需要对缓存进行同步
对内容信息做增删改操作后只需要把对应缓存删除即可。
可以根据我们hash的字段来删除对应的缓存。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号