python中的CodeObject
前言:python中的CodeObject笔记,然后来记录分析bytecode的笔记
参考文章:https://www.bilibili.com/video/BV12i4y1C7MH
什么是CodeObject
只要我们在python中编写的所有代码,都会在运行的时候其中代码会被编译器编译为CodeObject对象
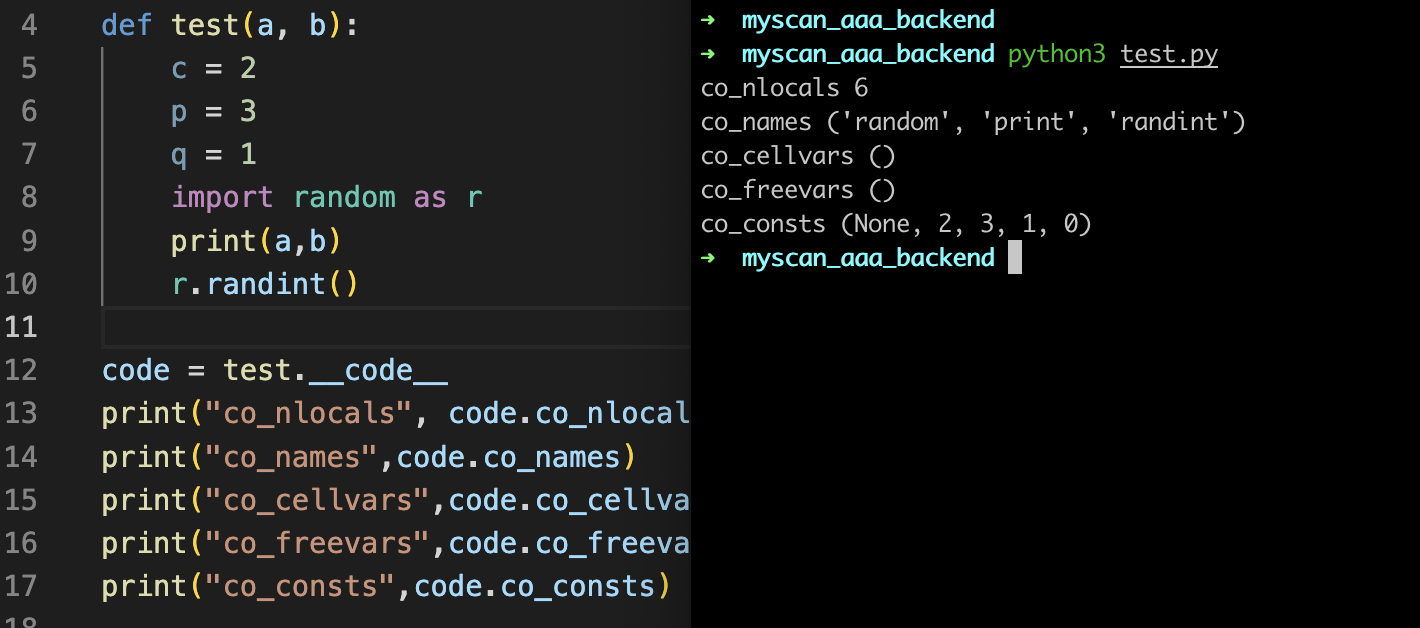
这里简单的写个例子查看,可以看到该定义的test函数的__code__属性表示的就是一个CodeObject对象
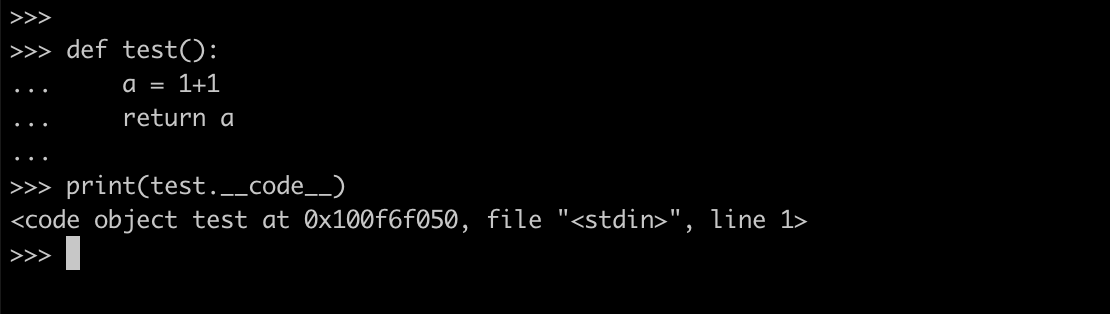
那么可能会有一个问题为什么打印的是__code__属性?实际上这里__code__属性代表的是当前要执行的bytecode,也就是对应的CodeObject对象,在cpython运行的时候需要的就是这段bytecode
如果详细的看__code__对象(CodeObject),这里可以通过dir方法来查看对应的属性

还可以通过inspect文档来具体的学习各个属性的意思, 参考文档: https://docs.python.org/zh-cn/3/library/inspect.html

co_name,co_filename,co_lnotab
import dis
def test():
a = 2
print(a)
code = test.__code__
print(code.co_name)
print(code.co_filename)
print(code.co_lnotab)
这三个属性值都是辅助数据,co_name和co_filename和co_lnotab分别代表的就是函数名称以及文件名称和编码的行号到字节码索引的映射
