

大规模搜索广告的端到端一致性实时保障
一、背景
电商平台的搜索广告数据处理链路通常较长,一般会经历如下过程:

- 广告主在后台进行广告投放;
- 投放广告品及关键词数据写入数据库;
- 数据库中的数据通过全量构建(导入数据仓库再进行离线批处理)或增量构建(借助消息队列和流计算引擎)的方式产出用于构建在线索引的“内容文件”;
- BuildService基于“内容文件”,构建出在搜索服务检索时使用的索引。
下图是ICBU的广告系统的买卖家数据处理链路:
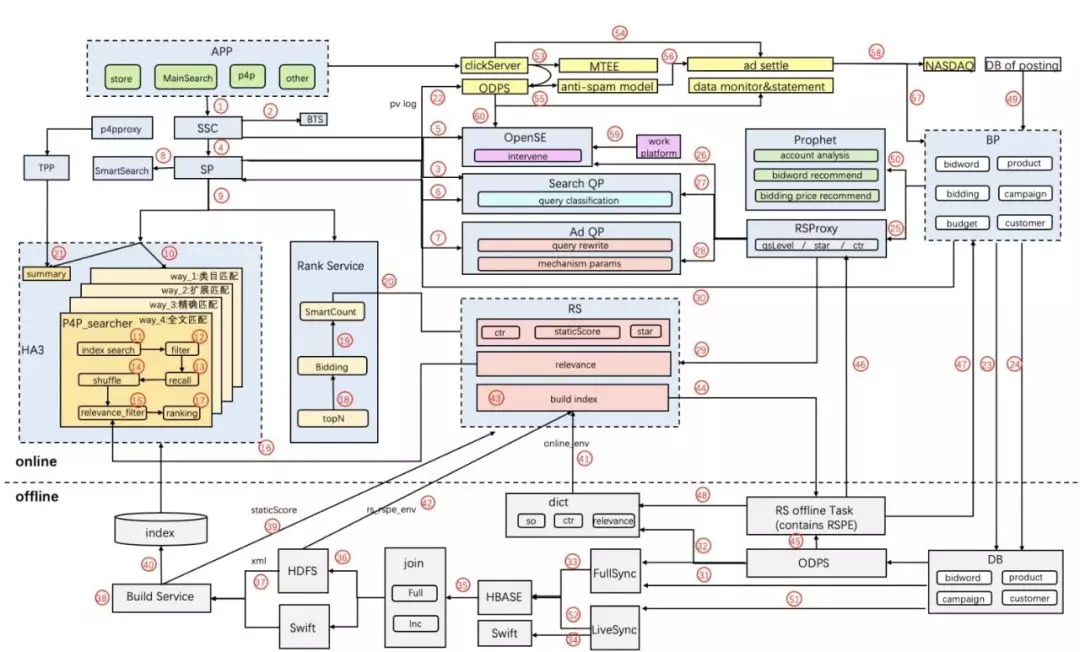
右半部分(BP->DB)和offline部分即为广告投放数据的更新过程。
复杂的数据处理链路结合海量(通常是亿级以上)的商品数据,对线上全量商品的投放状态正确性测试提出巨大挑战。从数据库、到离线大规模数据联表处理、到在线索引构建,链路中的任一节点出现异常或数据延迟,都有可能会对广告主以及平台造成“资损”影响,例如:
- 广告主在后台操作取消A商品的广告投放,但是因为数据链路处理延迟,搜索引擎中A的状态仍处于“推广中”,导致A能继续在买家搜索广告时得到曝光,相应地当“点击”行为发生时,造成错误扣款。
- 广告主设定某个产品只限定对某个地域/国家的客户投放广告,但是因为搜索引擎的过滤逻辑处理不恰当,导致客户的广告品在所有地区都进行广告投放,同样会造成错误点击扣款。
