

GenAI integrations
Neo4j’s Vector indexes and Vector functions allow you to calculate the similarity between node and relationship properties in a graph. A prerequisite for using these features is that vector embeddings have been set as properties of these entities. The GenAI plugin enables the creation of such embeddings using GenAI providers.
To use the GenAI plugin you need an account and API credentials from any of the following GenAI providers: Vertex AI, OpenAI, Azure OpenAI, and Amazon Bedrock.
To learn more about using embeddings in Neo4j, see Vector indexes → Vectors and embeddings in Neo4j.
For a hands-on guide on how to use the GenAI plugin, see GenAI documentation - Embeddings & Vector Indexes Tutorial → Create embeddings with cloud AI providers.
Installation
The GenAI plugin is enabled by default in Neo4j Aura.
The plugin needs to be installed on self-managed instances. This is done by moving the neo4j-genai.jar file from /products to /plugins in the Neo4j home directory, or, if you are using Docker, by starting the Docker container with the extra parameter --env NEO4J_PLUGINS='["genai"]'. For more information, see Operations Manual → Configure plugins.
Example graph
The examples on this page use the Neo4j movie recommendations dataset, focusing on the plot and embedding properties of Movie nodes. The embedding property consists of a 1536-dimension vector embedding of the plot and title property combined.
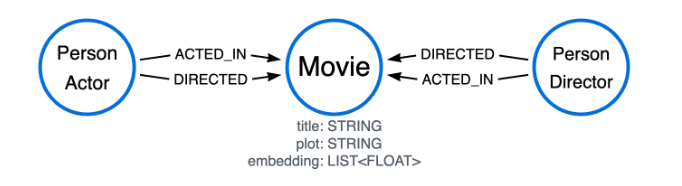
The graph contains 28863 nodes and 332522 relationships.
To recreate the graph, download and import this dump file to an empty Neo4j database (running version 5.13 or later). Dump files can be imported for both Aura and on-prem instances.
DROP DATABASE neo4j;
zzh@ZZHPC:/var/log/neo4j$ sudo systemctl stop neo4j
zzh@ZZHPC:~/Downloads/dumpfiles$ lh total 112M -rw-rw-r-- 1 zzh zzh 112M 3月 9 18:48 recommendations-embeddings-50.dump zzh@ZZHPC:~/Downloads/dumpfiles$ sudo neo4j-admin database load --from-path=/home/zzh/Downloads/dumpfiles --verbose --overwrite-destination=true neo4j Executing command line: /usr/lib/jvm/java-21-openjdk-amd64/bin/java -cp /var/lib/neo4j/plugins/*:/etc/neo4j/*:/usr/share/neo4j/lib/* -XX:+UseParallelGC -XX:-OmitStackTraceInFastThrow -XX:+UnlockExperimentalVMOptions -XX:+TrustFinalNonStaticFields -XX:+DisableExplicitGC -Djdk.nio.maxCachedBufferSize=1024 -Dio.netty.tryReflectionSetAccessible=true -XX:+ExitOnOutOfMemoryError -Djdk.tls.ephemeralDHKeySize=2048 -XX:FlightRecorderOptions=stackdepth=256 -XX:+UnlockDiagnosticVMOptions -XX:+DebugNonSafepoints --add-opens=java.base/java.nio=ALL-UNNAMED --add-opens=java.base/java.io=ALL-UNNAMED --add-opens=java.base/sun.nio.ch=ALL-UNNAMED --enable-native-access=ALL-UNNAMED -Dlog4j2.disable.jmx=true -Dfile.encoding=UTF-8 org.neo4j.cli.AdminTool database load --from-path=/home/zzh/Downloads/dumpfiles --verbose --overwrite-destination=true neo4j neo4j 2025.02.0 VM Name: OpenJDK 64-Bit Server VM VM Vendor: Ubuntu VM Version: 21.0.6+7-Ubuntu-122.04.1 JIT compiler: HotSpot 64-Bit Tiered Compilers VM Arguments: [-XX:+UseParallelGC, -XX:-OmitStackTraceInFastThrow, -XX:+UnlockExperimentalVMOptions, -XX:+TrustFinalNonStaticFields, -XX:+DisableExplicitGC, -Djdk.nio.maxCachedBufferSize=1024, -Dio.netty.tryReflectionSetAccessible=true, -XX:+ExitOnOutOfMemoryError, -Djdk.tls.ephemeralDHKeySize=2048, -XX:FlightRecorderOptions=stackdepth=256, -XX:+UnlockDiagnosticVMOptions, -XX:+DebugNonSafepoints, --add-opens=java.base/java.nio=ALL-UNNAMED, --add-opens=java.base/java.io=ALL-UNNAMED, --add-opens=java.base/sun.nio.ch=ALL-UNNAMED, --enable-native-access=ALL-UNNAMED, -Dlog4j2.disable.jmx=true, -Dfile.encoding=UTF-8] Configuration