其中co_lnotab是根据一定的算法来进行压缩的,具体可以参考 https://github.com/python/cpython/blob/9f8f45144b6f0ad481e80570538cce89b414f7f9/Objects/lnotab_notes.txt
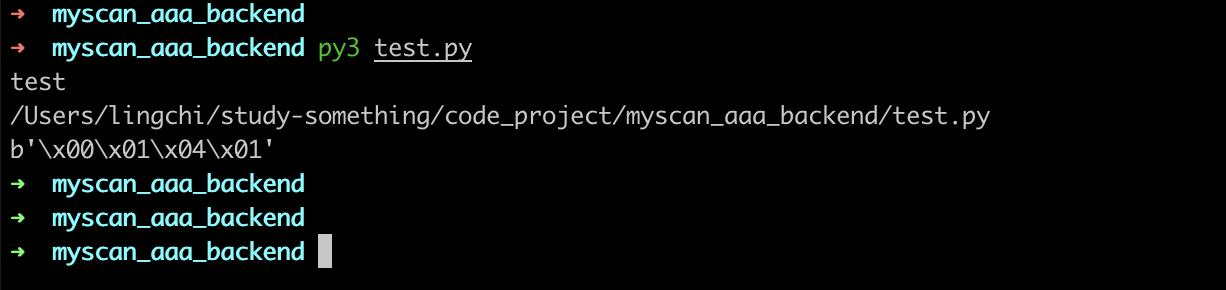
co_flags和co_stacksize
co_flags用来描述当前函数的形式的标识位,它可能代表的是不同的含义,比如正常函数和生成器函数,那么情况就可能就不一样

这里分别实现两个函数,一个是正常的func,另外一个是generator函数,此时的情况就不一样
# coding=utf-8
import dis
def test():
a = 2
return a+a
def test_yield():
for _ in range(100):
yield _
print(test.__code__.co_flags)
print(test_yield.__code__.co_flags)

co_stacksize代表的就是当前函数执行需要虚拟机堆栈空间
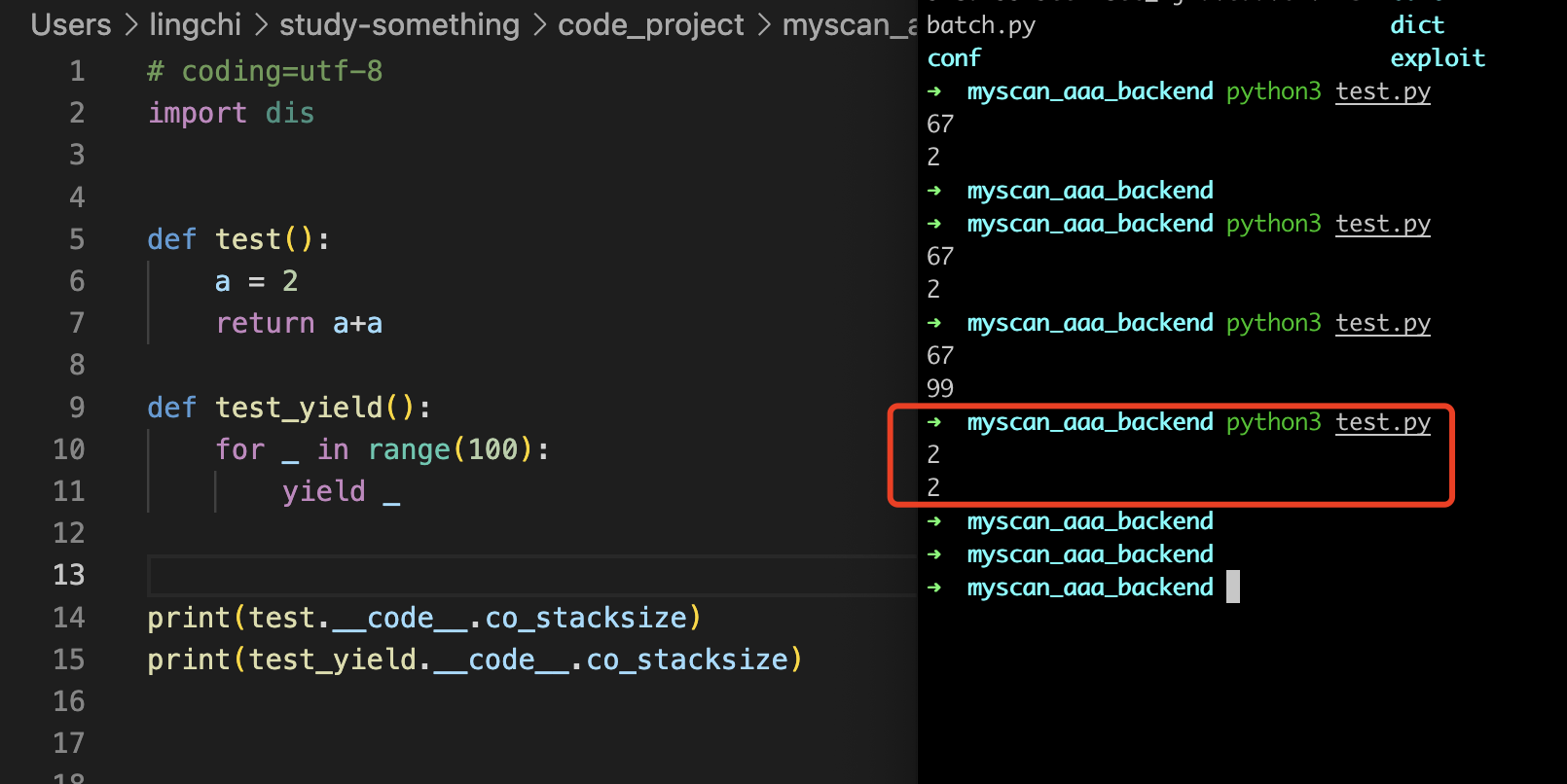
co_argcount co_posonlyargcount co_kwonlyargcount
co_argcount:参数数量(不包括仅关键字参数、* 或 ** 参数)
co_posonlyargcount:仅限位置参数的数量
co_kwonlyargcount:仅限关键字参数的数量(不包括 ** 参数)
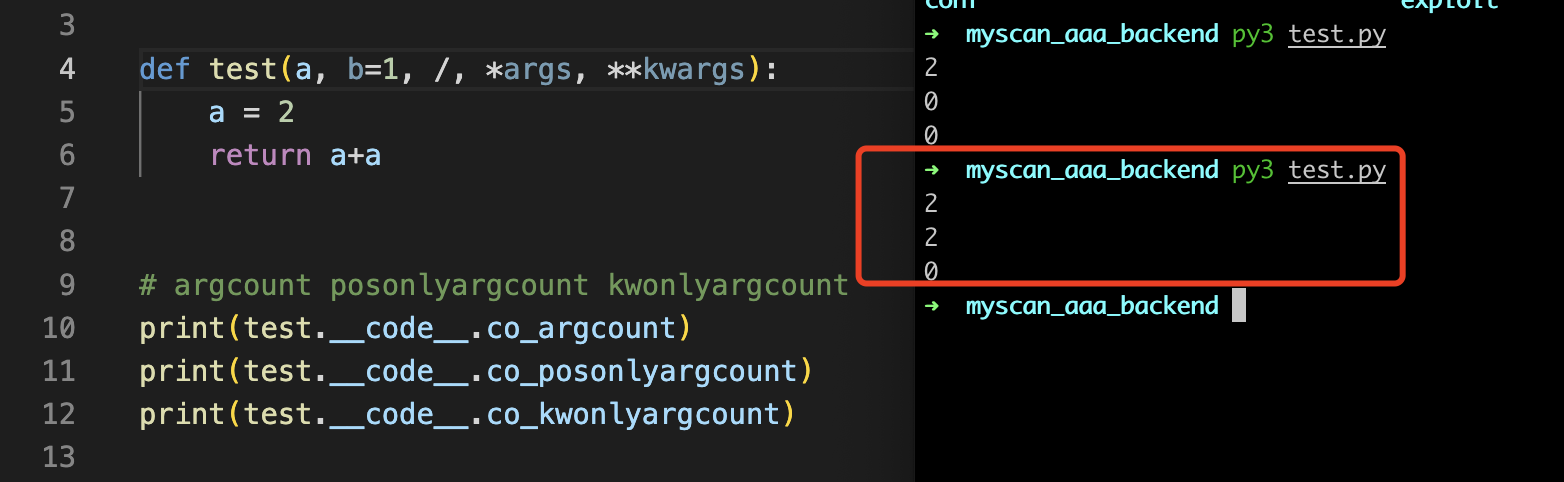
那么这个的话,简单的例子如下,可以看到结果分别是 2 0 0,argcount比较好理解,很明显参数数量就是2个,所以这边输出的话就是2
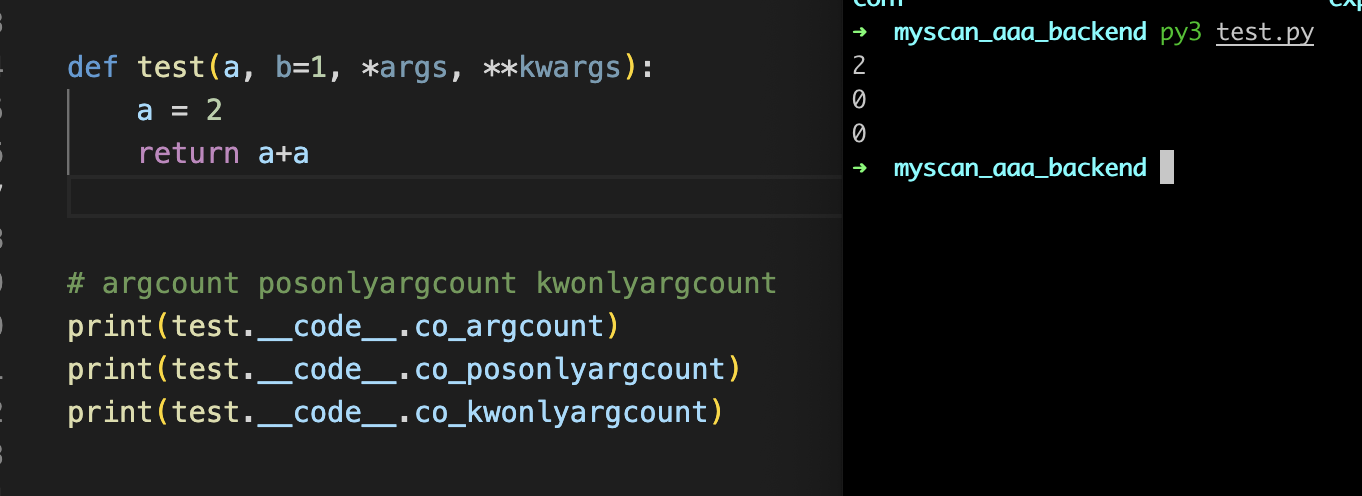
