CMU 15-445 2021 Project3 下 Executor
在第三个编程项目中,将向数据库系统添加对查询执行的支持。您将实现负责获取查询计划节点并执行它们的执行器。将创建执行以下操作的执行器:
- Access Methods: Sequential Scan
- Modifications: Insert, Update, Delete
- Miscellaneous: Nested Loop Join, Hash Join, Aggregation, Limit, Distinct
因为当前的DBMS还不支持SQL,所以我们的实现将直接在手工编写的查询计划上操作。
我们将使用迭代器查询处理模型(即Volcano模型,火山模型)。回想一下,在这个模型中,每个查询计划执行器都实现了Next函数。当DBMS调用执行器的Next函数时,执行器返回(1)单个元组或(2)不再有元组的指示符。使用这种方法,每个执行器都实现了一个循环,该循环继续对其子级调用Next,以检索元组并逐一处理它们。
在BusTub的迭代器模型实现中,每个执行器的Next函数除了返回一个元组之外,还返回一个记录标识符(RID)。记录标识符作为元组相对于其所属表的唯一标识符。
后文给出的代码大多不完整,不能直接套用,需要使用请自行理解完成后补全。
强烈建议开始完成实验前先看懂项目中Table结构的实现,主要包含以下类:Catalog、TableHeap、TablePage、TableIterator、ExtendibleHashTableIndex。可以参考我的上一篇文章:CMU 15-445 2021 Project3 上。
AbstractExpression

对where语句(不止where语句中用到)进行拆分,形成一个树,其中的每一个节点就对应一个 AbstractExpression 类,一般包含 Evaluate,EvaluateJoin 和 EvaluateAggregate 三个方法,这三个方法其实都是一个功能:获取自身表达式对应属性的值。该抽象类包括其子节点以及返回类型,还有其他有用的方法。其中:
- ConstantValueExpression,存储用于比较的一个常数,三种方法返回的都是同一个常数;
- ColumnValueExpression,维护相对于特定模式或连接的元组索引和列索引,比如 S.value;
- ComparisonExpression,表示我们想要执行的比较类型,它会有两个子节点(AbstractExpression 类型),这两个子表达式就是需要比较的值,同时还会存储比较类型,比如相等、小于、大于、小于等于...,三个方法返回的都是比较结果(真或假);
- AggregateValueExpression,表示MAX(a), MIN(b), COUNT(c)等聚合,或者Group By的分组。它只能调用 EvaluateAggregate 方法,输入所有需要输出的值,根据自身类别(聚合、分组),返回此表达式在其中对应的值,比如我们的SQL是:
SELECT count(col_a), col_b, sum(col_c) FROM test_1 Group By col_b HAVING count(col_a) > 100,那么,输入方法的就是count(col_a), col_b, sum(col_c),如果当前的表达式是col_b的表达式,那么它就会直到三者中的col_b,然后返回。
总结来说,ConstantValueExpression用于获取设定的常数,ColumnValueExpression用于获取很多列中自身对应列的值,ComparisonExpression用于获取两个表达式比较的结果是否符合预期(true or false),AggregateValueExpression用于获取多个表中我们需要的那个表的某一列的值。
AbstractPlanNode
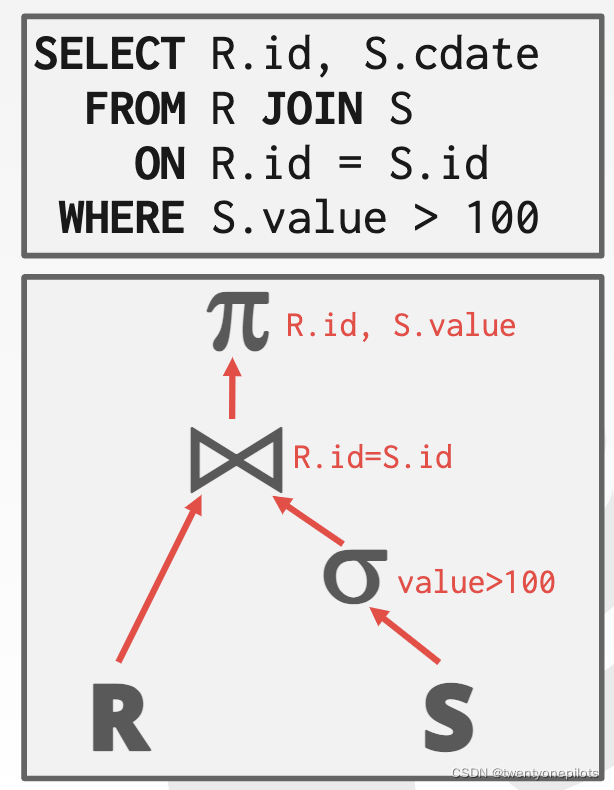
此类用于对SQL语句进行拆分。
将SQL语句拆成一个树,其中的每一个节点就对应一个 AbstractPlanNode,并输入到对应 executor (执行器)中执行,AbstractPlanNode 类包含执行该节点功能需要的一些材料。该抽象类包括其子节点,以及向上返回的列格式(Schema)。对于不同类型的语句:sequential scan, insert, update, delete, nested loop join, hash join, aggregation, limit, distinct,都有不同的节点类的实现。
AbstractExecutor
类似 AbstractPlanNode ,AbstractExecutor 同样对不同语句有不同的实现。用于执行实现各种语句。主要的函数是Next(),以tuple为单位执行。
Tuple tuple;
RID rid;
while (executor->Next(&tuple, &rid)) {
if (result_set != nullptr) {
result_set->push_back(tuple);
}
}
所以我们需要每次 Next() 都能得到一个元组,并且下一次再调用的时候能得到下一个元组。
SeqScanExecutor
SeqScanPlanNode 表示一个顺序的表扫描操作。对应SQL的 SELECT。
这个执行器也是最基础和重要的。
class SeqScanExecutor : public AbstractExecutor {
public:
SeqScanExecutor(ExecutorContext *exec_ctx, const SeqScanPlanNode *plan);
void Init() override;