files used (ordered by priority): /etc/neo4j/neo4j-admin.conf /etc/neo4j/neo4j.conf -------------------- Failed to load database 'neo4j': No matching archives found Load failed for databases: 'neo4j' Full exception details written to: /var/log/neo4j/neo4j-admin-exception-trace-2025-03-10.17.07.24.log Please provide this file if requesting neo4j support org.neo4j.cli.CommandFailedException: Load failed for databases: 'neo4j' at org.neo4j.commandline.dbms.LoadCommand.checkFailure(LoadCommand.java:305) at org.neo4j.commandline.dbms.LoadCommand.loadDump(LoadCommand.java:288) at com.neo4j.commandline.dbms.EnterpriseLoadCommand.loadDump(EnterpriseLoadCommand.java:31) at org.neo4j.commandline.dbms.LoadCommand.loadDump(LoadCommand.java:246) at org.neo4j.commandline.dbms.LoadCommand.execute(LoadCommand.java:174) at org.neo4j.cli.AbstractAdminCommand.wrappedExecute(AbstractAdminCommand.java:203) at org.neo4j.cli.AbstractCommand.call(AbstractCommand.java:97) at org.neo4j.cli.AbstractCommand.call(AbstractCommand.java:37) at picocli.CommandLine.executeUserObject(CommandLine.java:2045) at picocli.CommandLine.access$1500(CommandLine.java:148) at picocli.CommandLine$RunLast.executeUserObjectOfLastSubcommandWithSameParent(CommandLine.java:2465) at picocli.CommandLine$RunLast.handle(CommandLine.java:2457) at picocli.CommandLine$RunLast.handle(CommandLine.java:2419) at picocli.CommandLine$AbstractParseResultHandler.execute(CommandLine.java:2277) at picocli.CommandLine$RunLast.execute(CommandLine.java:2421) at picocli.CommandLine.execute(CommandLine.java:2174) at org.neo4j.cli.AdminTool.execute(AdminTool.java:94) at org.neo4j.cli.AdminTool.main(AdminTool.java:82) Caused by: org.neo4j.cli.CommandFailedException: No matching archives found at org.neo4j.commandline.dbms.LoadCommand.loadDump(LoadCommand.java:268) ... 16 more
neo4j-admin database load expects the file to be named <database>.dump.
zzh@ZZHPC:~/Downloads/dumpfiles$ mv recommendations-embeddings-50.dump neo4j.dump zzh@ZZHPC:~/Downloads/dumpfiles$ chmod a+rx ~ zzh@ZZHPC:~/Downloads/dumpfiles$ sudo -u neo4j neo4j-admin database load --from-path=/home/zzh/Downloads/dumpfiles --verbose --overwrite-destination=true neo4j Executing command line: /usr/lib/jvm/java-21-openjdk-amd64/bin/java -cp /var/lib/neo4j/plugins/*:/etc/neo4j/*:/usr/share/neo4j/lib/* -XX:+UseParallelGC -XX:-OmitStackTraceInFastThrow -XX:+UnlockExperimentalVMOptions -XX:+TrustFinalNonStaticFields -XX:+DisableExplicitGC -Djdk.nio.maxCachedBufferSize=1024 -Dio.netty.tryReflectionSetAccessible=true -XX:+ExitOnOutOfMemoryError -Djdk.tls.ephemeralDHKeySize=2048 -XX:FlightRecorderOptions=stackdepth=256 -XX:+UnlockDiagnosticVMOptions -XX:+DebugNonSafepoints --add-opens=java.base/java.nio=ALL-UNNAMED --add-opens=java.base/java.io=ALL-UNNAMED --add-opens=java.base/sun.nio.ch=ALL-UNNAMED --enable-native-access=ALL-UNNAMED -Dlog4j2.disable.jmx=true -Dfile.encoding=UTF-8 org.neo4j.cli.AdminTool database load --from-path=/home/zzh/Downloads/dumpfiles --verbose --overwrite-destination=true neo4j neo4j 2025.02.0 VM Name: OpenJDK 64-Bit Server VM VM Vendor: Ubuntu VM Version: 21.0.6+7-Ubuntu-122.04.1 