但是这边的co_posonlyargcount如何理解呢?其实这个co_posonlyargcount还需要配合/标志符来进行学习
如果这边的test函数加上/的话,那么结果的话就不一样了,可以看到结果就是2 2 0,因为在/前面需要传递两个的位置参数
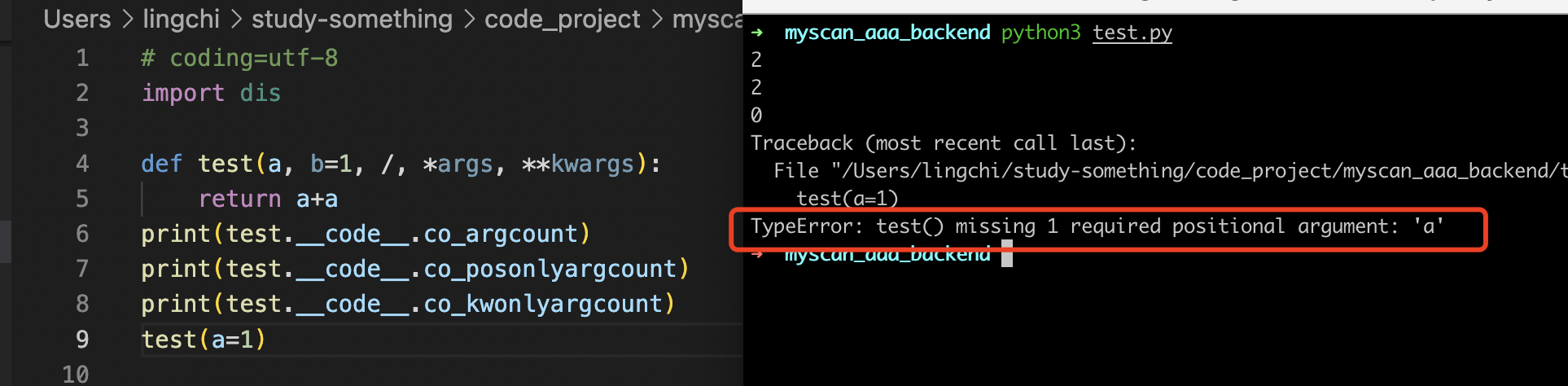
此时我们如果传递的是test(a=1)的话,那么会进行报错,因为此时的test函数中的形参a,b都是posonlyarg,所以不能通过test(a=1)来进行实现
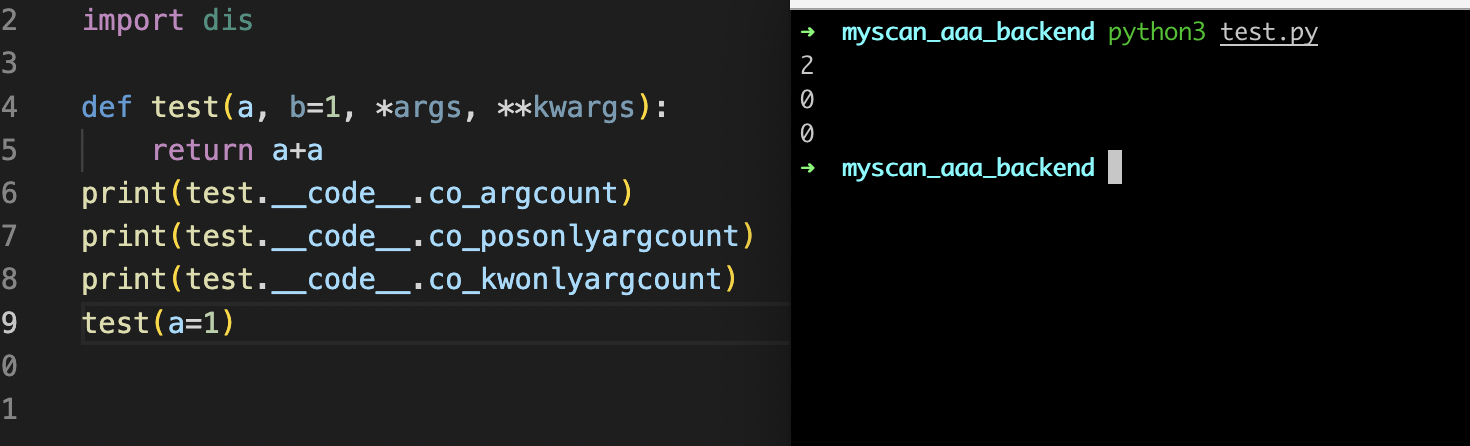
如果这里/去掉的话就可以了
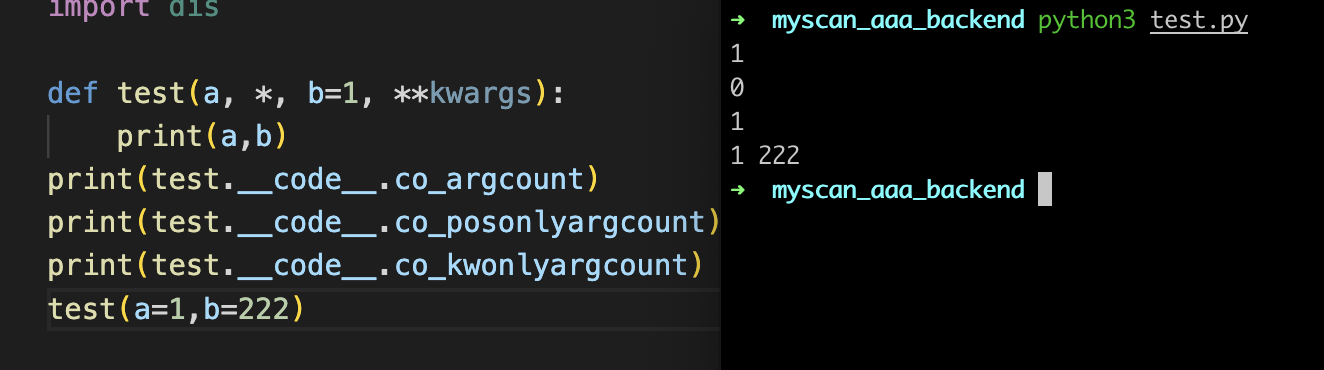
co_kwonlyargcount也是类似,需要配合*标志符,此时的*标志代表的就是args,此时的起到的分割作用,代表此时co_kwonlyargcount的数量为1
小总结:对于* 和 /的用法就是一个规范限制的作用,这里了解即可
co_nlocals co_names
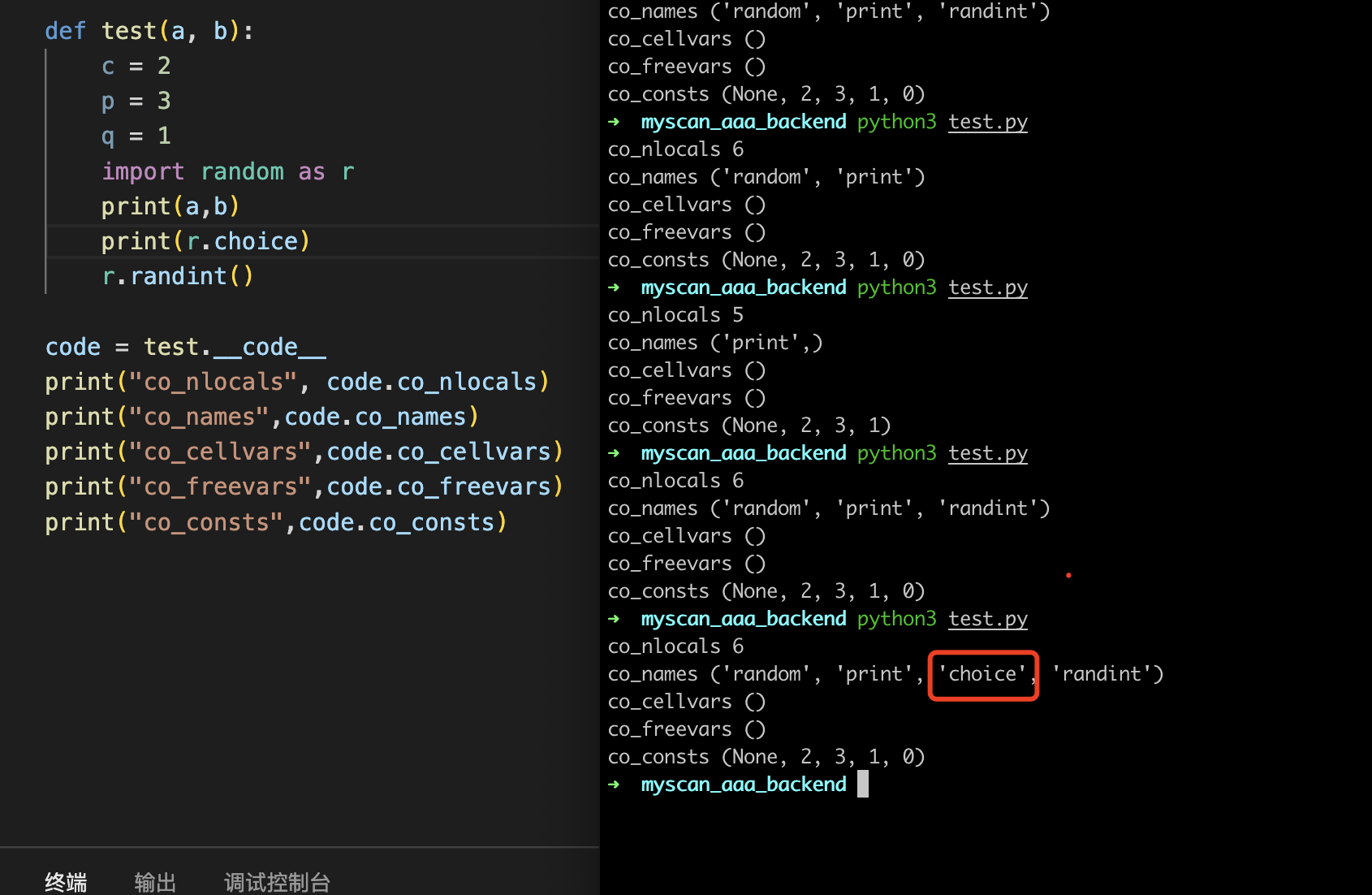
co_nlocal:局部变量的数量,这边的话就是6个,分别是a,b,c,p,q,random模块
其实这边是有一个设计思想的,如果变量名无限制的长那么非常影响效率,所以这边的话是通过对应顺序的下标来进行识别,0的话那么就直接对应a,以此类推即可
co_names:除参数和函数局部变量之外的名称元组,那这边可以看到一般都是方法的名称
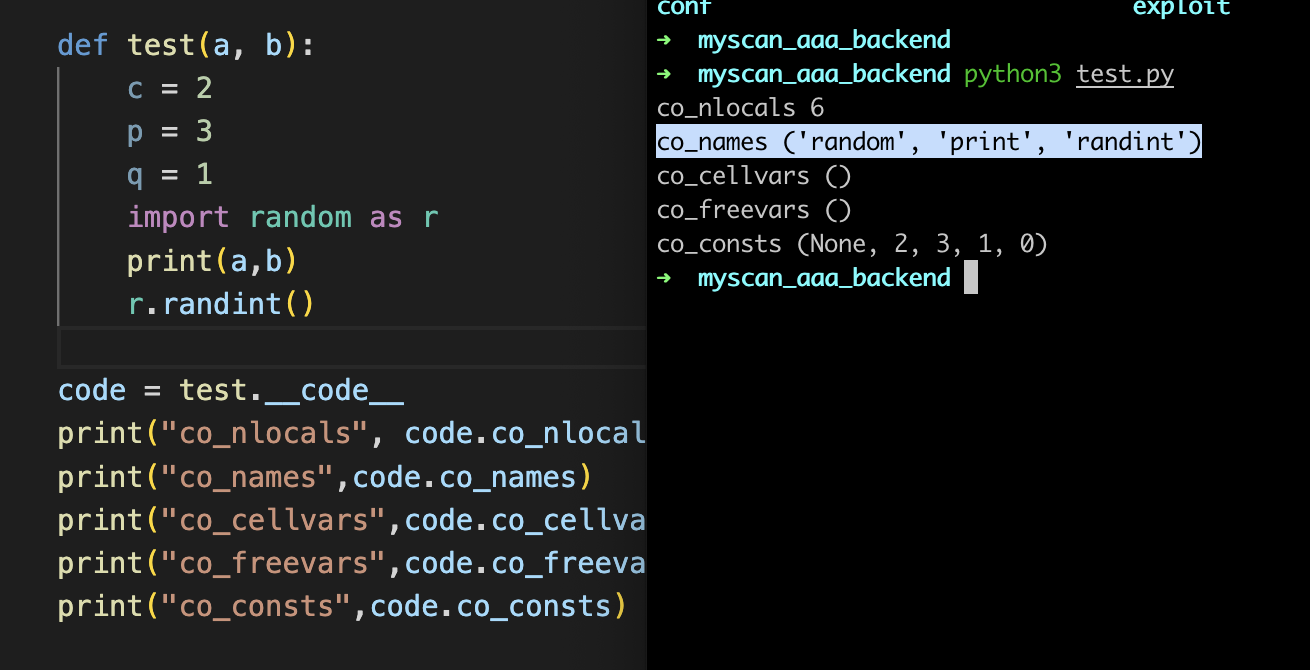
除了方法的名称以外的话,属性名称都会被记录在到co_names
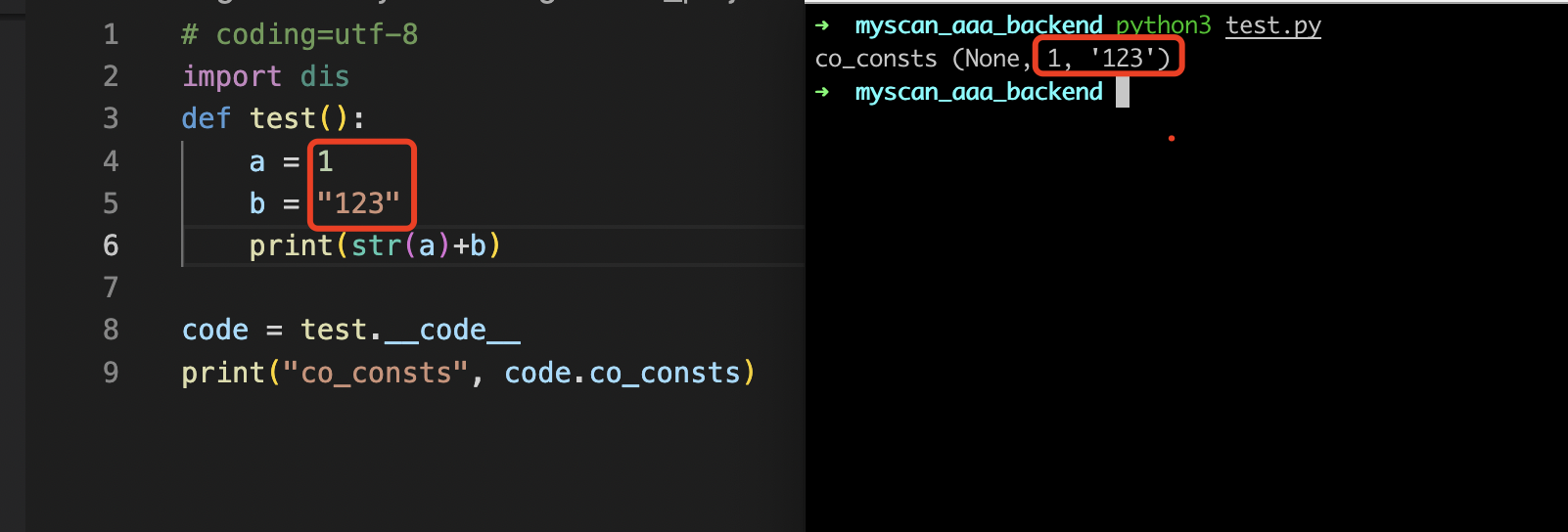