bool Next(Tuple *tuple, RID *rid) override;
const Schema *GetOutputSchema() override { return plan_->OutputSchema(); }
private:
/** The sequential scan plan node to be executed */
const SeqScanPlanNode *plan_;
std::vector<Tuple> tuples_;
std::vector<RID> rids_;
uint32_t cursor_;
};
我们需要实现 Init() 和 Next()。
tuples_,rids_,cursor_ 都是我在原来类的基础上加:
- tuples_,用来存放获取的所有元组;
- rids_,用来存放每个元组对应的RID;
- cursor_,用来判定当前读取元组的位置。
首先实现 Init(),这个方法会直接读取所有符合条件的元组存储到 tuples_ 里面。
void SeqScanExecutor::Init() {
// 初始化成员状态
tuples_.clear();
rids_.clear();
cursor_ = 0;
// 获取限定表达式,输出schema,原始schema
const AbstractExpression *predicate = (plan_->GetPredicate());
const Schema *schema_out = GetOutputSchema();
TableInfo *table_info = exec_ctx_->GetCatalog()->GetTable(plan_->GetTableOid());
Schema *schema = &table_info->schema_;
// 获取表的迭代器(指向第一个元组)
auto table_iter = table_info->table_->Begin(exec_ctx_->GetTransaction());
// 若表空则结束返回
if (table_iter == table_info->table_->End()) {
return;
}
// 遍历所有元组,将符合条件的元组加入tuples_
while (table_iter != table_info->table_->End()) {
// 实现条件判定
if (xxx) {
// 按输出列的顺序将value依次放入vector
for (uint32_t i = 0; i < schema_out->GetColumnCount(); i++) {
values.emplace_back(value);
}
// 将数据保存
Tuple tuple(values, schema_out);
tuples_.emplace_back(tuple);
rids_.push_back((*table_iter).GetRid());
}
++table_iter;
}
}
然后在 Next() 中实现元组的依次输出。
bool SeqScanExecutor::Next(Tuple *tuple, RID *rid) {
if (cursor_ >= tuples_.size()) {
return false;
}
*tuple = tuples_[cursor_];
*rid = rids_[cursor_++];
return true;
}
InsertExecutor
用来插入一条或多元组。插入的值可以直接给出具体值,也可以从子执行程序中提取。
class InsertExecutor : public AbstractExecutor {
public:
InsertExecutor(ExecutorContext *exec_ctx, const InsertPlanNode *plan,
std::unique_ptr<AbstractExecutor> &&child_executor);
void Init() override;
bool Next([[maybe_unused]] Tuple *tuple, RID *rid) override;
const Schema *GetOutputSchema() override { return plan_->OutputSchema(); };
private:
const InsertPlanNode *plan_;
std::unique_ptr<AbstractExecutor> child_executor_;
};
当SQL已经给出所有需要插入的value时,child_executor_ 就用不到,否则就需要 child_executor_ 返回需要插入的元组集合。
因为一次就插入所有元组,所以不需要实现 Init()。
bool InsertExecutor::Next([[maybe_unused]] Tuple *tuple, RID *rid) {
// 获取需要的对象
table_oid_t table_oid = plan_->TableOid();
Catalog *catalog = exec_ctx_->GetCatalog();
TableInfo *table_info = catalog->GetTable(table_oid);
TableHeap *table = catalog->GetTable(table_oid)->table_.get();
// 需要插入表的结构
const Schema *schema = &catalog->GetTable(table_oid)->schema_;