JIT compiler: HotSpot 64-Bit Tiered Compilers VM Arguments: [-XX:+UseParallelGC, -XX:-OmitStackTraceInFastThrow, -XX:+UnlockExperimentalVMOptions, -XX:+TrustFinalNonStaticFields, -XX:+DisableExplicitGC, -Djdk.nio.maxCachedBufferSize=1024, -Dio.netty.tryReflectionSetAccessible=true, -XX:+ExitOnOutOfMemoryError, -Djdk.tls.ephemeralDHKeySize=2048, -XX:FlightRecorderOptions=stackdepth=256, -XX:+UnlockDiagnosticVMOptions, -XX:+DebugNonSafepoints, --add-opens=java.base/java.nio=ALL-UNNAMED, --add-opens=java.base/java.io=ALL-UNNAMED, --add-opens=java.base/sun.nio.ch=ALL-UNNAMED, --enable-native-access=ALL-UNNAMED, -Dlog4j2.disable.jmx=true, -Dfile.encoding=UTF-8] Configuration files used (ordered by priority): /etc/neo4j/neo4j-admin.conf /etc/neo4j/neo4j.conf -------------------- Done: 119 files, 161.6MiB processed in 0.432 seconds. WARNING: The database: neo4j has a deprecated store format: standard. For details on deprecated store formats, see https://neo4j.com/docs/store-format-deprecations.
zzh@ZZHPC:~/Downloads/dumpfiles$ sudo systemctl start neo4j
CREATE DATABASE neo4j;

Generate a single embedding and store it
Use the genai.vector.encode() function to generate a vector embedding for a single value.
genai.vector.encode() Functiongenai.vector.encode(resource :: STRING, provider :: STRING, configuration :: MAP = {}) :: LIST<FLOAT>-
The
resource(aSTRING) is the object to transform into an embedding, such as a chunk text or a node/relationship property. -
The
provider(aSTRING) is the case-insensitive identifier of the provider to use. See identifiers under GenAI providers for supported options. -
The
configuration(aMAP) contains provider-specific settings, such as which model to invoke, as well as any required API credentials. See GenAI providers for details of each supported provider. Note that because this argument may contain sensitive data, it is obfuscated in the query.log. However, if the function call is misspelled or the query is otherwise malformed, it may be logged without being obfuscated.

Use the db.create.setNodeVectorProperty procedure to store an embedding to a node property.
db.create.setNodeVectorProperty Proceduredb.create.setNodeVectorProperty(node :: NODE, key :: STRING, vector :: ANY)Use the db.create.setRelationshipVectorProperty procedure to store an embedding to a relationship property.
db.create.setRelationshipVectorProperty Procedure Introduced in 5.18db.create.setRelationshipVectorProperty(relationship :: RELATIONSHIP, key :: STRING, vector :: ANY)-
nodeorrelationshipis the entity in which the new property will be stored. -
key(aSTRING) is the name of the new property containing the embedding. -
vectoris the object containing the embedding.
The embeddings are stored as properties on nodes or relationships with the type LIST<INTEGER | FLOAT>.
Example 1. Create an embedding from a single property and store it
MATCH (m:Movie {title:'Godfather, The'})
WHERE m.plot IS NOT NULL AND m.title IS NOT NULL
WITH m, m.title || ' ' || m.plot AS titleAndPlot
WITH m, genai.vector.encode(titleAndPlot, 'OpenAI', { token: $token }) AS propertyVector
CALL db.create.setNodeVectorProperty(m, 'embedding', propertyVector)
RETURN m.embedding AS embedding
- Concatenate the
titleandplotof theMovieinto a singleSTRING. - Create a 1536 dimensional embedding from the
titleAndPlot. - Store the
propertyVectoras a newembeddingproperty on The Godfather node.