co_consts
co_const:字节码中使用的常量元组
如下图所示,可以看到变量的值都会在这里进行存储
co_cellvars和co_freevars
co_cellvars:单元变量名称的元组(通过包含作用域引用)
co_freevars:自由变量的名字组成的元组(通过函数闭包引用)
这里可以写一个闭包的函数来进行观察,当变量aasd作为闭包函数中操作的变量,在外部函数和闭包函数中的打印结果是不一样的,如果在外部函数的话则出现在co_cellvars,闭包函数中则出现在co_freevars
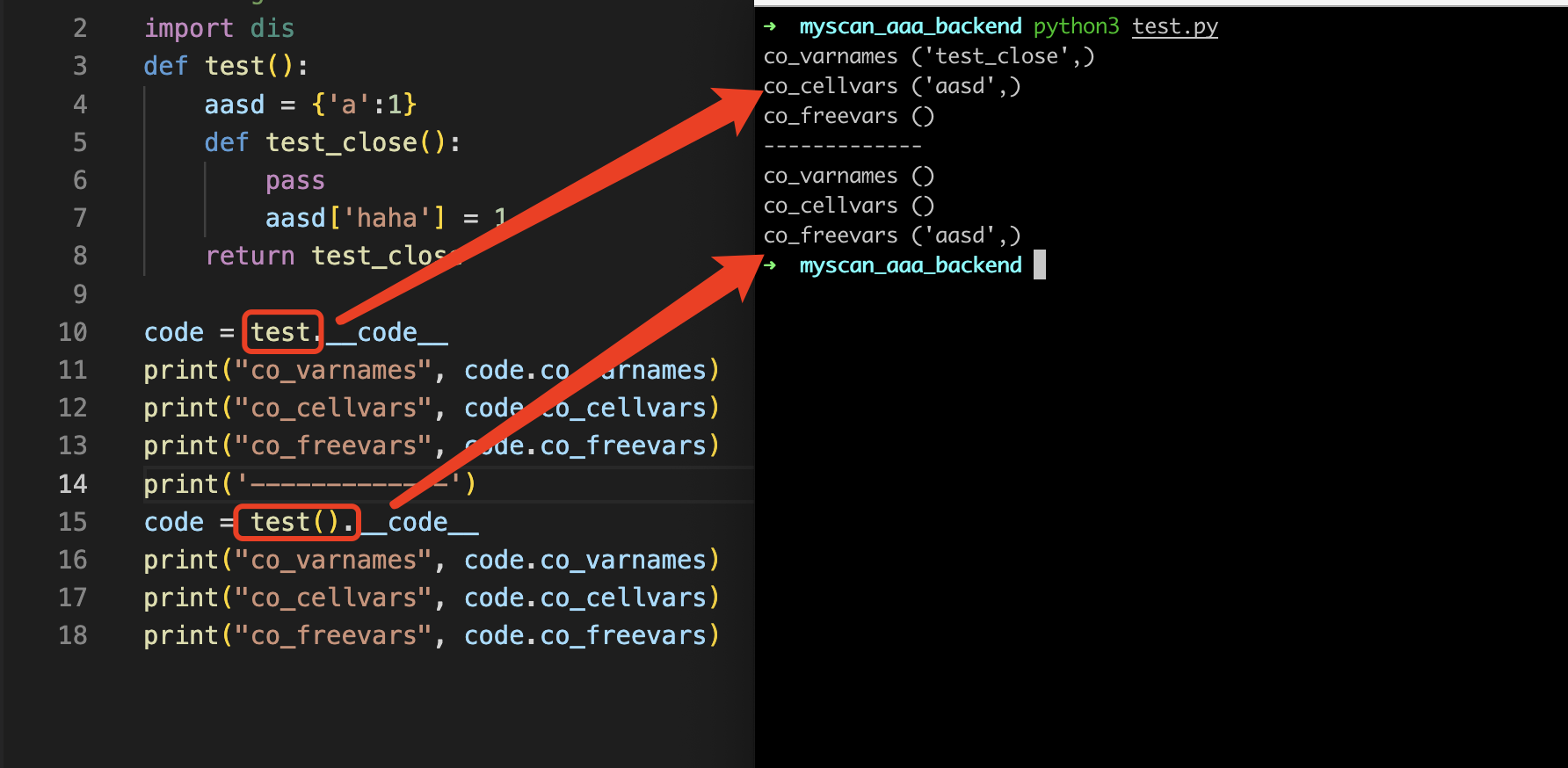
总结:co_cellvars和co_freevars常在闭包中成对出现,co_freevars表示用到了scope之外的变量,co_cellvars表示变量被其他scope使用
bytecode如何被执行的
在Python/ceval.c文件中的_PyEval_EvalFrameDefault函数中,最关键的代码就是一个主循环,这个主循环的作用是不停的解析每一个收到的字节码,直到遇到退出条件
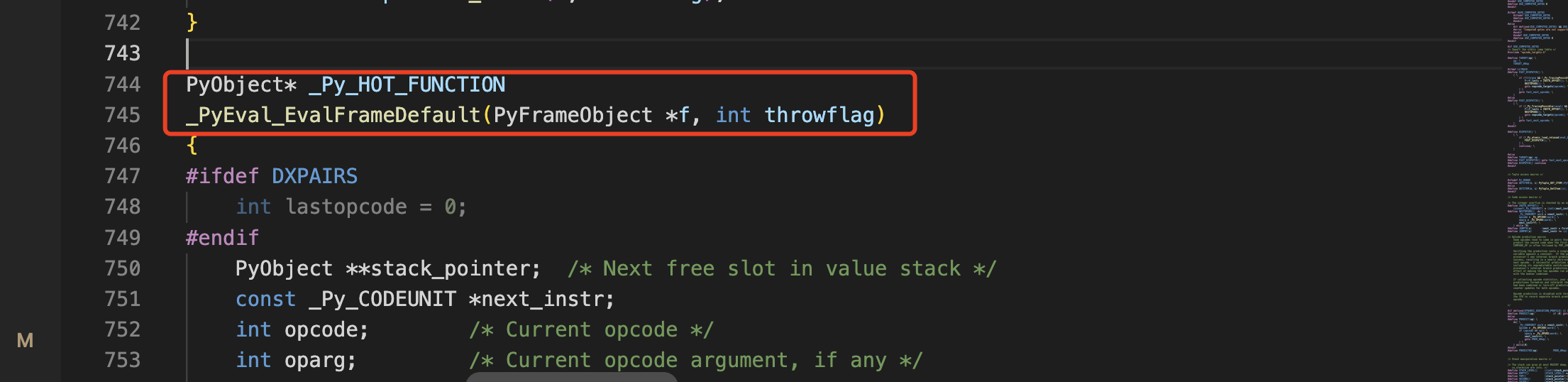
这个主循环的关键部分是一个巨大的switch语句,针对不同opcode跳转到不同的代码段进行执行,这是非常核心的一段代码。
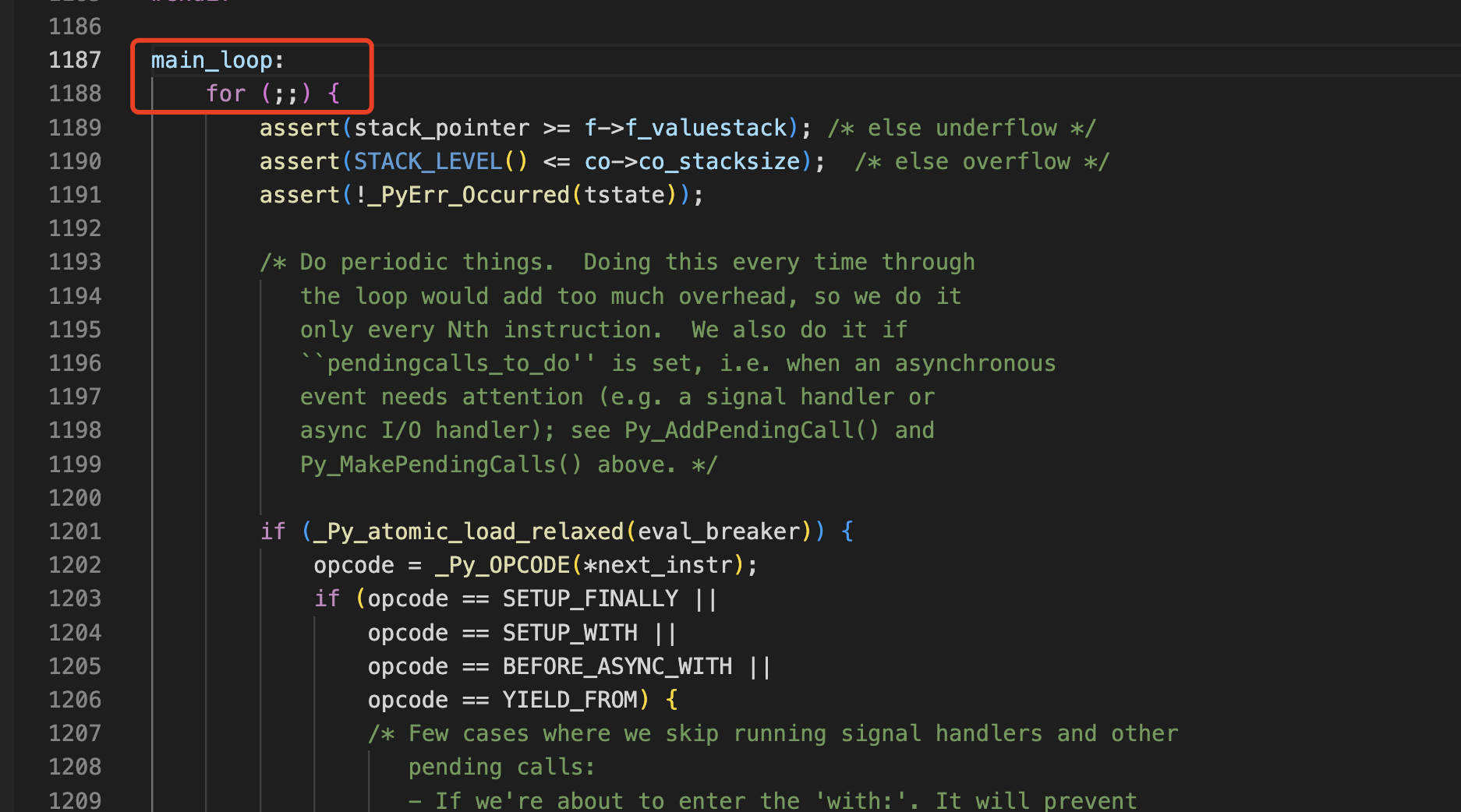
继续往下走可以看到很多switch的分支,对于各个opcode的处理流程
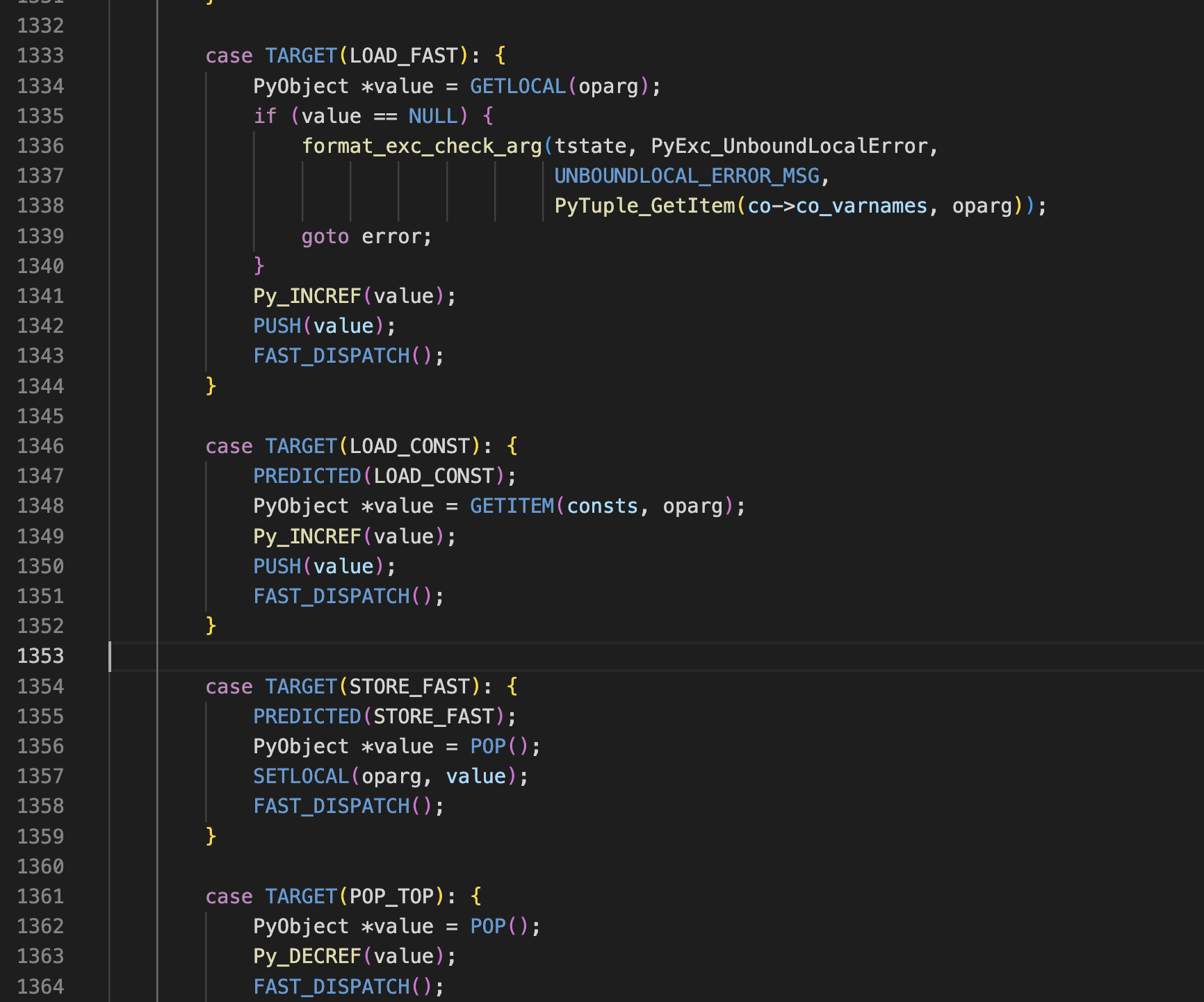
阅读dis模块反编译字节码
上面了解了相关的CodeObject的知识之后,这边可以简单的阅读部分反编译字节码的代码
opcode参考文档:https://docs.python.org/zh-cn/3/library/dis.html