传统的测试手段,或聚焦于广告主后台应用的模块功能测试,或聚焦于搜索引擎的模块功能测试,对于全链路功能的测试缺乏有效和全面的测试手段。而线上的业务监控,则侧重于对业务效果指标的监控,如CTR(click through rate,点击率)、CPC(cost per click,点击成本)、RPM(revenue per impression,千次浏览收益)等。对涉及广告主切身利益和平台总营收的广告错误投放问题,缺乏有效的发现机制。
我们期望对在线搜索广告引擎所有实际曝光的商品,通过反查数据库中曝光时刻前它的最后状态,来校验它在数据库中的投放状态与搜索引擎中的状态的一致性,做到线上广告错误投放问题的实时发现。同时,通过不同的触发检测方式,做到数据变更的各个环节的有效覆盖。
二、阶段成果
我们借助日志流同步服务(TTLog)、海量数据NoSQL存储系统(Lindorm)、实时业务校验平台(BCP)、消息队列(MetaQ)、在线数据实时同步服务(精卫)以及海量日志实时分析系统(Xflush)实现了ICBU搜索广告错误投放问题的线上实时发现,且覆盖线上的全部用户真实曝光流量。同时,通过在数据变更节点增加主动校验的方式,可以做到在特定场景下(该广告品尚未被用户检索)的线上问题先于用户发现。
此外,借助TTLog+实时计算引擎Blink+阿里云日志服务SLS+Xflush的技术体系,实现了线上引擎/算法效果的实时透出。
下面是ICBU广告实时质量大盘:
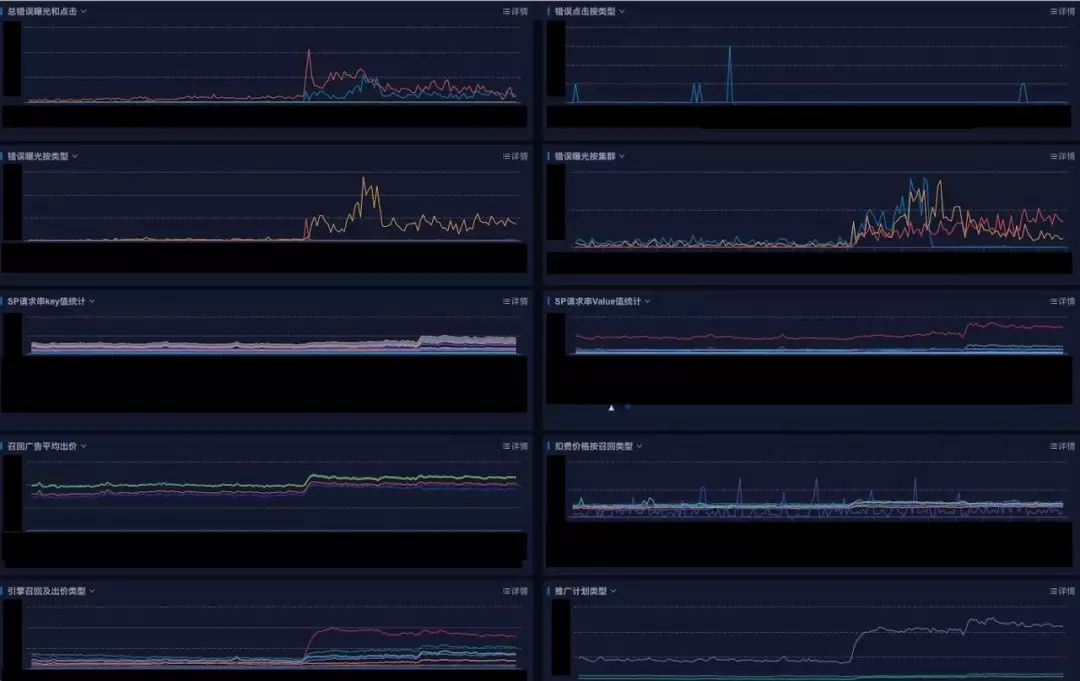
从八月底开始投入线上使用,目前这套实时系统已经发现了多起线上问题,且几乎都是直接影响资损和广告主的利益。
三、技术实现
图一:
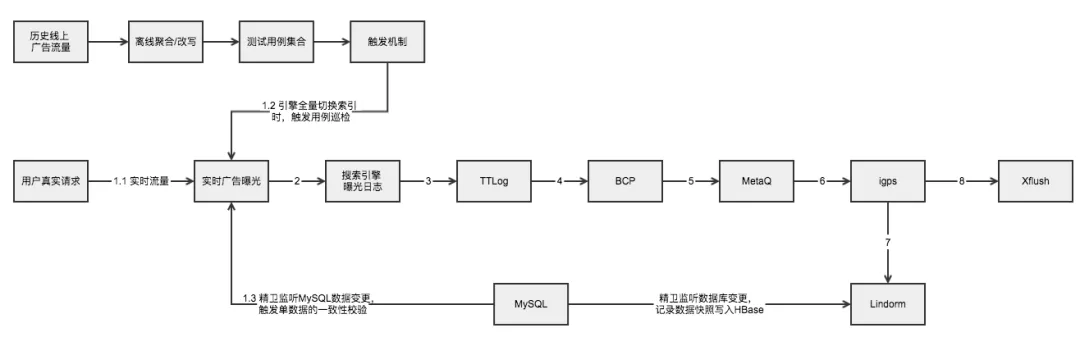
1. 引擎曝光日志数据处理
对于电商搜索广告系统,当一个真实的用户请求触达(如图一中1.1)时,会产生一次实时的广告曝光,相对应地,搜索引擎的日志里会写入一条曝光记录(如图一中2)。我们通过日志流同步服务TTLog对搜索引擎各个服务器节点上的日志数据进行统一的搜集(如图一中3),然后借助数据对账服务平台BCP对接TTLog中的“流式”数据(如图一中4),对数据进行清洗、过滤、采样,然后将待校验的数据推送到消息队列服务MetaQ(如图一中5)。
2. DB数据处理
图二:
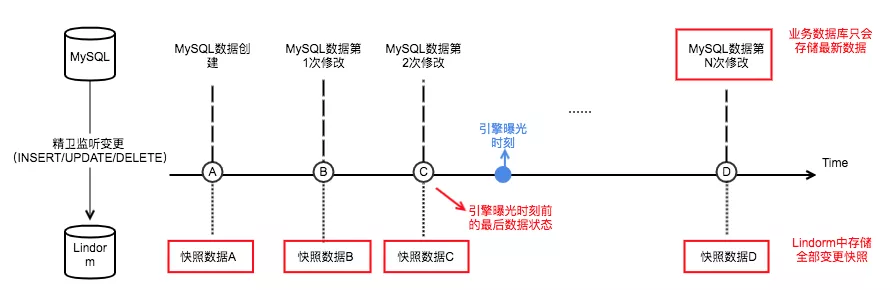
如图二所示,通常,业务数据库MySQL针对每个领域对象,只会存储它当前时刻最新的数据。为了获取广告品在引擎中真实曝光的时刻前的最后数据,我们通过精卫监听数据库中的每次数据变更,将变更数据“快照”写入Lindorm(底层是HBase存储,支持海量数据的随机读写)。
3. 数据一致性校验
在广告测试服务igps(我们自己的应用)中,我们通过监听MetaQ的消息变更,拉取MetaQ中待校验的数据(如图一中6),解析获得曝光时每个广告品在搜索引擎中的状态,同时获得其曝光的时刻点。然后基于曝光时刻点,通过查询Lindorm,获得广告品于曝光时刻点前最后在MySQL中的数据状态(如图一中7)。然后igps对该次广告曝光,校验引擎中的数据状态和MySQL中的数据状态的一致性。
