


AnnotationHub, clusterProfiler 进行GO,KEGG注释
1⃣️ AnnotationHub
目前最新的工具包叫做AnnotationHub,顾名思义,就是注释信息的中装站。通过它,能找到了几乎所有的注释资源。如果没有,你还可以根据已有的数据用它提供的函数进行构建。
1. 加载AnnotationHub
library(AnnotationHub) ##获取数据库
ah = AnnotationHub()
2. 搜索自己所需数据库并下载
res <- query(ah,"Spinacia oleracea")
spinach_org <- ah[['AH72369']]
注:第一次下载比较慢,以后用就很快
3. 了解常用的5个函数
columns(x): 显示当前对象有哪些数据
keytypes(x): 有哪些keytypes可用做select或者keys的keytypes参数
keys(x, keytyp,...): 返回当前数据对象的keys (类似于他包含的内部值)
select(x, keys, colums,keytypes,...): 基于keys,columns,返回数据
mapIds(x,keys, columns,keytype,...): 类似select,但是返回一个列
(1)返回这个数据有哪些列:

(2)返回这个数据可以当作关键词进行查找的列:
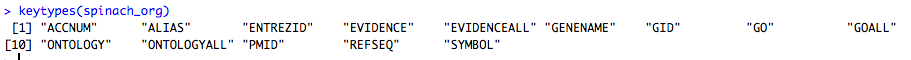
基本上keytypes返回的结果是等于或者少于columns返回的结果。因为并不是所有列都能当做查找对象。
(3)keytypes告诉我们可以当做哪些列是keytype类型,那么keys则列出这个keytype下有哪些关键字。

(4)select 查找
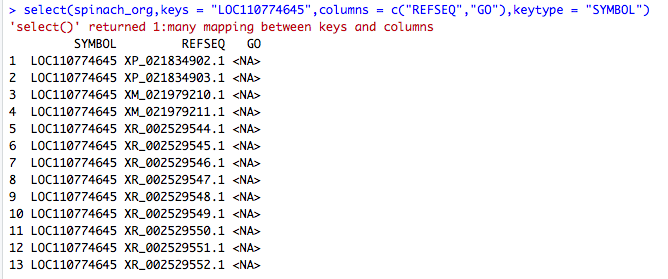
注:有些物种基因组版本更新,在这个数据库中记载的并无对应基因号,可根据记载的基因号REFSEQ,在NCBI下载,并进行blastp比对,进行替换即可
2⃣️clusterProfiler
library(clusterProfiler) ##富集分析
一般将基因SYMBOL转为ENTREZID
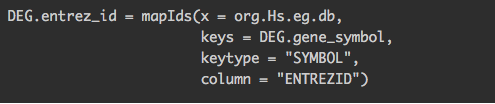
但是个别会出现不成功,可用

关注下方公众号可获得更多精彩


 浙公网安备 33010602011771号
浙公网安备 33010602011771号