stage0 VIT加速器部署单层Attention
Attention的IP核FPGA验证
1、创建工程,生成HLS对应IP核
添加ip代码文件
./src文件夹下是注意力计算IP的所有的子模块,包括所需Softmax,layernorm等,全部添加到工程内,然后加入该目录下的文件./case/ATTN0.cpp。这个模块是第一层注意力机制模块对应的HLS代码,此模块为顶层文件。
添加权重文件到工程
下面代码块直接将权重读取,需要注意权重路径,原来权重在工程./ref目录下,所以需要将./ref目录复制到HLS工程的ATTN0.cpp文件的上一层根目录。
// weights
const int attn_scalars_init [] = {
#include "./refs/attn_0_scalars.txt"
};
const int attn_lnq_scalars_init [] = {
#include "./refs/attn_0_lnq_scalars.txt"
};
const int64_t attn_lnq_lnb_m_init [] = {
#include "./refs/attn_0_lnq_lnb_m.txt"
};
......
ATTN0.cpp修改
需要修改内部top函数接口:在top函数定义了反馈接口(top函数为HLS默认顶层函数,用于生成RTL):#pragma HLS INTERFACE ap_ctrl_chain port=return bundle=control。此代码表明IP核的反馈接口为ap_ctrl_chain,该接口常用于IP模块与模块间互联,但不适用于PS与PL交互。其中port = return中return为关键词,定义了ap_ctrl_chain接口控制寄存器,包括CTRL控制寄存器,STATUS状态寄存器等(可查阅HLS生成的IP对应头文件)。
其中CTRL寄存器位定义:
- bit 0:ap_start(写1启动,自动清零)
- bit 1:ap_done(读,表示完成)
- bit 2:ap_idle(读,表示空闲)
- bit 3:ap_ready(读,表示就绪)
- bit 4:ap_continue(读/写,表示下一个模块准备接收,可自定义有无该位)
- bit 5-31:保留或自定义
PS端必须向ap_start寄存器位写1,IP核才能启动。如果将其直接封装成物理接口,必须寻找方法让PS操作此寄存器。位避免麻烦,可以将ap_ctrl_chain映射成axi_lite接口。具体代码为:
#pragma HLS INTERFACE s_axilite port=return bundle=control
#pragma HLS INTERFACE ap_ctrl_chain port=return bundle=control
这两句话将ap_ctrl_chain接口映射到axi_lite接口上,PS可以控制axi_lite接口对其寄存器操作。
顶层函数完整代码:
void top(hls::stream<hls::vector<__attn_if_t, TP*CAP> >& i_stream, hls::stream<hls::vector<__attn_of_t, TP*CAP> >& o_stream){
#pragma HLS dataflow
#pragma HLS INTERFACE s_axilite port=return bundle=control