+----------------------------------------------------------------------------------------------------+ | embedding | +----------------------------------------------------------------------------------------------------+ | [0.005239539314061403, -0.039358530193567276, -0.0005175105179660022, -0.038706034421920776, ... ] | +----------------------------------------------------------------------------------------------------+
Generating a batch of embeddings and store them
Use the genai.vector.encodeBatch procedure to generate many vector embeddings with a single API request. This procedure takes a list of resources as an input, and returns the same number of result rows, instead of a single one.

genai.vector.encodeBatch Proceduregenai.vector.encodeBatch(resources :: LIST<STRING>, provider :: STRING, configuration :: MAP = {}) :: (index :: INTEGER, resource :: STRING, vector :: LIST<FLOAT>)-
The
resources(aLIST<STRING>) parameter is the list of objects to transform into embeddings, such as chunks of text. -
The
provider(aSTRING) is the case-insensitive identifier of the provider to use. See GenAI providers for supported options. -
The
configuration(aMAP) specifies provider-specific settings such as which model to invoke, as well as any required API credentials. See GenAI providers for details of each supported provider. Note that because this argument may contain sensitive data, it is obfuscated in the query.log. However, if the function call is misspelled or the query is otherwise malformed, it may be logged without being obfuscated.
Each returned row contains the following columns:
-
The
index(anINTEGER) is the index of the corresponding element in the input list, to aid in correlating results back to inputs. -
The
resource(aSTRING) is the name of the input resource. -
The
vector(aLIST<FLOAT>) is the generated vector embedding for this resource.
Example 2. Create embeddings from a limited number of properties and store them
MATCH (m:Movie WHERE m.plot IS NOT NULL)
WITH m
LIMIT 20
WITH collect(m) AS moviesList
WITH moviesList, [movie IN moviesList | movie.title || ': ' || movie.plot] AS batch
CALL genai.vector.encodeBatch(batch, 'OpenAI', { token: $token }) YIELD index, vector
WITH moviesList, index, vector
CALL db.create.setNodeVectorProperty(moviesList[index], 'embedding', vector)
- Collect all 20 Movie nodes into a LIST<NODE>.
- Use a list comprehension ([]) to extract the title and plot properties of the movies in moviesList into a new LIST<STRING>.
- db.create.setNodeVectorProperty is run for each vector returned by genai.vector.encodeBatch, and stores that vector as a property named embedding on the corresponding node.
Example 3. Create embeddings from a large number of properties and store them
MATCH (m:Movie WHERE m.plot IS NOT NULL)
WITH collect(m) AS moviesList,
count(*) AS total,
100 AS batchSize
UNWIND range(0, total-1, batchSize) AS batchStart
CALL (moviesList, batchStart, batchSize) {
WITH [movie IN moviesList[batchStart .. batchStart + batchSize] | movie.title || ': ' || movie.plot] AS batch
CALL genai.vector.encodeBatch(batch, 'OpenAI', { token: $token }) YIELD index, vector
CALL db.create.setNodeVectorProperty(moviesList[batchStart + index], 'embedding', vector)
} IN CONCURRENT TRANSACTIONS OF 1 ROW
UNWIND range(0, 100 - 1, 10) AS batchStart RETURN batchStart
╒══════════╕ │batchStart│ ╞══════════╡ │0 │ ├──────────┤ │10 │ ├──────────┤ │20 │ ├──────────┤ │30 │ ├──────────┤ │40 │ ├──────────┤ │50 │ ├──────────┤ │60 │ ├──────────┤ │70 │ ├──────────┤ │80 │ ├──────────┤ │90 │ └──────────┘
- Collect all returned Movie nodes into a LIST<NODE>.
- batchSize defines the number of nodes in moviesList to be processed at once. Because vector embeddings can be very large, a larger batch size may require significantly more memory on the Neo4j server. Too large a batch size may also exceed the provider’s threshold.
- Process Movie nodes in increments of batchSize. The end range total-1 is due to range being inclusive on both ends.
- A CALL subquery executes a separate transaction for each batch. Note that this CALL subquery uses a variable scope clause (introduced in Neo4j 5.23) to import variables. If you are using an older version of Neo4j, use an importing WITH clause instead.
- batch is a list of strings, each being the concatenation of title and plot of one movie.
- The procedure sets vector as value for the property named embedding for the node at position batchStart + index in the moviesList.
