

CS231n笔记 Lecture 2 Image Classification pipeline
距离度量\(L_1\) 和\(L_2\)的区别
一些感性的认识,\(L_1\)可能更适合一些结构化数据,即每个维度是有特别含义的,如雇员的年龄、工资水平等等;如果只是一个一般化的向量,\(L_2\)可能用得更多。但这些仍然需要视具体情况而定。
Nearest Neighbor
KNN-demo
相当于\(K=1\)的KNN分类,这种其实是把所谓的“训练”过程推后了,是一种lazy的做法,model实际上隐藏在了训练数据中。训练时,只是单纯地“记下”训练样本的特征和标签;测试时,拿到一个新的样本,需要遍历所有的训练数据,找到最相似的那个,然后取其label作为当前样本的预测。
K的选取
取1的时候,在训练样本上的精度为100%,但这并不是好事,因为好的模型要有好的泛化能力。
评估model的好坏
像KNN等等这样的模型,存在K这样的超参数。不同超参数的选取是会直接影响模型的好坏的,那么如果评估一个模型,如何去选择最好的超参数呢?
- 只用训练集
用训练集训练,也用训练集来评测。由上一个问题引申出来,如果只用测试集来衡量,可能会在训练集上达到很高的准确度,可能就过拟合了,但实际上我们关注的是unseen的样本。 - 训练集、测试集
这时候我们很自然地就会想到,那我们把训练数据分成两部分,一部分用来训练,另一部分用来测试,我们选取能在测试集上表现最好的模型(or超参数)。这样做带来的问题也是类似的,我们这次会在测试集上过拟合,而测试集却又不能代表未来unseen的样本。 - 训练集、验证集、测试集
更常见的做法是,在训练的初始阶段,就把数据分成(训练集+验证集)+测试集这两大部分。训练时,可以采用比如交叉验证等方法,用验证集上的精度来选择模型的参数,得到最好的模型。然后只在测试集上做一次性的验证,得到的准确度可用于来表征这个模型的能力。需要注意的是,测试集的数据在整个训练过程中都是要保持untouched,只有到了最后要评估模型能力的时候,在测试集上跑一次,得到准确度等度量。
Linear model
\(y = Wx + b\)
b, 处理 imbalanced data , data independent bias terms。 举例来说,10分类的问题,b是一个10维的向量,如果cat的图片多,那b中cat对应的那一维就会大一些。
小感悟
-
在Justin讲课的过程中,有大概5~6次来自学生的提问。这些问题中有一些是作为有一定背景知识的人看来是不值一提的,比如CNN中输入图像的\(28\times 28\times 3\)中的3是代表什么意思等等,但是即便是这样看似“简单”的问题,我们也要敢于去发问。
-
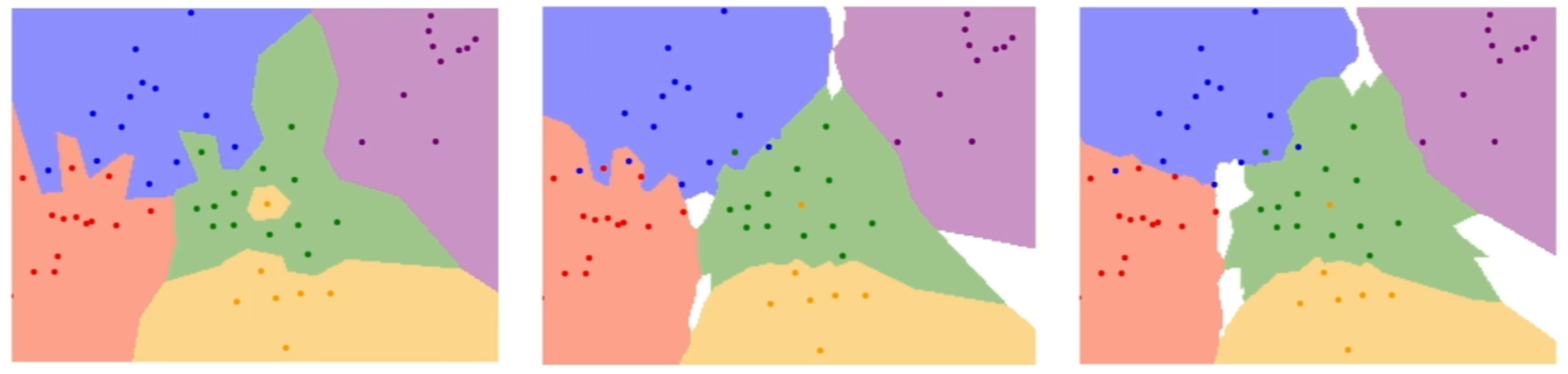
还有一些问题,是我们会比较容易忽略的,比如在KNN的分类区域图上面,除了几个有颜色的区域外,还有一些白色区域。我看到的时候可能就一看了之,但是有学生就会问白色区域的含义是什么?实际上这些区域是无法采用majority voting产生结果的区域,比如K=3时,新来的样本的三个近邻恰好分属三个类别,那就无法决定它的类别了,这时候就是白色区域——当然这只是Justin的slides中的定义,不具有普遍性。
![]()
-
另一个问题印象比较深刻的是,在说\(L_1\)或者\(L_2\)不适合用作衡量图像距离的度量时,Justin给了下图的几张图片,说右边三张和第一张的\(L_1\)的距离都是一样的。想要说明\(L_1\)并不好。
![]()
刚开始说的时候我也疑惑了一下,怎么可能是一样的?直到有一个同学在后面提出了这个疑问,Justin解答说这是他特地凑的......好吧。说这个只想说明,有时候我们自己疑惑的点也许也正是很多其它人所疑惑的,有问题就问出来 😃


 浙公网安备 33010602011771号
浙公网安备 33010602011771号