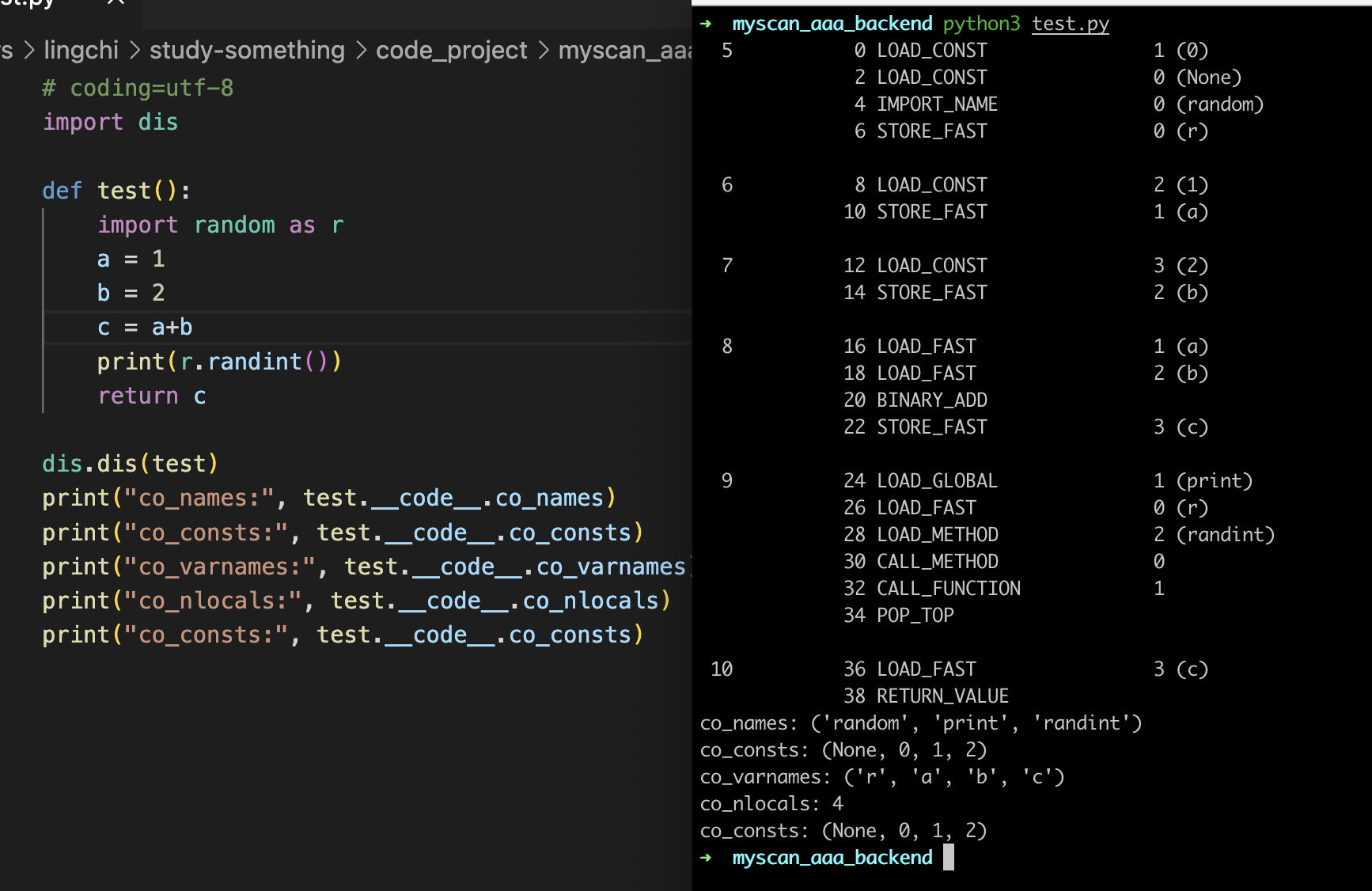
0-6索引执行的就是
-
LOAD_CONST将co_consts[1] 压入栈,LOAD_CONST将co_consts[0] 压入栈,对应的值就是'0' 和 'None'
-
再接着就是IMPORT_NAME导入random模块,压入栈,然后STORE_FAST存储到co_varnames[0],对应也就是'r'中
5 0 LOAD_CONST 1 (0)
2 LOAD_CONST 0 (None)
4 IMPORT_NAME 0 (random)
6 STORE_FAST 0 (r)
8-10 索引执行的是
- LOAD_CONST将co_consts[2] 压入栈,对应的值就是1,接着通过STORE_FAST将栈顶的值1赋值给a变量
6 8 LOAD_CONST 2 (1)
10 STORE_FAST 1 (a)
12-14 索引执行的是
- LOAD_CONST将co_consts[3] 压入栈,对应的值就是2,接着通过STORE_FAST将栈顶的值2赋值给b变量
7 12 LOAD_CONST 3 (2)
14 STORE_FAST 2 (b)
16-22 索引执行的是
- 通过两次LOAD_FAST将对应的a变量和b变量压入栈,再通过BINARY_ADD将其栈顶前两个存储的值相加赋值给栈顶中,最后通过STORE_FAST将栈顶的值赋值给变量c
8 16 LOAD_FAST 1 (a)
18 LOAD_FAST 2 (b)
20 BINARY_ADD
22 STORE_FAST 3 (c)
24-38 索引执行的是
