

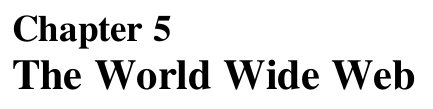

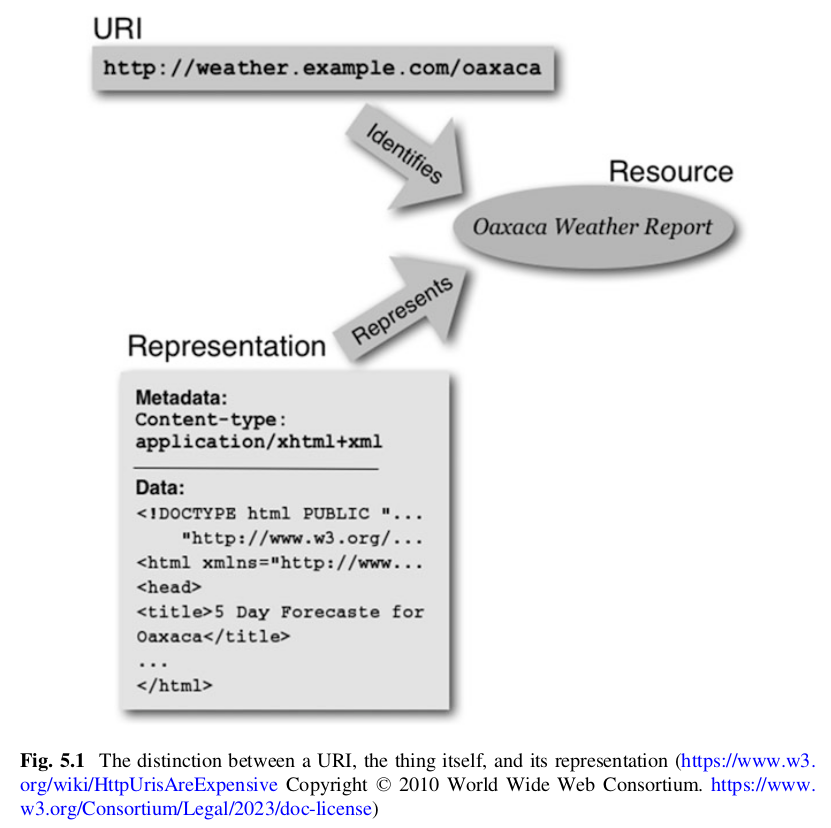

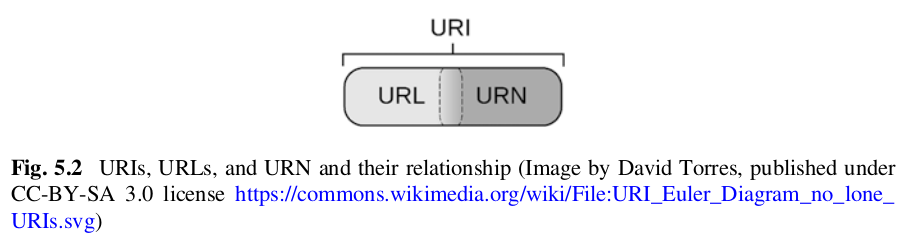









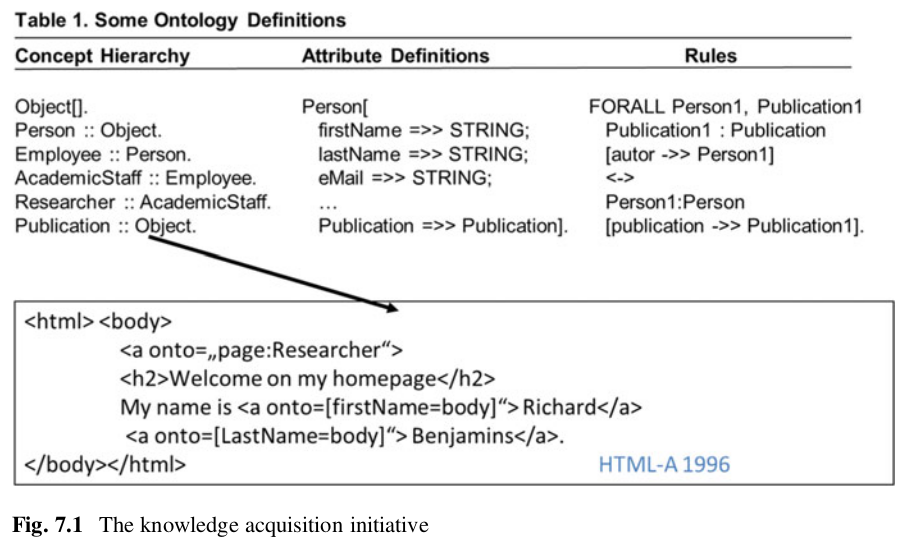
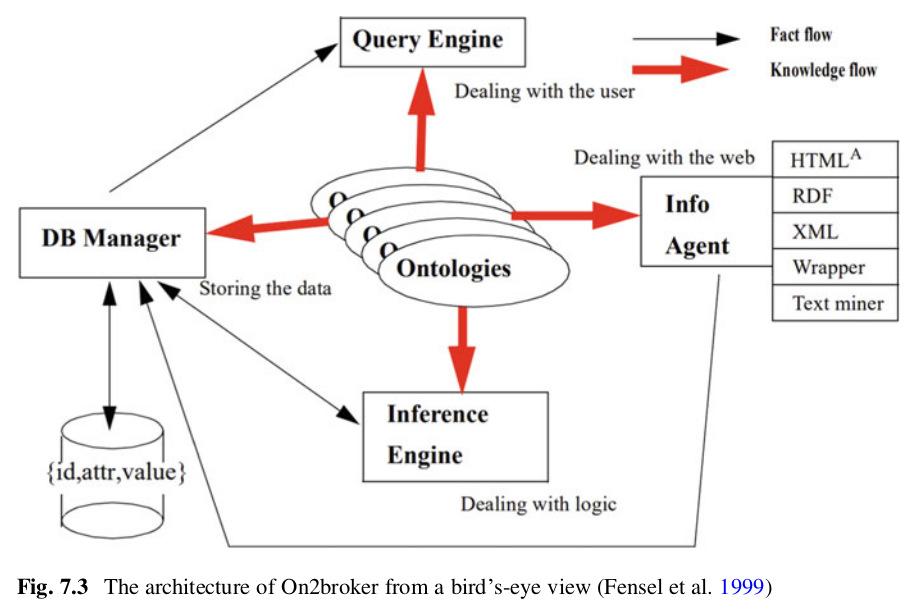
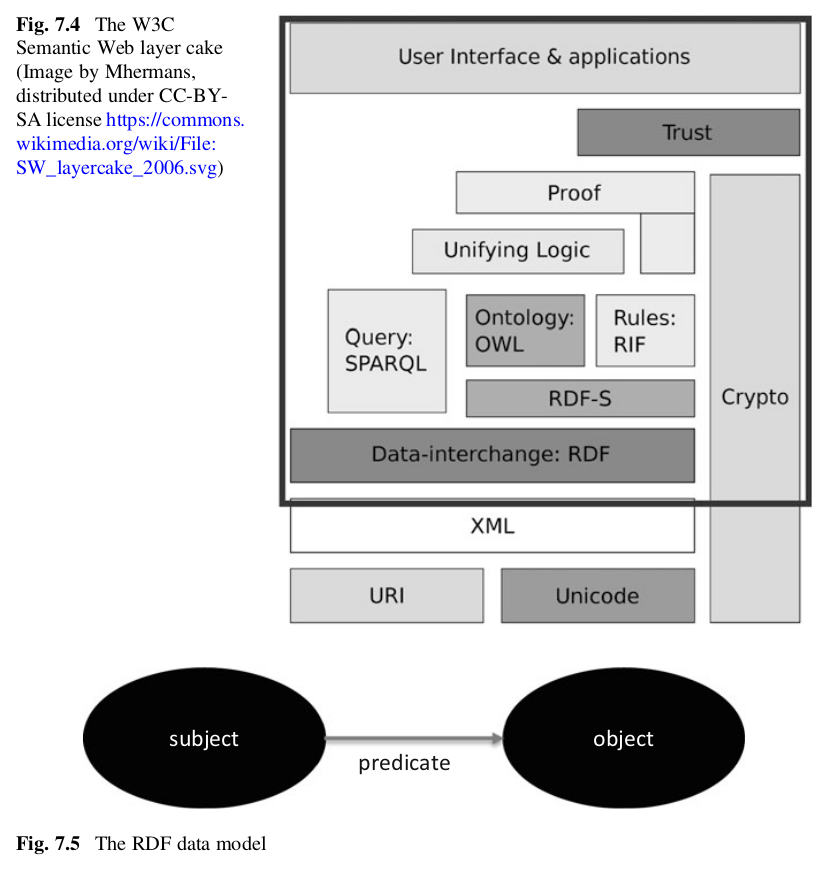
🧾 What Is an XML Schema?
An XML Schema (often written as XSD, for XML Schema Definition) is a way to define the structure, content, and data types of XML documents.
It acts like a blueprint for XML files — ensuring that the data follows specific rules and formats.
✅ Key Purposes of XML Schema
-
Validation: Ensures that an XML file is “valid” (i.e., it adheres to the structure and data rules defined in the schema).
-
Data Typing: Allows elements and attributes to have types like
integer,string,date, etc. -
Structure Definition: Describes elements, attributes, nested elements, order, optional/required fields, etc.
-
Namespaces Support: Helps prevent name conflicts when combining XML from different sources.
🧱 Basic Example
XML File (data.xml):
<person> <name>Frank</name> <age>40</age> </person>
XSD File (person.xsd):
<?xml version="1.0"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"> <xs:element name="person"> <xs:complexType> <xs:sequence> <xs:element name="name" type="xs:string"/> <xs:element name="age" type="xs:int"/> </xs:sequence> </xs:complexType> </xs:element> </xs:schema>
This schema enforces:
-
The root element must be
<person> -
It must contain
<name>(a string) and<age>(an integer) in order
🛠 Common XSD Features
-
xs:element: Defines XML elements -
xs:attribute: Defines attributes -
xs:complexType: Groups nested elements -
xs:simpleType: Restricts or defines custom scalar types -
Data types:
xs:string,xs:integer,xs:boolean,xs:date, etc.