- Set to 1 the amount of batches to be processed at once. Concurrency in transactions was introduced in Cypher 5.21 (see CALL subqueries → Concurrent transactions).

GenAI providers
The following GenAI providers are supported for generating vector embeddings. Each provider has its own configuration map that can be passed to genai.vector.encode or genai.vector.encodeBatch.
Vertex AI
-
Identifier (
providerargument):"VertexAI"
Azure OpenAI
-
Identifier (
providerargument):"AzureOpenAI"
| Unlike the other providers, the model is configured when creating the deployment on Azure, and is thus not part of the configuration map. |
Amazon Bedrock
-
Identifier (
providerargument):"Bedrock"
Indexes
Neo4j supports two categories of indexes:
-
Search-performance indexes, for speeding up data retrieval based on exact matches. This category includes range, text, point, and token lookup indexes.
-
Semantic indexes, for approximate matches and to compute similarity scores between a query string and the matching data. This category includes full-text and vector indexes.
Search-performance indexes
Search-performance indexes enable quicker retrieval of exact matches between an index and the primary data storage. There are four different search-performance indexes available in Neo4j:
-
Range indexes: Neo4j’s default index. Supports most types of predicates.
-
Text indexes: solves predicates operating on
STRINGvalues. Optimized for queries filtering with theSTRINGoperatorsCONTAINSandENDS WITH. -
Point indexes: solves predicates on spatial
POINTvalues. Optimized for queries filtering on distance or within bounding boxes. -
Token lookup indexes: only solves node label and relationship type predicates (i.e. they cannot solve any predicates filtering on properties). Two token lookup indexes (one for node labels and one for relationship types) are present when a database is created in Neo4j.
CREATE INDEX
Creating an index is done with the CREATE … INDEX … command. If no index type is specified in the create command a range index will be created.
Best practice is to give the index a name when it is created. If the index is not explicitly named, it gets an auto-generated name.
|
The index name must be unique among both indexes and constraints. |
Create a range index
Range indexes have no supported index configuration.
Supported predicates
Range indexes support most types of predicates:
| Predicate | Syntax |
|---|---|
|
Equality check. |
|
|
List membership check. |
|
|
Existence check. |
|
|
Range search. |
|
|
Prefix search. |
|
Create a single-property range index for nodes
CREATE INDEX node_range_index_name FOR (n:Person) ON (n.surname)
Create a single-property range index for relationships
CREATE INDEX rel_range_index_name FOR ()-[r:KNOWS]-() ON (r.since)
Create a composite range index for nodes
CREATE INDEX composite_range_node_index_name FOR (n:Person) ON (n.age, n.country)
Create a composite range index for relationships
CREATE INDEX composite_range_rel_index_name FOR ()-[r:PURCHASED]-() ON (r.date, r.amount)
Create a range index using a parameter
{ "name": "range_index_param" }
CREATE INDEX $name FOR (n:Person) ON (n.firstname)
Create a range index only if it does not already exist
If it is not known whether an index exists or not, add IF NOT EXISTS to ensure it does.
CREATE INDEX node_range_index_name IF NOT EXISTS FOR (n:Person) ON (n.surname)
Create a text index
Creating a text index can be done with the CREATE TEXT INDEX command. Text indexes have no supported index configuration.
Supported predicates
Text indexes only solve predicates operating on STRING values.
The following predicates that only operate on STRING values are always solvable by a text index:
-
STARTS WITH -
ENDS WITH -
CONTAINS
Text indexes support the following predicates:
| Predicate | Syntax |
|---|---|
|
Equality check. |
|
|
List membership check. |
|
|
Prefix search. |
|
|
Suffix search. |
|
|
Substring search. |
|
Trigram indexing
The default text index provider, text-2.0, uses trigram indexing. This means that STRING values are indexed into overlapping trigrams, each containing three Unicode code points. For example, the word "developer" would be indexed by the following trigrams: ["dev", "eve", "vel", "elo", "lop", "ope", "per"].
This makes text indexes particularly suitable for substring (CONTAINS) and suffix (ENDS WITH) searches, as well as prefix searches (STARTS WITH). For example, searches like CONTAINS "vel" or ENDS WITH "per" can be efficiently performed by directly looking up the relevant trigrams in the index. By comparison, range indexes, which indexes STRING values lexicographically (see Range index-backed ORDER BY for more information) and are therefore more suited for prefix searches, would need to scan through all indexed values to check if "vel" existed anywhere within the text. For more information, see The impact of indexes on query performance → Text indexes.