如果数据校验不一致,则打印出错误日志。最后,借助海量日志实时分析系统Xflush(如图一中8),我们可以做到对错误数据的实时聚合统计、可视化展示以及监控报警。
4. 数据变更节点的主动校验
因为线上的实时用户搜索流量具有一定的随机性,流量场景的覆盖程度具有很大的不确定性,作为补充,我们在数据变更节点还增加了主动校验。
整个数据链路,数据变更有两个重要节点:
- MySQL中的数据变更;
- 引擎索引的切换。
对于MySQL中的数据变更:我们通过精卫监听变更,针对单条数据的变更信息,构建出特定的引擎查询请求串,发起查询请求(如图一中1.3)。
对于引擎索引的切换(主要是全量切换):我们通过离线对历史(如过去7天)的线上广告流量进行聚合分析/改写,得到测试用例请求集合。再监听线上引擎索引的切换操作。当引擎索引进行全量切换时,我们主动发起对引擎服务的批量请求(如图一中1.2)。
上述两种主动发起的请求,最后都会复用前面搭建的数据一致性校验系统进行广告投放状态的校验。
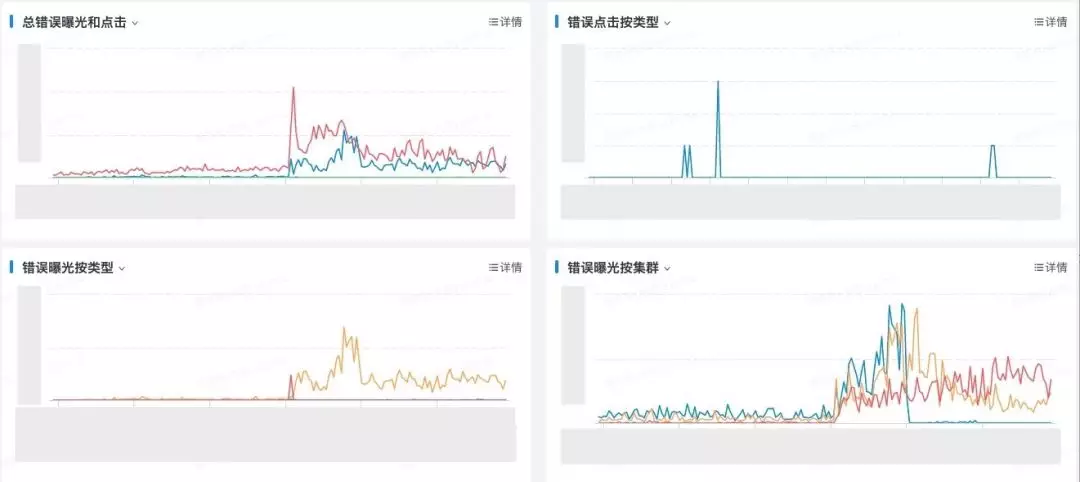
上图是对广告投放状态的实时校验错误监控图,从图中我们清晰看到当前时刻,搜索广告链路的数据质量。无论是中美业务DB同步延迟、DB到引擎数据增量处理链路的延迟、或者是发布变更导致的逻辑出错,都会导致错误数据曲线的异常上涨。校验的规则覆盖了推广计划(campaign)、推广组(adgroup)、客户状态(customer)、词的状态(keyword)、品的状态(feed)。校验的节点覆盖了曝光和点击两个不同的环节。
5. 引擎及算法的实时质量