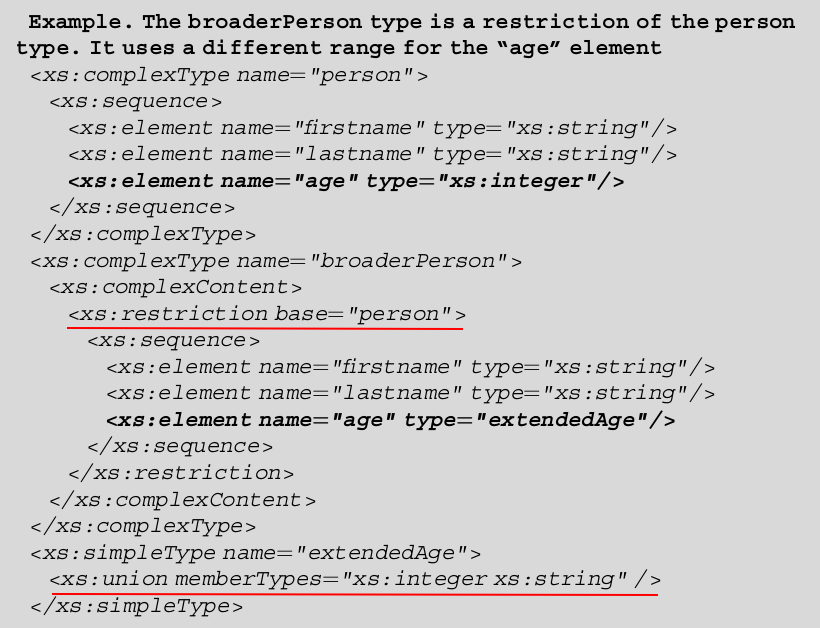
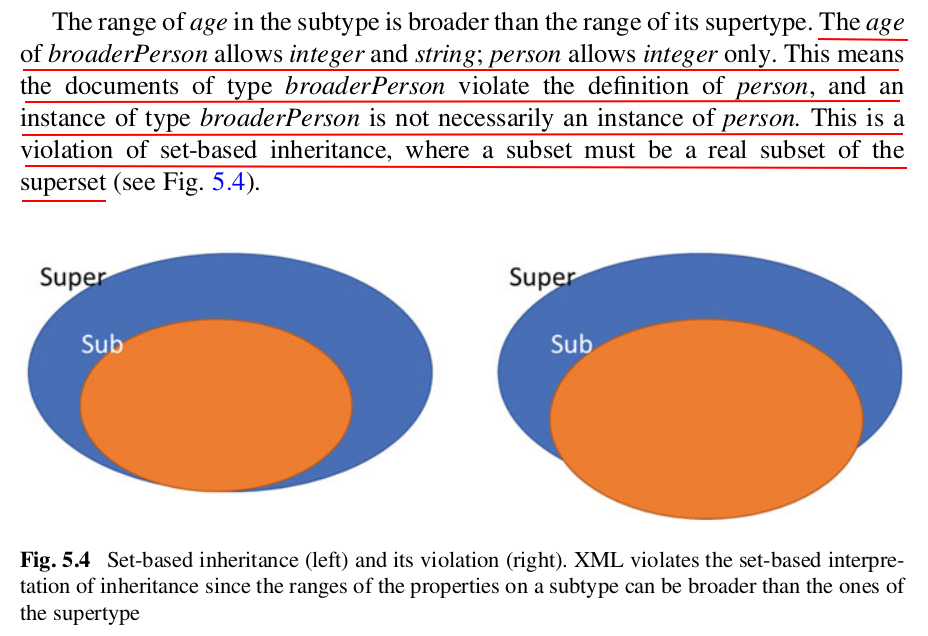