#pragma HLS INTERFACE ap_ctrl_chain port=return bundle=control
#pragma HLS interface axis port=i_stream
#pragma HLS interface axis port=o_stream
// attn_inst.do_attn(
// i_stream, o_stream,
// main_ref, lnq_ref,
// q_ref, k_ref, v_ref,
// qq_ref, kq_ref, vq_ref,
// qq_split_head1_ref, qq_split_head2_ref, qq_split_head3_ref,
// kq_split_head1_ref, kq_split_head2_ref, kq_split_head3_ref,
// vq_split_head1_ref, vq_split_head2_ref, vq_split_head3_ref,
// kq_matmul_head1_ref, kq_matmul_head2_ref, kq_matmul_head3_ref,
// softmax_head1_ref, softmax_head2_ref, softmax_head3_ref,
// vq_reshape_head1_ref, vq_reshape_head2_ref, vq_reshape_head3_ref,
// rv_matmul_head1_ref, rv_matmul_head2_ref, rv_matmul_head3_ref,
// a_ref,
// o_ref,
// (const int *)y_ref
// );
attn_inst.do_attn(i_stream, o_stream);
// attn_inst.do_attn_tasks(i_stream, o_stream);
}
注释的代码是用于HLS代码仿真测试监测模块内部数据流。如果想进行HLS仿真,可以直接把ATTN0.cpp作为仿真测试文件,测试时会执行main函数内容,而main函数内容并不会被综合。
2、创建Vivado工程
将HLS工程生成的ip核打包
注意导出ip核和Vivado工程目录不要建的太深,否则会导致工程编译出错。
添加必备的IP—block
添加DMA,fifo等IP,配置好ZYNQ的ps端ddr等,本工程使用的是ZCU102,详细配置PS端可以参考链接。配置完的图片如图所示,top_0即为生成的IP,在DMA接收端添加了一个FIFO,防止DMA直接与Top_0的输出接口与DMAaxi_stream接口握手出错: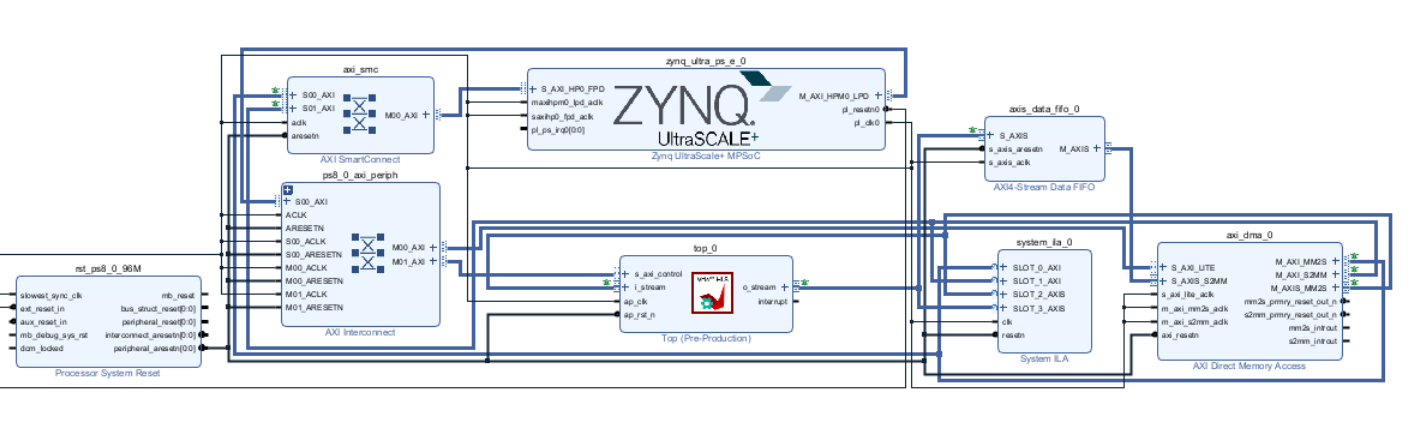
具体细节:
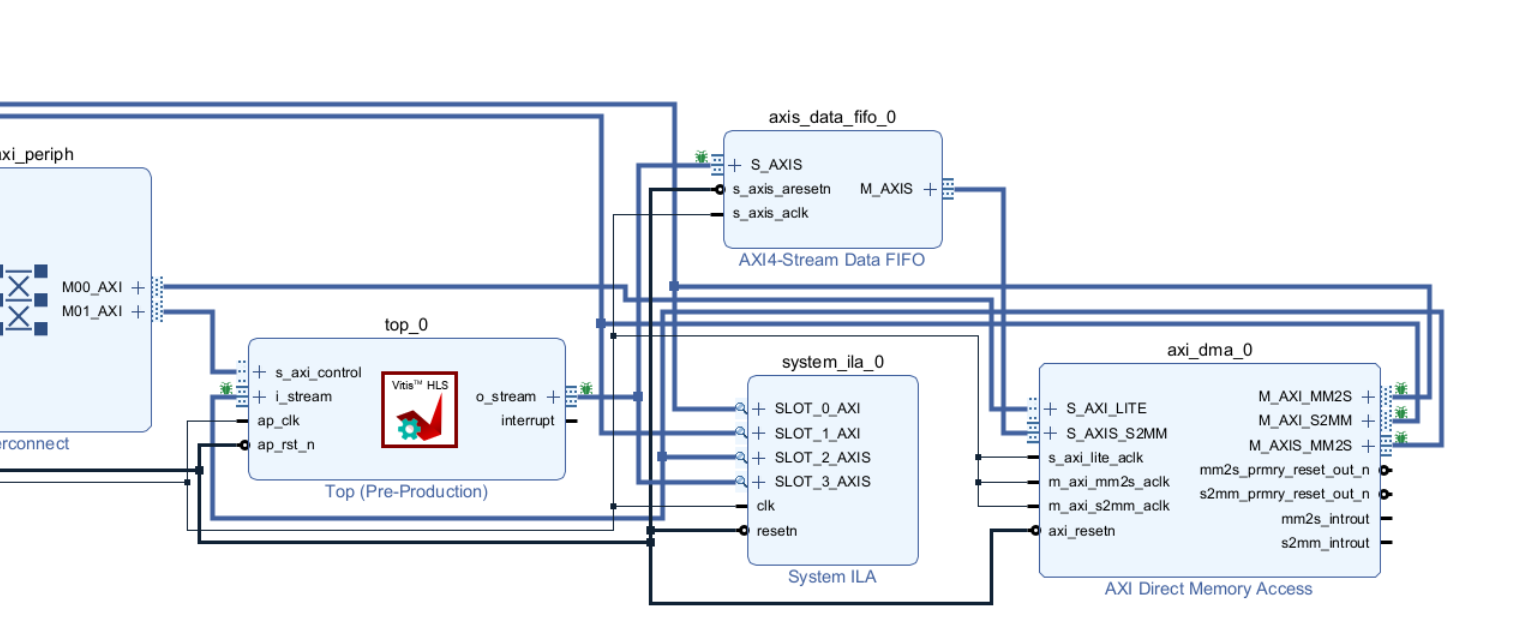
最后连同比特流导出工程用于PS操作即可
3、创建Vitis工程
输入数据格式转化
首先将输入激活值attn_0_input.txt转成python的.h格式头文件便于PS端读取。代码在./python文件夹中,运行main.py即可。
在传输数据时,参考ATTN0.cpp代码中的main函数,输入的数据需要进行重排列,在main函数可以看到vec_i位宽是13位而ip对应接口是32位,在输入数据流进行了数据拼接,两位attn_0_input输入作为一个ip的输入数据。hls::vector<__attn_if_t,TP*CAP> vec_i;定义了输入位宽为__attn_if_t即13位,数组大小为TP*CAP即两个数据拼接作为i_stream输入。