std::vector<IndexInfo*> indexes = catalog->GetTableIndexes(table_info->name_);
// 判断是直接插入还是需要子语句获取元组集合
if (plan_->IsRawInsert()) {
std::vector<std::vector<Value>> raw_values = plan_->RawValues();
for (const auto &value : raw_values) {
*tuple = Tuple(value, schema);
// 插入元组
if (!table->InsertTuple(xxx)) {
return false;
}
// 同时更改对应表的索引:插入新的项
for (auto index : indexes) {
index->index_->InsertEntry(key_tuple);
}
}
} else {
// 使用其他执行器前必须初始化
child_executor_->Init();
RID rrid;
while (child_executor_->Next(tuple, &rrid)) {
if (!table->InsertTuple(xxx)) {
return false;
}
// 同时更改对应表的索引:插入新的项
for (auto index : indexes) {
index->index_->InsertEntry(key_tuple);
}
}
}
return false;
}
注意:
- 使用其他执行器前必须执行初始化;
- 改变表结构的同时必须同时修改对应表的索引。
UpdateExecutor
更新表的数据。实现类似 InsertExecutor,主要不能忘了改对应的索引。
DeleteExecutor
也差不多。
NestedLoopJoinExecutor
NestedLoopJoinExecutor 在两个表上执行一个嵌套循环JOIN。
class NestedLoopJoinExecutor : public AbstractExecutor {
public:
NestedLoopJoinExecutor(ExecutorContext *exec_ctx, const NestedLoopJoinPlanNode *plan,
std::unique_ptr<AbstractExecutor> &&left_executor,
std::unique_ptr<AbstractExecutor> &&right_executor);
void Init() override;
bool Next(Tuple *tuple, RID *rid) override;
const Schema *GetOutputSchema() override { return plan_->OutputSchema(); };
private:
/** The NestedLoopJoin plan node to be executed. */
const NestedLoopJoinPlanNode *plan_;
std::unique_ptr<AbstractExecutor> left_executor_;
std::unique_ptr<AbstractExecutor> right_executor_;
std::vector<Tuple> tuples_;
uint32_t cursor_;
};
left_executor_ 和 right_executor_ 分别执行获取所有左、右表的元组的操作。
首先实现 Init() 将所有连接的新元组存储,由 Next() 简单遍历。
void NestedLoopJoinExecutor::Init() {
tuples_.clear();
cursor_ = 0;
// 获取需要的对象
const AbstractExpression *predicate = (plan_->Predicate());
const Schema *schema_out = plan_->OutputSchema();
const Schema *schema_left = left_executor_->GetOutputSchema();
const Schema *schema_right = right_executor_->GetOutputSchema();
// 分别获取左右两表的所有元组,分开存储
left_executor_->Init();
while (left_executor_->Next(&tuple_left, &lrid)) {
tuples_left.push_back(tuple_left);
}
right_executor_->Init();
while (right_executor_->Next(&tuple_right, &rrid)) {
tuples_right.push_back(tuple_right);
}
// 暴力双层遍历
for (const auto &tuple1 : tuples_left) {
for (const auto &tuple2 : tuples_right) {
// 两两匹配验证:限定的两个比较列的值是否相等
if (!predicate->EvaluateJoin() {
continue;
}
for (uint32_t i = 0; i < schema_out->GetColumnCount(); i++) {
values.push_back(value);
}
Tuple tuple_out(values, schema_out);
tuples_.emplace_back(tuple_out);
}
}
}