图三:

搜索引擎日志pvlog中蕴含了非常多有价值的信息,利用好这些信息不仅可以做到线上问题的实时发现,还能帮助算法同学感知线上的实时效果提供抓手。如图三所示,通过实时计算引擎Blink我们对TTLog中的pv信息进行解析和切分,然后将拆分的结果输出到阿里云日志服务SLS中,再对接Xflush进行实时的聚合和可视化展示。
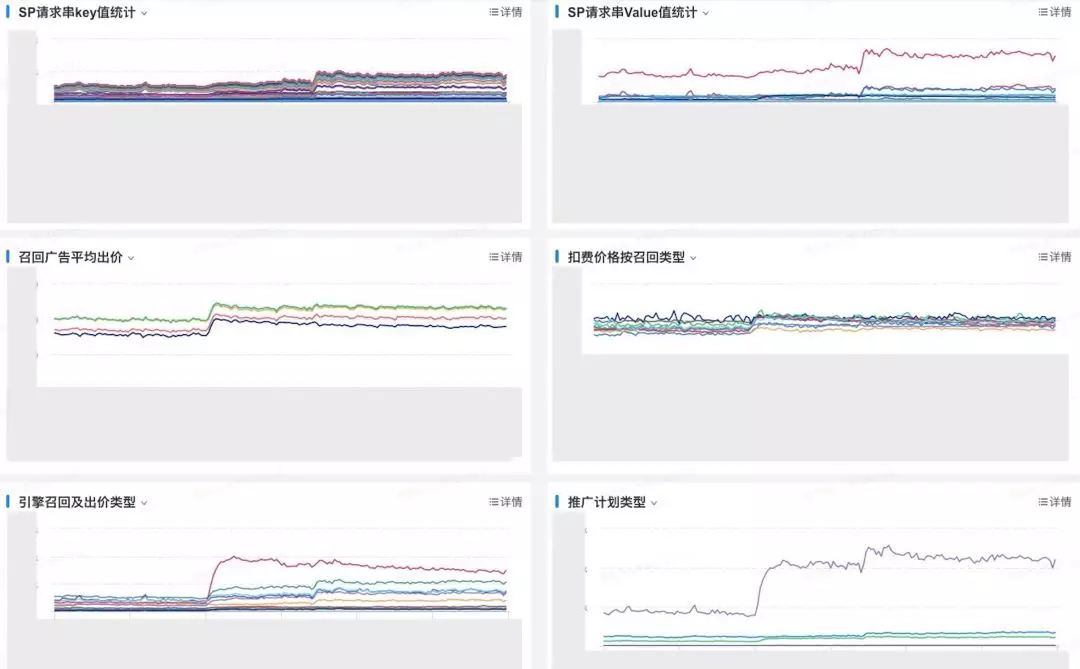
如上图所示,上半年我们曾出现过一次线上的资损故障,是搜索应用端构造的搜索广告引擎SP请求串中缺失了一个参数,导致部分头部客户的广告没有在指定地域投放,故障从发生到超过10+客户上报才发现,历经了10几个小时。我们通过对SP请求串的实时key值和重要value值进行实时监控,可以快速发现key值或value值缺失的场景。
此外,不同召回类型、扣费类型、以及扣费价格的分布,不仅可以监控线上异常状态的出现,还可以给算法同学做实验、调参、以及排查线上问题时提供参考。
四、几个核心问题
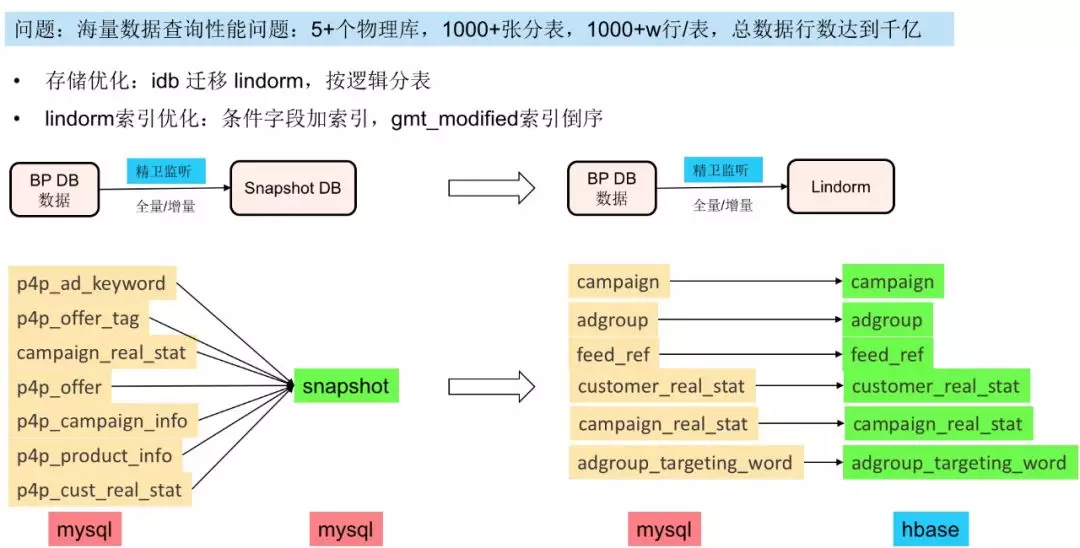
1. why lindorm?
最初的实现,我们是通过精卫监听业务DB的变更写入另一个新的DB(MySQL),但是性能是一个非常大的瓶颈。我们的数据库分了5+个物理库,1000+张分表,单表的平均数据量达到1000+w行,总数据达到千亿行。
后通过存储的优化和按逻辑进行分表的方式,实现了查询性能从平均1s到70ms的提升。
2. why BCP + MetaQ + igps?