 RDF
RDF

 SPARQL
SPARQL






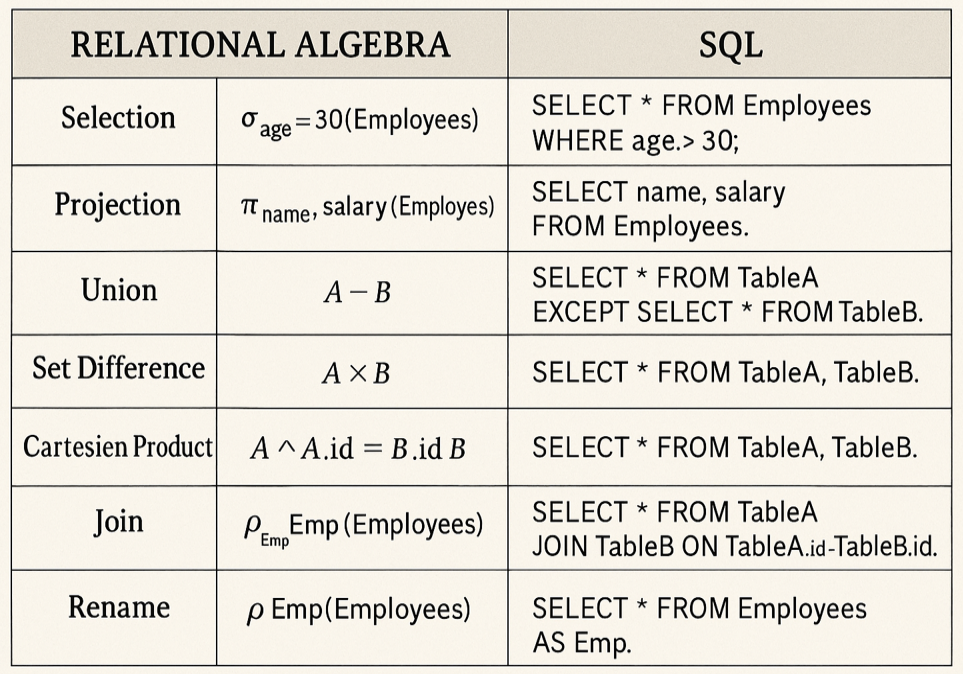
Relational algebra is a formal language used to query and manipulate relational databases. It provides a set of operations that take one or more relations (tables) as input and produce a new relation as output, without modifying the original data.
Key Concepts:
-
Relation: A table with rows and columns.
-
Tuple: A row in a table.
-
Attribute: A column in a table.
Common Operations in Relational Algebra:
-
Selection (σ): Filters rows based on a condition.
-
Example: σ<sub>age > 30</sub>(Employees)
-
-
Projection (π): Selects specific columns.
-
Example: π<sub>name, salary</sub>(Employees)
-
-
Union (⋃): Combines two relations, removing duplicates.
-
Example: A ⋃ B
-
-
Set Difference (−): Finds tuples in one relation but not in another.
-
Example: A − B
-
-
Cartesian Product (×): Combines all tuples of two relations.
-
Example: A × B
-
-
Rename (ρ): Renames a relation or its attributes.
-
Example: ρ<sub>NewName</sub>(Employees)
-
-
Join (⨝): Combines related tuples from two relations based on a condition.
-
Example: A ⨝<sub>A.id = B.id</sub> B
-
Relational algebra is procedural, meaning it describes how to get the result, and it's foundational to understanding SQL and relational database design.
Relational algebra is not a programming language in the traditional sense (like Python or Java). Instead, it is a formal system of algebra used in the field of databases.
More precisely:
-
It is a mathematical query language for relational databases.
-
It provides a set of algebraic operations (like union, projection, join) to manipulate relations (tables).
-
It forms the theoretical foundation of SQL and other database query languages.
So, it's best described as a kind of algebra specifically designed to model and manipulate relational data.
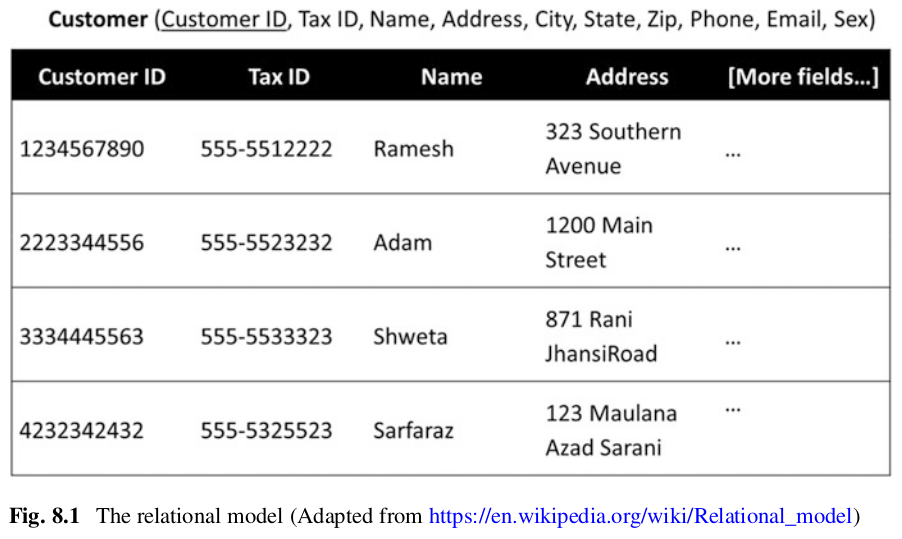
Here's a comparison between Relational Algebra and SQL for common operations. We'll use a sample relation (table) called Employees.
Sample Table: Employees
| id | name | age | salary |
|---|---|---|---|
| 1 | Alice | 30 | 5000 |
| 2 | Bob | 40 | 6000 |
| 3 | Carol | 25 | 4500 |