怎么按照输出的要求依次获得对应列的值 value?
不能依靠列名获取,因为多个表可能有相同的列名,同时输出的列可能有别名。
还记得 ColumnValueExpression 吗,它里面有我们需要的方法。
HashJoinExecutor
暴力循环实在难以下咽,所以高效的HashTable被引入完成高性能的 Join 操作。
SimpleHashJoinHashTable
我们可以创建一个对象:unordered_map<Value, vector<Tuple>> ht 用来实现快速查找匹配的Tuple(一个表中多个元组可能有相同的属性值,所以要用vector)。
这里有两个问题:1. Value 是没有默认构造的,不能用作key;2. 使用自定义对象作为key需要实现对应的hash计算。
幸运的是,在 AggregationExecutor 中代码已经有了类似的设计,就不用我大费脑筋了,照葫芦画瓢不太难。最终实现了一个 SimpleHashJoinHashTable 的Hash Table。
首先包装一下 Value:
hash_join_plan.h
namespace std {
struct HashJoinKey {
Value key_value_;
bool operator==(const HashJoinKey &other) const {
return key_value_.CompareEquals(other.key_value_) == CmpBool::CmpTrue;
}
};
}
然后实现对应的hash:
hash_join_plan.h
namespace std {
/** Implements std::hash on HashJoinKey */
template <>
struct hash<bustub::HashJoinKey> {
std::size_t operator()(const bustub::HashJoinKey &hash_join_key) const {
size_t curr_hash = 0;
if (!hash_join_key.key_value_.IsNull()) {
curr_hash = bustub::HashUtil::CombineHashes(curr_hash, bustub::HashUtil::HashValue(&hash_join_key.key_value_));
}
return curr_hash;
}
};
注意要放在std命名空间。
最后完成 SimpleHashJoinHashTable:
hash_join_executor.h
class SimpleHashJoinHashTable {
public:
SimpleHashJoinHashTable() = default;
void Insert(const Value &key_value, const Tuple &tuple) {
HashJoinKey key{key_value};
if (ht_.count(key) == 0) {
ht_.insert({key, {}});
}
std::vector<Tuple> &tuples = ht_.find(key)->second;
tuples.push_back(tuple);
}
class Iterator {
public:
/** Creates an iterator for the aggregate map. */
explicit Iterator(std::unordered_map<HashJoinKey, std::vector<Tuple>>::const_iterator iter) : iter_{iter} {}
/** @return The key of the iterator */
const HashJoinKey &Key() { return iter_->first; }
/** @return The value of the iterator */
const std::vector<Tuple> &Val() { return iter_->second; }
/** @return The iterator before it is incremented */
Iterator &operator++() {
++iter_;
return *this;
}
bool operator==(const Iterator &other) { return this->iter_ == other.iter_; }
bool operator!=(const Iterator &other) { return this->iter_ != other.iter_; }
private:
std::unordered_map<HashJoinKey, std::vector<Tuple>>::const_iterator iter_;
};
Iterator Begin() { return Iterator(ht_.cbegin()); }
Iterator End() { return Iterator(ht_.cend()); }
Iterator Find(const Value &key_value) {
HashJoinKey key{key_value};
return Iterator(ht_.find(key));
}
private:
std::unordered_map<HashJoinKey, std::vector<Tuple>> ht_{};
};
细节自己慢慢看理解一下,虽然有点长但是不难。
Init()
class HashJoinExecutor : public AbstractExecutor {
