


Link of the Paper: https://arxiv.org/pdf/1409.3215.pdf
Main Points:
- Encoder-Decoder Model: Input sequence -> A vector of a fixed dimensionality -> Target sequence.
- A multilayered LSTM: The LSTM did not have difficulty on long sentences. Deep LSTMs significantly outperformed shallow LSTMs.
- Reverse Input: Better performance. While the authors do not have a complete explanation to this phenomenon, they believe that it is caused by the introduction of many short term dependencies to the dataset. LSTMs trained on reversed source sentences did much better on long sentences than LSTMs trained on the raw source sentences, which suggests that reversing the input sentences results in LSTMs with better memory utilization.
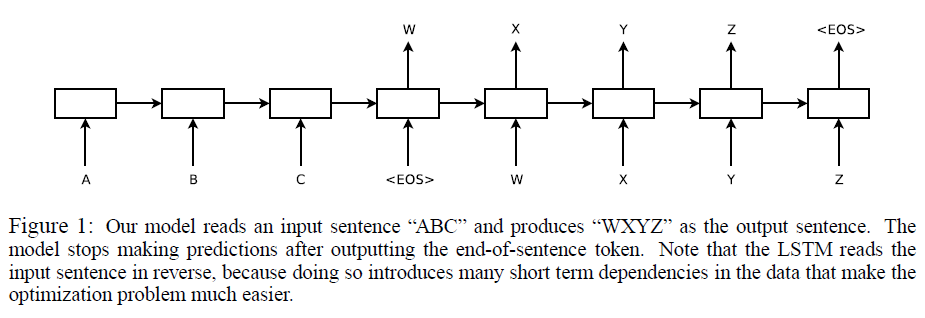
Other Key Points:
- A significant limitation: Despite their flexibility and power, DNNs can only be applied to problems whose inputs and targets can be sensibly encoded with vectors of fixed dimensionality.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号