 GraphDB
GraphDB




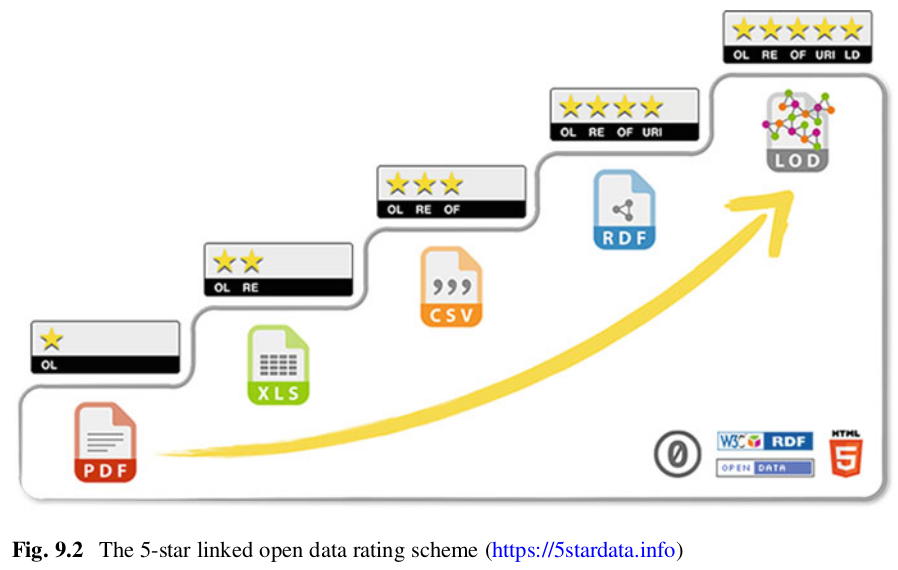
Is your Linked Open Data 5 Star?
Under the star scheme, you get one (big!) star if the information has been made public at all, even if it is a photo of a scan of a fax of a table -- if it has an open licence. The you get more stars as you make it progressively more powerful, easier for people to use.
| ★ | Available on the web (whatever format) but with an open licence, to be Open Data |
| ★★ | Available as machine-readable structured data (e.g. excel instead of image scan of a table) |
| ★★★ | as (2) plus non-proprietary format (e.g. CSV instead of excel) |
| ★★★★ | All the above plus, Use open standards from W3C (RDF and SPARQL) to identify things, so that people can point at your stuff |
| ★★★★★ | All the above, plus: Link your data to other people’s data to provide context |












 浙公网安备 33010602011771号
浙公网安备 33010602011771号