- 将print函数压入到栈,co_varnames[0]对应的random模块也压入栈中,然后通过LOAD_METHOD获取栈顶random模块,然后获取其中random的randint方法,将当前栈顶设置为randint方法,然后继续压入random模块,然后通过CALL_METHOD拿到randint方法进行调用(这个CALL_METHOD拿的不是栈顶,而是栈顶的下一个),接着弹出栈顶的random模块,压入randint的值,
然后CALL_FUNCTION调用1,此时CALL_FUNCTION会将当前栈顶的值拿出来进行print,打印完的返回值又压入到栈中,然后POP_TOP弹出,最后再压入3作为返回值结束
9 24 LOAD_GLOBAL 1 (print)
26 LOAD_FAST 0 (r)
28 LOAD_METHOD 2 (randint)
30 CALL_METHOD 0
32 CALL_FUNCTION 1
34 POP_TOP
10 36 LOAD_FAST 3 (c)
38 RETURN_VALUE
这里的CALL_METHOD和CALL_FUNCTION我可能没解释清楚,我是按照cpython的源码来解释的,解释是对的上的,具体可以参考上面提及的/Python/ceval.c部分
case TARGET(LOAD_METHOD): {
/* Designed to work in tandem with CALL_METHOD. */
PyObject *name = GETITEM(names, oparg);
PyObject *obj = TOP();
PyObject *meth = NULL;
int meth_found = _PyObject_GetMethod(obj, name, &meth);
if (meth == NULL) {
/* Most likely attribute wasn't found. */
goto error;
}
if (meth_found) {
/* We can bypass temporary bound method object.