Create a node text index
CREATE TEXT INDEX node_text_index_nickname FOR (n:Person) ON (n.nickname)
Create a relationship text index
CREATE TEXT INDEX rel_text_index_name FOR ()-[r:KNOWS]-() ON (r.interest)
Create a text index using a parameter
Create a text index only if it does not already exist
Create a point index
Creating a point index can be done with the CREATE POINT INDEX command. Point indexes have supported index configuration.
Supported predicates
Point indexes only solve predicates operating on POINT values.
Point indexes support the following predicates:
| Predicate | Syntax |
|---|---|
|
Property point value. |
|
|
Within bounding box. |
|
|
Distance. |
|
Create a node point index
CREATE POINT INDEX node_point_index_name FOR (n:Person) ON (n.sublocation)
Create a relationship point index
CREATE POINT INDEX rel_point_index_name FOR ()-[r:STREET]-() ON (r.intersection)
Create a point index using a parameter
Create a point index only if it does not already exist
Create a point index specifying the index configuration
To create a point index with a specific index configuration, the indexConfig settings in the OPTIONS clause. The valid configuration settings are:
-
spatial.cartesian.min(default value: [-1000000.0,-1000000.0]) -
spatial.cartesian.max(default value: [1000000.0,1000000.0]) -
spatial.cartesian-3d.min(default value: [-1000000.0,-1000000.0,-1000000.0]) -
spatial.cartesian-3d.max(default value: [1000000.0,1000000.0,1000000.0`]) -
spatial.wgs-84.min(default value: [-180.0,-90.0]) -
spatial.wgs-84.max(default value: [-180.0,-90.0]) -
spatial.wgs-84-3d.min(default value: [-180.0,-90.0,-1000000.0]) -
spatial.wgs-84-3d.max(default value: [180.0,90.0,1000000.0])
CREATE POINT INDEX point_index_with_config FOR (n:Label) ON (n.prop2) OPTIONS { indexConfig: { `spatial.cartesian.min`: [-100.0, -100.0], `spatial.cartesian.max`: [100.0, 100.0] } }
Create a token lookup index
Two token lookup indexes are created by default when creating a Neo4j database (one node label lookup index and one relationship type lookup index). Only one node label and one relationship type lookup index can exist at the same time.
If a token lookup index has been deleted, it can be recreated with the CREATE LOOKUP INDEX command. Token lookup indexes have no supported index configuration.
Supported predicates
Token lookup indexes are present by default and solve only node label and relationship type predicates:
| Predicate | Syntax (example) |
|---|---|
|
Node label predicate. |
|
|
Relationship type predicate. |
|
|
Token lookup indexes improve the performance of Cypher queries and the population of other indexes. Dropping these indexes may lead to severe performance degradation. |
Create a node label lookup index
CREATE LOOKUP INDEX node_label_lookup_index FOR (n) ON EACH labels(n)
Create a relationship type lookup index
CREATE LOOKUP INDEX rel_type_lookup_index FOR ()-[r]-() ON EACH type(r)
Create a token lookup index only if it does not already exist
SHOW INDEXES
SHOW INDEXES
DROP INDEX
DROP INDEX index_name [IF EXISTS]
Semantic indexes
Unlike search-performance indexes, semantic indexes capture the semantic meaning or context of the data in a database. This is done by returning an approximation score, which indicates the similarity between a query string and the data in a database.
Two semantic indexes are available in Neo4j:
-
Full-text indexes: enables searching within the content of
STRINGproperties and for similarity comparisons between query strings andSTRINGvalues stored in the database. -
Vector indexes: enables similarity searches and complex analytical queries by representing nodes or properties as vectors in a multidimensional space.

Full-text indexes
A full-text index is used to index nodes and relationships by STRING properties. Unlike range and text indexes, which can only perform limited STRING matching (exact, prefix, substring, or suffix matches), full-text indexes stores individual words in any given STRING property. This means that full-text indexes can be used to match within the content of a STRING property. Full-text indexes also return a score of proximity between a given query string and the STRING values stored in the database, thus enabling them to semantically interpret data.
Full-text indexes are powered by the Apache Lucene indexing and search library.