最初我们是想直接使用BCP对数据进行校验:通过igps封装lindorm的查询接口,然后提供hsf接口供在BCP里直接使用。
但是还是因为性能问题:TTLog的一条message平均包含60+条pv,每个pv可能有5个或更多广告,每个广告要查6张表,单条message在BCP校验需要调用约60x5x6=1800次hsf请求。当我们在BCP中对TTLog的数据进行10%的采样时,后端服务igps的性能已经出现瓶颈,hsf线程池被打满,同时7台服务器的cpu平均使用率达到70%以上。
借助MetaQ的引入,可以剔除hsf调用的网络开销,同时将消息的生产和消费解耦,当流量高峰到达时,igps可以保持自己的消费速率不变,更多的消息可以暂存在队列里。通过这一优化,我们不仅扛住了10%的采样,当线上采样率开到100%时,我们的igps的服务器的平均cpu使用率仍只维持在20%上下,而且metaq中没有出现消息堆积。
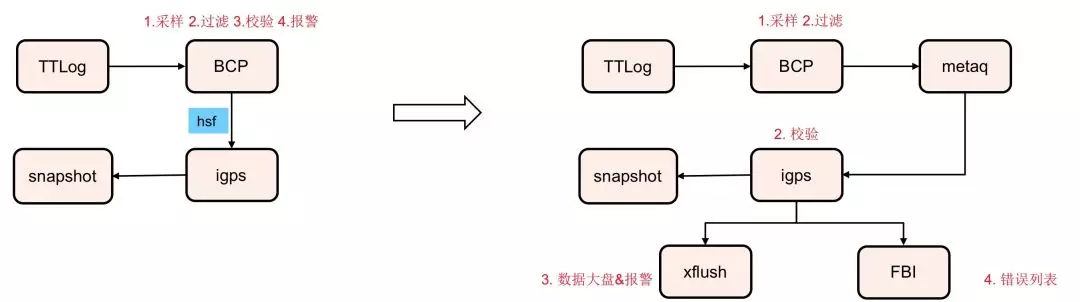
不过这样一来,bcp的作用从原来的“采样、过滤、校验、报警”,只剩下“采样、过滤”。无法发挥其通过在线编码可以快速适应业务变化的作用。
3. why not all blink?
其实“BCP + MetaQ + igps”的流程可以被“Blink + SLS”取代,那为什么不都统一使用Blink呢。
一方面,目前点击的校验由于其流量相对较小的因素,我们目前是直接在BCP里编写的校验代码,不需要走发布流程,比较快捷。而且BCP拥有如“延迟校验”、“限流控制”等个性化的功能。另一方面,从我们目前使用Blink的体验来看,实时的处理引擎尚有一些不稳定的因素,尤其是会有不稳定的网络抖动(可能是数据源和Blink workder跨机房导致)。
4. SP请求的key值如何拆分?
在做SP请求串的实时key值监控的时候,遇到了一个小难题:SP的请求串中参数key是动态的,并不是每个key都会在每个串中出现,而且不同的请求串key出现的顺序是不一样的。如何切分使其满足Xflush的“列值分组”格式要求。
实现方式是,对每个sp请求串,使用Blink的udtf(自定义表值函数)进行解析,得到每个串的所有key和其对应的value。然后输出时,按照“validKey={key},validValue={value}”的格式对每个sp请求串拆分成多行输出。然后通过Xflush可以按照validKey进行分组,并对行数进行统计。
五、总结及后续规划
本文介绍了通过大数据的处理技术做到电商搜索广告场景下数据端到端一致性问题的实时发现,并且通过“实时发现”结合“数据变更节点的主动校验”,实现数据全流程的一致性校验。
后续的优化方向主要有两方面:
- 结合业务的使用场景,透出更丰富维度的实时数据。
- 将该套技术体系“左移”到线下/预发测试阶段,实现“功能、性能、效果”的一键式自动化测试,同时覆盖从搜索应用到引擎的全链路。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号