meth is unbound method and obj is self.
meth | self | arg1 | ... | argN
*/
SET_TOP(meth);
PUSH(obj); // self
}
else {
/* meth is not an unbound method (but a regular attr, or
something was returned by a descriptor protocol). Set
the second element of the stack to NULL, to signal
CALL_METHOD that it's not a method call.
NULL | meth | arg1 | ... | argN
*/
SET_TOP(NULL);
Py_DECREF(obj);
PUSH(meth);
}
DISPATCH();
}
case TARGET(CALL_METHOD): {
/* Designed to work in tamdem with LOAD_METHOD. */
PyObject **sp, *res, *meth;
sp = stack_pointer;
meth = PEEK(oparg + 2);
if (meth == NULL) {
/* `meth` is NULL when LOAD_METHOD thinks that it's not
a method call.
Stack layout:
... | NULL | callable | arg1 | ... | argN
^- TOP()
^- (-oparg)
^- (-oparg-1)
^- (-oparg-2)
`callable` will be POPed by call_function.
NULL will will be POPed manually later.
*/
res = call_function(tstate, &sp, oparg, NULL);
stack_pointer = sp;
(void)POP(); /* POP the NULL. */
}
else {
/* This is a method call. Stack layout:
... | method | self | arg1 | ... | argN
^- TOP()
^- (-oparg)
^- (-oparg-1)
^- (-oparg-2)
`self` and `method` will be POPed by call_function.
We'll be passing `oparg + 1` to call_function, to
make it accept the `self` as a first argument.
*/
res = call_function(tstate, &sp, oparg + 1, NULL);
stack_pointer = sp;
}
PUSH(res);
if (res == NULL)
goto error;
DISPATCH();
}
case TARGET(CALL_FUNCTION): {
PREDICTED(CALL_FUNCTION);
PyObject **sp, *res;
sp = stack_pointer;
res = call_function(tstate, &sp, oparg, NULL);
stack_pointer = sp;
PUSH(res);
if (res == NULL) {
goto error;
}
DISPATCH();
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号