public:
HashJoinExecutor(ExecutorContext *exec_ctx, const HashJoinPlanNode *plan,
std::unique_ptr<AbstractExecutor> &&left_child, std::unique_ptr<AbstractExecutor> &&right_child);
void Init() override;
bool Next(Tuple *tuple, RID *rid) override;
const Schema *GetOutputSchema() override { return plan_->OutputSchema(); };
private:
/** The NestedLoopJoin plan node to be executed. */
const HashJoinPlanNode *plan_;
SimpleHashJoinHashTable hjht_{};
SimpleHashJoinHashTable::Iterator hjht_iterator_{hjht_.Begin()};
std::unique_ptr<AbstractExecutor> left_executor_;
std::unique_ptr<AbstractExecutor> right_executor_;
std::vector<Tuple> tuples_;
uint32_t cursor_;
};
多了两个对象:
SimpleHashJoinHashTable hjht_{};SimpleHashJoinHashTable::Iterator hjht_iterator_{hjht_.Begin()};
就看作普通的map和对应的iter就可以。
void HashJoinExecutor::Init() { // NOLINT
tuples_.clear();
cursor_ = 0;
// 获取所需对象
// 左表的元组全部插入自定义的hash表中
left_executor_->Init();
while (left_executor_->Next(&tuple_left, &lrid)) {
hjht_.Insert(left_expr->Evaluate(&tuple_left, schema_left), tuple_left);
}
while (right_executor_->Next(&tuple_right, &rrid)) {
tuples_right.push_back(tuple_right);
}
// 只需要遍历一遍右表的元组
for (const auto &tuple2 : tuples_right) {
// 判断此元组在条件列的值有没有与左表一样的
if (hjht_.Find(right_expr_value) == hjht_.End()) {
continue;
}
// 遍历找到的Tuple数组,组合构建新元组,存储起来
for (const Tuple &tuple1 : tuple1s) {
std::vector<Value> values;
for (uint32_t i = 0; i < schema_out->GetColumnCount(); i++) {
values.push_back(value_out));
}
Tuple tuple_out(values, schema_out);
tuples_.emplace_back(tuple_out);
}
}
}
AggregationExecutor
AggregationExecutor 对子执行器生成的元组执行聚合操作(例如COUNT, SUM, MIN, MAX)。
具体实现没什么好说的,主要它的HashTable实现比较值得一学。
class SimpleAggregationHashTable {
public:
SimpleAggregationHashTable(const std::vector<const AbstractExpression *> &agg_exprs,
const std::vector<AggregationType> &agg_types)
: agg_exprs_{agg_exprs}, agg_types_{agg_types} {}
AggregateValue GenerateInitialAggregateValue() {
std::vector<Value> values{};
for (const auto &agg_type : agg_types_) {
switch (agg_type) {
case AggregationType::CountAggregate:
// Count starts at zero.
values.emplace_back(ValueFactory::GetIntegerValue(0));
break;
case AggregationType::SumAggregate:
// Sum starts at zero.
values.emplace_back(ValueFactory::GetIntegerValue(0));
break;
case AggregationType::MinAggregate:
// Min starts at INT_MAX.
values.emplace_back(ValueFactory::GetIntegerValue(BUSTUB_INT32_MAX));
break;
case AggregationType::MaxAggregate:
// Max starts at INT_MIN.
