

Link of the Paper: https://arxiv.org/abs/1411.4389
Main Points:
- A novel Recurrent Convolutional Architecture ( CNN + LSTM ): both Spatially and Temporally Deep.
- The recurrent long-term models are directly connected to modern visual convnet models and can be jointly trained to simultaneously learn temporal dynamics and convolutional perceptual representations.
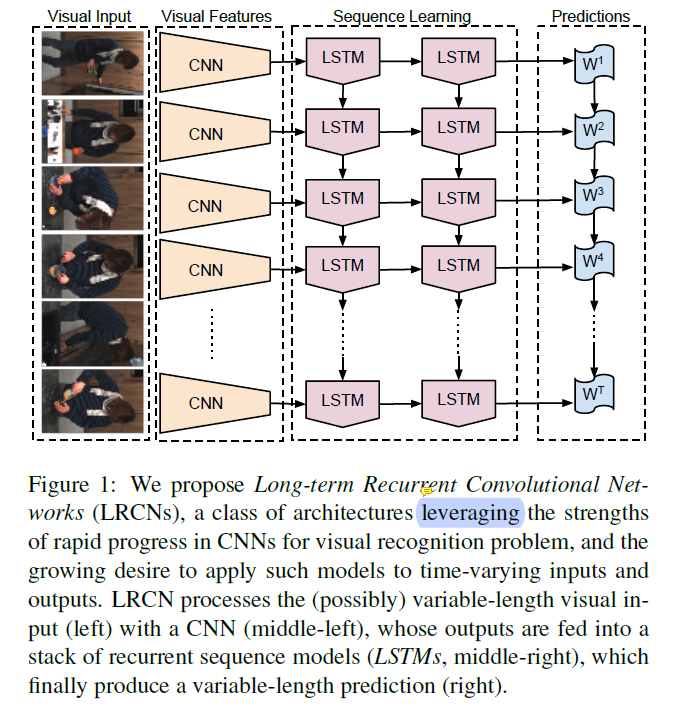
Other Key Points:
- A significant limitation of simple RNN models which strictly integrate state information over time is known as the "vanishing gradient" effect: the ability to backpropogate an error signal through a long-range temporal interval becomes increasingly impossible in practice.
- The authors show LSTM-type models provide for improved recognition on conventional video activity challenges and enable a novel end-to-end optimizable mapping from image pixels to sentence-level natural language descriptions.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号