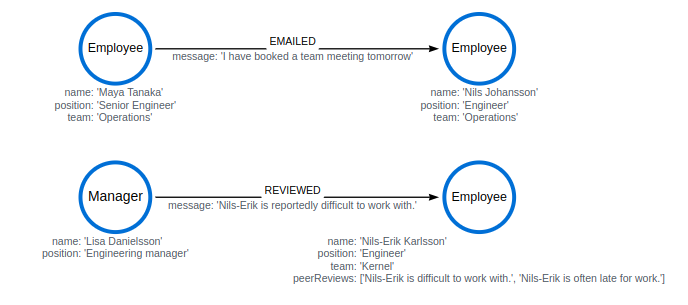
CREATE (nilsE:Employee {name: "Nils-Erik Karlsson", position: "Engineer", team: "Kernel", peerReviews: ['Nils-Erik is difficult to work with.', 'Nils-Erik is often late for work.']}),
(lisa:Manager {name: "Lisa Danielsson", position: "Engineering manager"}),
(nils:Employee {name: "Nils Johansson", position: "Engineer", team: "Operations"}),
(maya:Employee {name: "Maya Tanaka", position: "Senior Engineer", team:"Operations"}),
(lisa)-[:REVIEWED {message: "Nils-Erik is reportedly difficult to work with."}]->(nilsE),
(maya)-[:EMAILED {message: "I have booked a team meeting tomorrow."}]->(nils)
Create full-text indexes
Full-text indexes are created with the CREATE FULLTEXT INDEX command. It is recommended to to give the index a name when it is created. If no name is given when created, a random name will be assigned to the full-text index.
When creating a full-text index, you need to specify the labels/relationship types and property names it should apply to.
This statement creates a full-text index named namesAndTeams on each name and team property for nodes with the label Employee or Manager:
Create a full-text index on a node label and property combination
CREATE FULLTEXT INDEX namesAndTeams FOR (n:Employee|Manager) ON EACH [n.name, n.team]
This query highlights two key differences between full-text and search-performance indexes:
-
Full-text indexes can be applied to more than one node label.
-
Full-text indexes can be applied to more than one property, but unlike composite search-performance indexes, a full-text index stores entities that have at least one of the indexed labels or relationship types, and at least one of the indexed properties.
Similarly, though a relationship can have only one type, a full-text index can store multiple relationship types. In that case, all types matching at least one of the relationship types and at least one of the indexed properties will be included.
This statement creates a full-text index named communications on the message property for the relationship types REVIEWED and EMAILED:
Create a full-text index on a relationship type and property combination
CREATE FULLTEXT INDEX communications FOR ()-[r:REVIEWED|EMAILED]-() ON EACH [r.message]
Configuration settings
The CREATE FULLTEXT INDEX command takes an optional OPTIONS clause, where the indexConfig can be specified. The following statement creates a full-text index using a parameter for nodes with the label Employee or Manager.
{
"name": "peerReviews"
}
CREATE FULLTEXT INDEX $name FOR (n:Employee|Manager) ON EACH [n.peerReviews] OPTIONS { indexConfig: { `fulltext.analyzer`: 'english', `fulltext.eventually_consistent`: true } }
Query full-text indexes
Unlike search-performance indexes, full-text indexes are not automatically used by the Cypher® query planner. To query a full-text index, use either the db.index.fulltext.queryNodes or the db.index.fulltext.queryRelationships procedure.