values.emplace_back(ValueFactory::GetIntegerValue(BUSTUB_INT32_MIN));
break;
}
}
return {values};
}
void CombineAggregateValues(AggregateValue *result, const AggregateValue &input) {
for (uint32_t i = 0; i < agg_exprs_.size(); i++) {
switch (agg_types_[i]) {
case AggregationType::CountAggregate:
// Count increases by one.
result->aggregates_[i] = result->aggregates_[i].Add(ValueFactory::GetIntegerValue(1));
break;
case AggregationType::SumAggregate:
// Sum increases by addition.
result->aggregates_[i] = result->aggregates_[i].Add(input.aggregates_[i]);
break;
case AggregationType::MinAggregate:
// Min is just the min.
result->aggregates_[i] = result->aggregates_[i].Min(input.aggregates_[i]);
break;
case AggregationType::MaxAggregate:
// Max is just the max.
result->aggregates_[i] = result->aggregates_[i].Max(input.aggregates_[i]);
break;
}
}
}
void InsertCombine(const AggregateKey &agg_key, const AggregateValue &agg_val) {
if (ht_.count(agg_key) == 0) {
ht_.insert({agg_key, GenerateInitialAggregateValue()});
}
CombineAggregateValues(&ht_[agg_key], agg_val);
}
class Iterator {
...
private:
std::unordered_map<AggregateKey, AggregateValue>::const_iterator iter_;
};
Iterator Begin() { return Iterator{ht_.cbegin()}; }
Iterator End() { return Iterator{ht_.cend()}; }
private:
std::unordered_map<AggregateKey, AggregateValue> ht_{};
/** The aggregate expressions that we have */
const std::vector<const AbstractExpression *> &agg_exprs_;
/** The types of aggregations that we have */
const std::vector<AggregationType> &agg_types_;
};
因为聚合的值类别比较多:COUNT, SUM, MIN, MAX。所以HashTable对各种类型设计了不同的计算方式。这部分的设计比较巧妙值得学习推敲。
LimitExecutor
实现方法就是对输出元组数量设定上限,比较简单。
DistinctExecutor
消除重复值最好的方法就是利用HashTable,仿照 AggregationExecutor 和 HashJoinExecutor 里的HashTable实现就能实现这个类。
测试
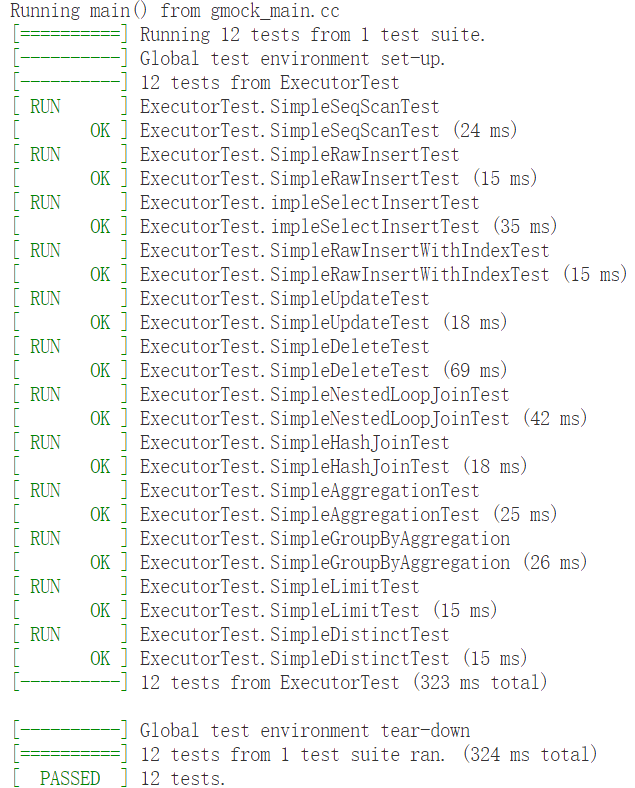
以下是我的测试结果,运行效率仅供参考。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号