
2.安装Spark与Python练习
一、安装Spark
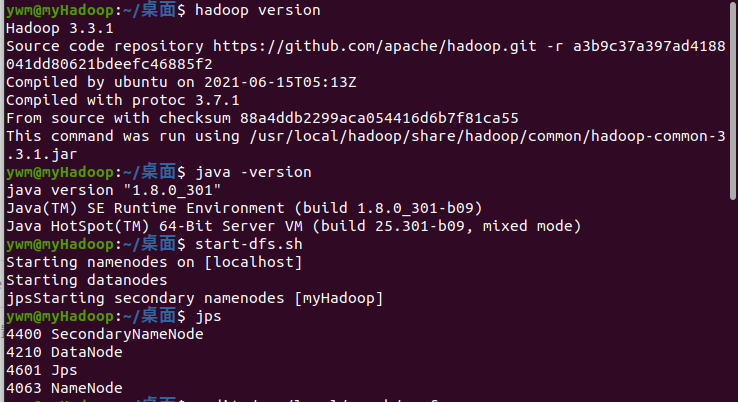
1.检查基础环境hadoop,jdk
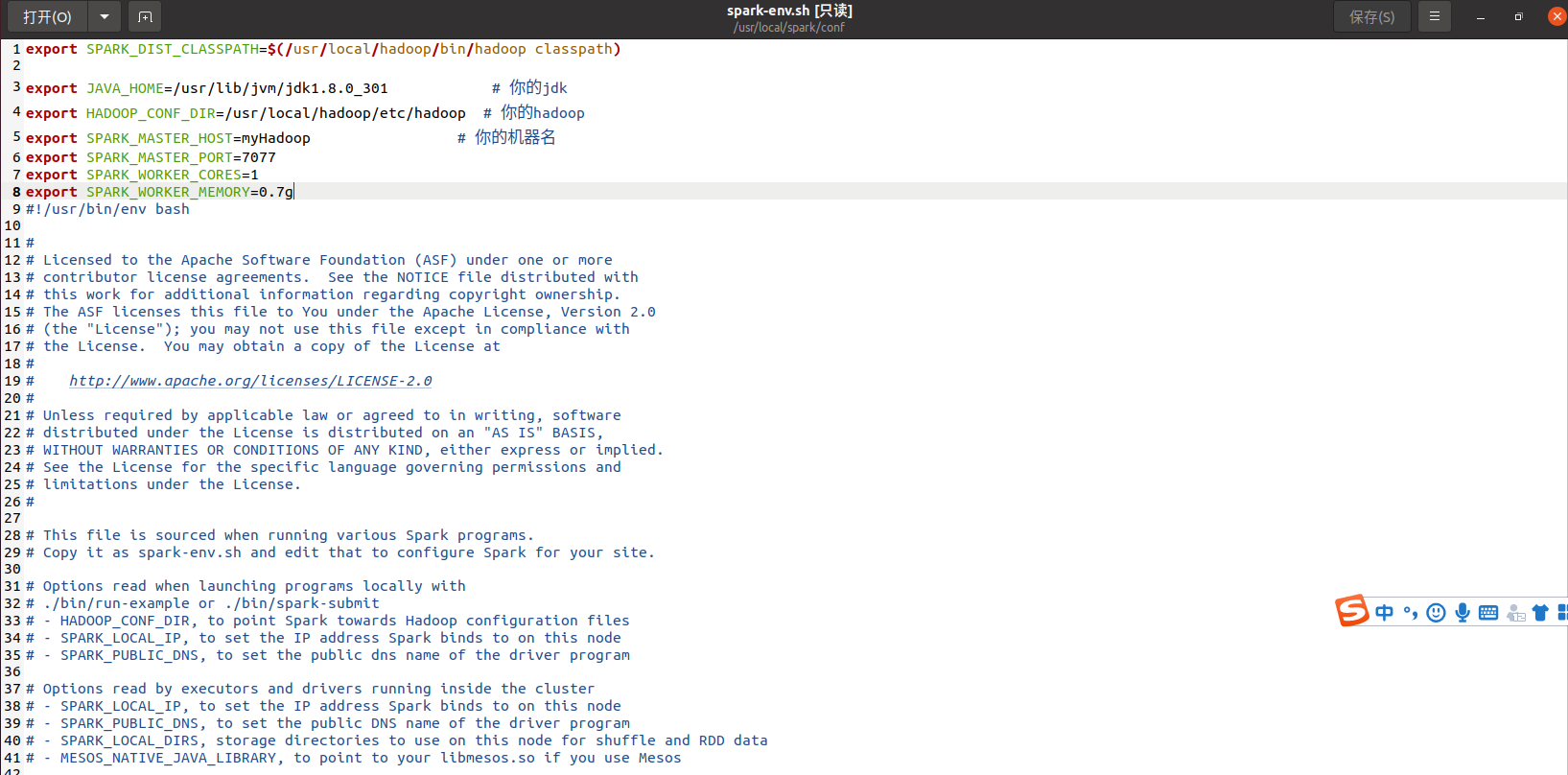
2.配置文件
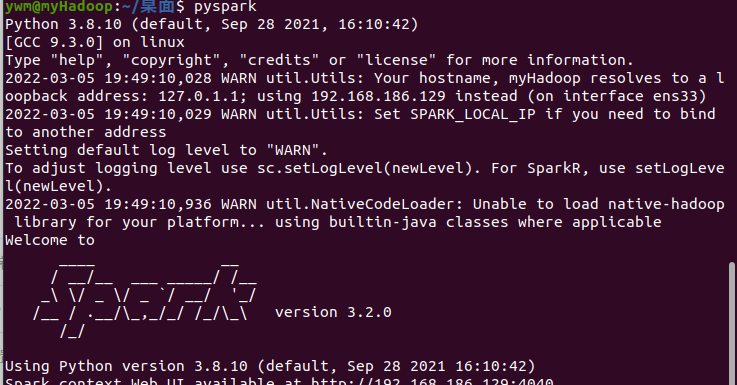
3.环境变量
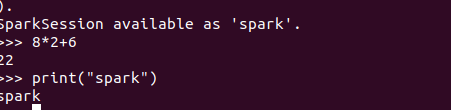
4.运行python代码
二、Python编程练习:英文文本的词频统计
1.准备文本
2.读文件
预处理:大小写,标点符号,停用词分词
统计每个单词出现的次数
按词频大小排序
结果写文件
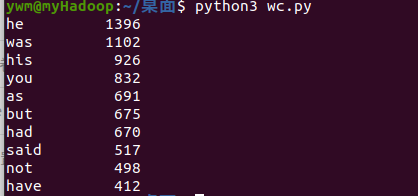
with open("data.txt", "r") as f: text=f.read() text = text.lower() for ch in '!@#$%^&*(_)-+=\\[]}{|;:\'\"“”`~,<.>?/': text=text.replace(ch," ") words = text.split() # 以空格分割文本 stop_words = ['so','out','all','for','of','to','on','in','if','by','under','it','at','into','with','about','i','am','are','is','a','the','and','that','before','her','she','my','be','an','from','would','me','got'] afterwords=[] for i in range(len(words)): z=1 for j in range(len(stop_words)): if words[i]==stop_words[j]: continue else: if z==len(stop_words): afterwords.append(words[i]) break z=z+1 continue counts = {} for word in afterwords: counts[word] = counts.get(word,0) + 1 items = list(counts.items()) items.sort(key=lambda x:x[1],reverse=True) # 输出前10 for i in range(10): word, count = items[i] print("{0:<10}{1:>5}".format(word, count)) # 打印前十个元素

 浙公网安备 33010602011771号
浙公网安备 33010602011771号