hls::vector<__attn_if_t,TP*CAP> vec_i;
for(int tp=0; tp<TP; tp++){
for(int cap=0; cap<CAP; cap++){
vec_i[tp*CAP + cap] = x_ref[tt*TP + tp][cat*CAP + cap];
}
}
// write the same data for TEST_ROUND times
i_stream.write(vec_i);
仿照测试代码编写PS端操作输入代码:
// 模拟 HLS 的读取顺序:先 TT (行块),再 CAT (列)
for(int tt = 0; tt < TT; tt++) { // 0..97
for(int c = 0; c < C; c++) { // 0..191 (CAT=C because CAP=1)
// HLS 取的是: vector[0] = x[tt*TP + 0][c]
// vector[1] = x[tt*TP + 1][c]
int row0 = tt * TP + 0;
int row1 = tt * TP + 1;
// 计算 flat index (假设 input_data_array 是标准的 Row-Major)
int flat_idx0 = row0 * C + c;
int flat_idx1 = row1 * C + c;
int val0 = input_data_array[flat_idx0];
int val1 = input_data_array[flat_idx1];
// 打包: val0 在低位 (Element 0),val1 在高位
u32 p0 = val0 & 0x1FFF;
u32 p1 = val1 & 0x1FFF;
TxBuffer[buf_idx] = (p1 << 13) | p0;
buf_idx++;
}
}
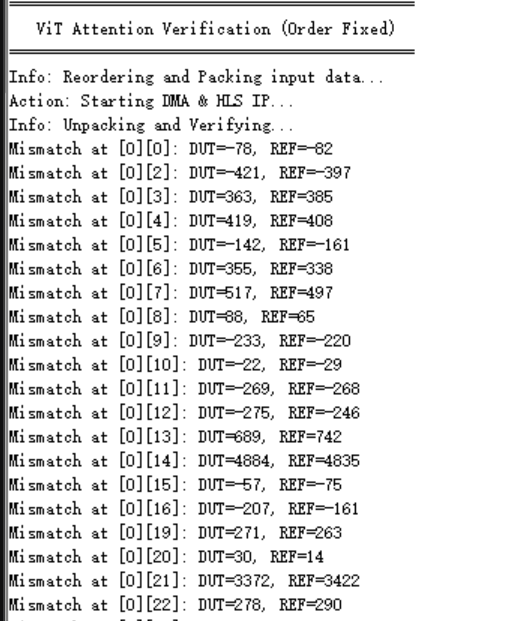
测试结果
测试输出与所给输出接近,但存在5%-7%左右的误差。其中DUT为测试输出,REF为参考输出。
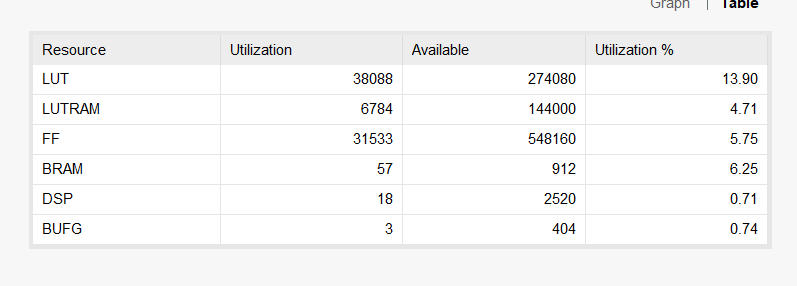
资源占用情况:
注意事项
1、HLS生成的 AXI_STREAM 接口并没有 t_last 信号,需要手动指定输出结束信号,把t_last信号拉高,这就导致DMA传输时一直等不到t_last信号,会使DMA无法停止而造成超时,解决方案就是使用if ((rx_sr & XAXIDMA_IDLE_MASK) || (rx_sr & 0x10)) break;读取DMAIDLE状态位,判断DMA处于空闲状态就认为DMA传输完成,从而停止DMA传输。
2、IP得到的最终输出也需要数据格式对应,具体参考代码。
3、注意DMA传输数据大小,输入的37632个13位宽数据,组合成18816个32位宽大小数据,DMA传输一次位1byte,对应DDR一个地址空间,所以数据量应该是18816 * sizeof(u32) = 75264个数据。
本文来自博客园,作者:{ziyang Li},转载请注明原文链接:https://www.cnblogs.com/ziy123/p/19452308

 浙公网安备 33010602011771号
浙公网安备 33010602011771号