

20天机器学习(第一天)
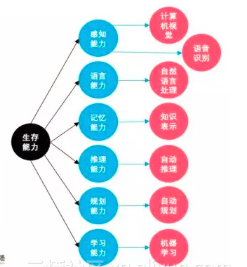
首先放上机器学习树形图
借鉴网址https://tianchi.aliyun.com/notebook-ai/detail?spm=5176.12282042.0.0.52bc2042UHrSQy&postId=6239
接下来的20天都是围绕这个树形图学习

第一天机器学习扫盲和数据分析入门
1. 人工智能的主要包含几个部分:
首先是感知,包括视觉、语音、语言;
然后是决策,例如做出预测和判断;
最后是反馈,如果想做一套完整的系统,就像机器人或是自动驾驶,则需要一个反馈。
2.机器学习的关键还是其学习能力:像人一样自主学习
3. 认识人工智能,还需要理清几个概念之间的关系:人工智能是一个大的概念,是让机器像人一样思考甚至超越人类;而机器学习是实现人工智能的一种方法,是使用算法来解析数据、从中学习,然后对真实世界中的事件做出决策和预测;深度学习是机器学习的一种实现方式,通过模拟人神经网络的方式来训练网络;而统计学是机器学习和神经网络的一种基础知识。

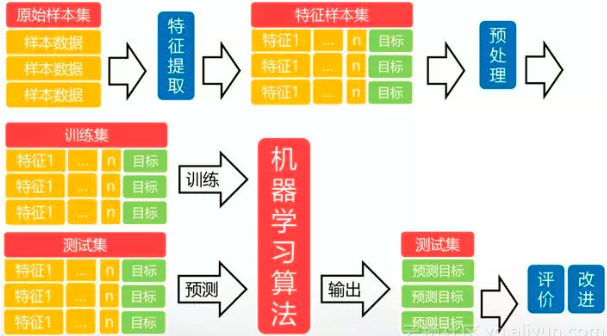
4.机器学习最大的特点是利用数据而不是指令来进行各种工作,其学习过程主要包括:数据的特征提取、数据预处理、训练模型、测试模型、模型评估改进等几部分。接下来我们重点介绍机器学习过程中的常见算法。
5.传统机器学习算法主要包括以下五类:
- 回归:建立一个回归方程来预测目标值,用于连续型分布预测
- 分类:给定大量带标签的数据,计算出未知标签样本的标签取值
- 聚类:将不带标签的数据根据距离聚集成不同的簇,每一簇数据有共同的特征
- 关联分析:计算出数据之间的频繁项集合
- 降维:原高维空间中的数据点映射到低维度的空间中
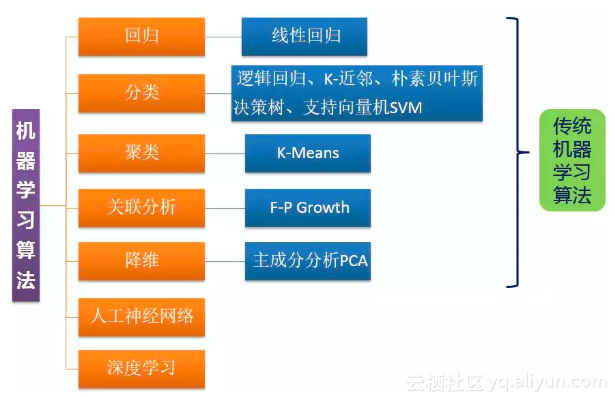
这几种方法主要还是运用的统计学的方法
下面我们将选取几种常见的算法,一一介绍
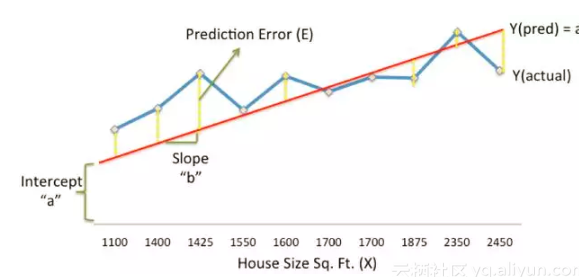
1.线性回归(回归方法的一种):找到一条直线来预测目标值
类似于一次方程(Y= a X + b)
2.逻辑回归:找到一条直线来分类数据
逻辑回归虽然名字叫回归,却是属于分类算法,是通过Sigmoid函数将线性函数的结果映射到Sigmoid函数中,预估事件出现的概率并分类。
Sigmoid是归一化的函数,可以把连续数值转化为0到1的范围,提供了一种将连续型的数据离散化为离散型数据的方法。
因此,逻辑回归从直观上来说是画出了一条分类线。位于分类线一侧的数据,概率>0.5,属于分类A;位于分类线另一侧的数据,概率<0.5,属于分类B。
例如图中通过计算患肿瘤的概率,将结果分类两类,分别位于逻辑分类线的两侧。