This query uses the db.index.fulltext.queryNodes to look for nils in the previously created full-text index namesAndTeams:
CALL db.index.fulltext.queryNodes("namesAndTeams", "nils") YIELD node, score
RETURN node.name, score
╒════════════════════╤═══════════════════╕ │node.name │score │ ╞════════════════════╪═══════════════════╡ │"Nils Johansson" │0.3300700783729553 │ ├────────────────────┼───────────────────┤ │"Nils-Erik Karlsson"│0.27725890278816223│ └────────────────────┴───────────────────┘

This query uses the db.index.fulltext.queryRelationships to query the previously created communications full-text index for any message containing "meeting":
CALL db.index.fulltext.queryRelationships("communications", "meeting") YIELD relationship, score
RETURN type(relationship), relationship.message, score
╒══════════════════╤════════════════════════════════════════╤══════════════════╕ │type(relationship)│relationship.message │score │ ╞══════════════════╪════════════════════════════════════════╪══════════════════╡ │"EMAILED" │"I have booked a team meeting tomorrow."│0.3239005506038666│ └──────────────────┴────────────────────────────────────────┴──────────────────┘
To only obtain exact matches, quote the STRING you are searching for:
CALL db.index.fulltext.queryNodes("namesAndTeams", '"Nils-Erik"') YIELD node, score
RETURN node.name, score
╒════════════════════╤══════════════════╕ │node.name │score │ ╞════════════════════╪══════════════════╡ │"Nils-Erik Karlsson"│0.7588480710983276│ └────────────────────┴──────────────────┘
CALL db.index.fulltext.queryNodes("namesAndTeams", '"Nils"') YIELD node, score
RETURN node.name, score
╒════════════════════╤═══════════════════╕ │node.name │score │ ╞════════════════════╪═══════════════════╡ │"Nils Johansson" │0.3300700783729553 │ ├────────────────────┼───────────────────┤ │"Nils-Erik Karlsson"│0.27725890278816223│ └────────────────────┴───────────────────┘
Query strings also support the use of the Lucene boolean operators (AND, OR, NOT, +, -):
CALL db.index.fulltext.queryNodes("namesAndTeams", 'nils AND kernel') YIELD node, score
RETURN node.name, node.team, score
╒════════════════════╤═════════╤═════════════════╕ │node.name │node.team│score │ ╞════════════════════╪═════════╪═════════════════╡ │"Nils-Erik Karlsson"│"Kernel" │0.723090410232544│ └────────────────────┴─────────┴─────────────────┘
It is possible to limit the search to specific properties, by prefixing <propertyName>: to the query string.
CALL db.index.fulltext.queryNodes("namesAndTeams", 'team:"Operations"') YIELD node, score
RETURN node.name, node.team, score
╒════════════════╤════════════╤═══════════════════╕ │node.name │node.team │score │ ╞════════════════╪════════════╪═══════════════════╡ │"Nils Johansson"│"Operations"│0.21363800764083862│ ├────────────────┼────────────┼───────────────────┤ │"Maya Tanaka" │"Operations"│0.21363800764083862│ └────────────────┴────────────┴───────────────────┘
Lists of STRING values
If the indexed property contains a list of STRING values, each entry is analyzed independently and all produced tokens are associated to the same property name. This means that when querying such an indexed node or relationship, there is a match if any of the list elements matches the query string. For scoring purposes, the full-text index treats it as a single-property value, and the score will represent how close the query is to matching the entire list.
CALL db.index.fulltext.queryNodes('peerReviews', 'late') YIELD node, score
RETURN node.name, node.peerReviews, score
╒════════════════════╤═════════════════════════════════════════════════════════════════════════════╤═══════════════════╕ │node.name │node.peerReviews │score │ ╞════════════════════╪═════════════════════════════════════════════════════════════════════════════╪═══════════════════╡ │"Nils-Erik Karlsson"│["Nils-Erik is difficult to work with.", "Nils-Erik is often late for work."]│0.13076457381248474│ └────────────────────┴─────────────────────────────────────────────────────────────────────────────┴───────────────────┘
Show full-text indexes
SHOW FULLTEXT INDEXES
Drop full-text indexes
DROP INDEX communications
List of full-text index procedures
The procedures for full-text indexes are listed in the table below:
| Usage | Procedure/Command | Description |
|---|---|---|
|
Eventually consistent indexes. |
Wait for the updates from recently committed transactions to be applied to any eventually-consistent full-text indexes. |
|
|
List available analyzers. |
List the available analyzers that the full-text indexes can be configured with. |
|
|
Use full-text node index. |
Query the given full-text index. Returns the matching nodes and their Lucene query score, ordered by score. |
|
|
Use full-text relationship index. |
Query the given full-text index. Returns the matching relationships and their Lucene query score, ordered by score. |
Vector indexes
Vector indexes enable similarity searches and complex analytical queries by representing nodes or properties as vectors in a multidimensional space.
The following resources provide hands-on tutorials for working with LLMs and vector indexes in Neo4j:
Neo4j vector indexes are powered by the Apache Lucene indexing and search library.[1]


 浙公网安备 33010602011771号
浙公网安备 33010602011771号