3.k-近邻:用距离度量最相邻的分类标签
一个简单的场景:已知一个电影中的打斗和接吻镜头数,判断它是属于爱情片还是动作片。当接吻镜头数较多时,根据经验我们判断它为爱情片。那么计算机如何进行判别呢?

可以使用K近邻算法,其工作原理如下:
- 计算样本数据中的点与当前点之间的距离
- 算法提取样本最相似数据(最近邻)的分类标签
- 确定前k个点所在类别的出现频率. 一般只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处,通常k是不大于20的整数
- 返回前k个点所出现频率最高的类别作为当前点的预测分类
电影分类场景中,k取值为3,按距离依次排序的三个点分别是动作片(108,5)、动作片(115,8)、爱情片(5,89)。在这三个点中,动作片出现的频率为三分之二,爱情片出现的频率为三分之一,所以该红色圆点标记的电影为动作片。
K近邻算法的一个常见应用是手写数字识别。手写字体对于人脑来说,看到的数字是一幅图像,而在电脑看来这是一个二维或三维数组,那怎么对数字进行识别?
使用K近邻算法的进行识别的具体步骤为:
- 首先将每个图片处理为具有相同的色彩和大小:宽高是32像素x32像素。
- 将3232的二进制图像矩阵转换成11024的测试向量。
- 将训练样本储存在训练矩阵中,创建一个m行1024列的训练矩阵,矩阵的每行数据存储一个图像。
- 计算目标样本与训练样本的距离,选择前k个点所出现频率最高的数字作为当前手写字体的预测分类。
标红的我也没太懂,属于图像识别的,接下来还有图像识别,以后会细讲。
4.朴素贝叶斯:选择后验概率最大的类为分类标签
一个简单的场景:一号碗(C1)有30颗水果糖和10颗巧克力糖,二号碗(C2)有水果糖和巧克力糖各20颗。现在随机选择一个碗,从中摸出一颗糖,发现是水果糖。
问这颗水果糖(X)最有可能来自哪个碗?这类问题可以借助贝叶斯公式来计算,不需要针对目标变量建立模型。在分类时,通过计算样本属于各个类别的概率,然后取概率值大的类别作为分类类别。
P(X|C): 条件概率,C中X出现的概率
P(C): 先验概率,C出现的概率
P(C|X): 后验概率,X属于C类的概率
假设有 C1 和 C2 两个类,由于 P(X)都是一样的,所以不需要考虑 P(X) 只需考虑如下:
如果 P(X|C1)P(C1) > P(X|C2)P(C2),则 P(C1|X) > P(C2|X),得 X 属于C1;
如果 P(X|C1) P(C1) < P(X|C2) P(C2),则 P(C2|X) < P(C2|X),得 X 属于C2。
例如上面的例子中: P(X): 水果糖的概率为5/8
P(X|C1): 一号碗中水果糖的概率为3/4
P(X|C2): 二号碗中水果糖的概率为2/4
P(C1)=P(C2): 两个碗被选中的概率相同,为1/2
则水果糖来自一号碗的概率为:
$P(C1|X)=P(X|C1)P(C1)/P(X)=(3/4)(1/2)/(5/8)=3/5
水果糖来自二号碗的概率为:
P(C2|X)=P(X|C2)P(C2)/P(X)=(2/4)(1/2)/(5/8)=2/5
P(C1|X)>P(C2|X)
因此这颗糖最有可能来自一号碗。
朴素贝叶斯的主要应用有文本分类、垃圾文本过滤,情感判别,多分类实时预测等
贝叶斯公式又叫概率公式,主要是靠概率来分类的
5.决策树:构造一棵熵值下降最快的分类树
一个简单的场景
相亲时,可能首先检测相亲对方是否有房。如果有,则考虑进一步接触。如果没有房,则观察其是否有上进心,如果没有,直接Say Goodbye。如果有,则可以列入候选名单。
这就是一个简单的决策树模型。决策树是一种树型结构,其中每个内部结点表示在一个属性上的测试,每个分支代表一个测试输出,每个叶结点代表一种类别。采用的是自顶向下的递归方法,选择信息增益最大的特征作为当前的分裂特征。
决策树可以应于:用户分级评估、贷款风险评估、选股、投标决策等
6.支持向量机(svm)构造超平面,分类非线性数据
一个简单的场景:
要求用一根线将不同颜色的球分开,要求尽量在放更多球之后,仍然适用。 A、B两条线都可以满足条件。再继续增加球,线A仍可以将球很好的分开,而线B则不可以。
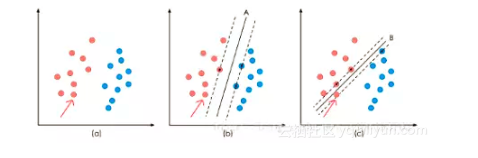
这个场景中涉及支持向量机的的两个问题:
- 当一个分类问题,数据是线性可分时,只要将线的位置放在让小球距离线的距离最大化的位置即可,寻找这个最大间隔的过程,就叫做最优化。
- 一般的数据是线性不可分的,可以通过核函数,将数据从二维映射到高位,通过超平面将数据切分。
不同方向的最优决策面的分类间隔通常是不同的,那个具有“最大间隔”的决策面就是SVM要寻找的最优解。这个真正的最优解对应的两侧虚线所穿过的样本点,就是SVM中的支持样本点,称为支持向量。
SVM的应用非常广泛,可以应用于垃圾邮件识别、手写识别、文本分类、选股等。
这个我也没看懂,后面应该也会讲。
7. K-means:计算质心,聚类无标签数据
8. 关联分析:挖掘啤酒与尿布(频繁项集)的关联规则
9. PCA降维:减少数据维度,降低数据复杂度¶
10. 人工神经网络:逐层抽象,逼近任意函数
11. 深度学习:赋予人工智能以璀璨的未来¶
后面这几条都是比较复杂的,我目前都还不懂,之后在研究
深度学习是机器学习的分支,是对人工神经网络的发展。深度学习是当今人工智能爆炸的核心驱动,赋予人工智能以璀璨的未来。
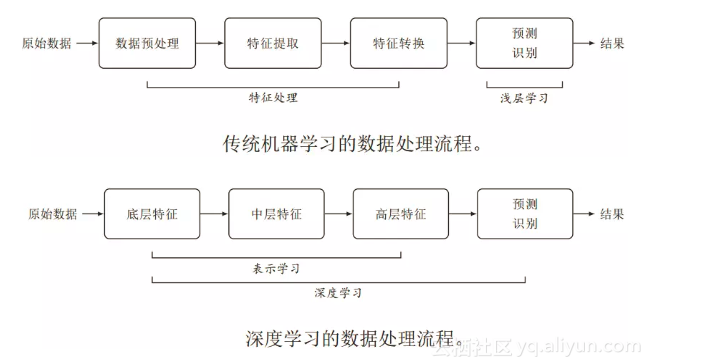
看一下深度学习与传统机器学习的区别。传统机器学习特征处理和预测分开,特征处理一般需要人工干预完成。这类模型称为浅层模型,或浅层学习,不涉及特征学习,其特征主要靠人工经验或特征转换方法来抽取

 浙公网安备 33010602011771号
浙公网安备 33010602011771号