



from delta import configure_spark_with_delta_pip from pyspark.sql import SparkSession from pyspark.sql.functions import when, rand import timeit builder = (SparkSession.builder .appName("optimize-table-partitions-delta") .master("spark://ZZHPC:7077") .config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") .config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")) spark = configure_spark_with_delta_pip(builder).getOrCreate() spark.sparkContext.setLogLevel("ERROR")
%load_ext sparksql_magic %config SparkSql.limit=20
# A large data frame with 1 million rows large_df = (spark.range(0, 1000000) .withColumn("salary", 100*(rand() * 100).cast("int")) .withColumn("gender", when((rand() * 2).cast("int") == 0, "M").otherwise("F")) .withColumn("country_code", when((rand() * 4).cast("int") == 0, "US") .when((rand() * 4).cast("int") == 1, "CN") .when((rand() * 4).cast("int") == 2, "IN") .when((rand() * 4).cast("int") == 3, "BR") .otherwise('RU'))) large_df.show(5)
+---+------+------+------------+ | id|salary|gender|country_code| +---+------+------+------------+ | 0| 4300| M| IN| | 1| 5800| M| RU| | 2| 3700| M| RU| | 3| 8500| F| RU| | 4| 9000| M| US| +---+------+------+------------+ only showing top 5 rows
(large_df.write.format("delta") .mode("overwrite") .save("../data/tmp/large_delta"))
Took about 3s to complete.
(large_df.write.format("delta") .mode("overwrite") .partitionBy("country_code") .option("overwriteSchema", "true") .save("../data/tmp/large_delta_partitioned"))
Took about 3s to complete.
non_partitioned_query = "spark.sql(\"SELECT country_code, gender, COUNT(*) AS employees FROM delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/tmp/large_delta` GROUP BY ALL ORDER BY employees DESC\").show()" non_partitioned_time = timeit.timeit(non_partitioned_query, number=1, globals=globals()) print(f"Non-partitioned query time: {non_partitioned_time} seconds")
+------------+------+---------+ |country_code|gender|employees| +------------+------+---------+ | RU| M| 158672| | RU| F| 157458| | US| M| 125400| | US| F| 124753| | CN| F| 93852| | CN| M| 93343| | IN| M| 70758| | IN| F| 70483| | BR| F| 52642| | BR| M| 52639| +------------+------+---------+ Non-partitioned query time: 1.6015754899999592 seconds
partitioned_query = "spark.sql(\"SELECT country_code, gender, COUNT(*) AS employees FROM delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/tmp/large_delta_partitioned` GROUP BY ALL ORDER BY employees DESC\").show()" partitioned_time = timeit.timeit(partitioned_query, number=1, globals=globals()) print(f"Partitioned query time: {partitioned_time} seconds")
+------------+------+---------+ |country_code|gender|employees| +------------+------+---------+ | RU| M| 158672| | RU| F| 157458| | US| M| 125400| | US| F| 124753| | CN| F| 93852| | CN| M| 93343| | IN| M| 70758| | IN| F| 70483| | BR| F| 52642| | BR| M| 52639| +------------+------+---------+ Partitioned query time: 0.7970797739981208 seconds
This shows that the partitioned query is twice as fast as the non-partitioned query.
spark.stop()



from delta import configure_spark_with_delta_pip, DeltaTable from pyspark.sql import SparkSession import timeit builder = (SparkSession.builder .appName("z-order-delta-table") .master("spark://ZZHPC:7077") .config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") .config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")) spark = configure_spark_with_delta_pip(builder).getOrCreate() spark.sparkContext.setLogLevel("ERROR")
%load_ext sparksql_magic %config SparkSql.limit=20
# Read the CSV file into a Spark DataFrame df = (spark.read .format("csv") .option("header", "true") .option("inferSchema", "true") .load("../data/Online_Retail.csv")) # Write the DataFrame into a Delta table (df.write .format("delta") .mode("overwrite") .save("../data/delta_lake/online_retail"))
# Query the original table query = "spark.sql(\"SELECT StockCode, CustomerID, SUM(Quantity) AS TotalQuantity FROM delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/online_retail` GROUP BY StockCode, CustomerID\").show()" query_time = timeit.timeit(query, number=1, globals=globals()) print(f"Time taken for original table: {query_time} seconds")
+---------+----------+-------------+ |StockCode|CustomerID|TotalQuantity| +---------+----------+-------------+ | 84744| 15281| 12| | 20723| 16112| 10| | 21577| 12393| 12| | 21314| 15346| 8| | 22364| 13408| 12| | 22326| 17965| 7| | 21390| 13488| 24| | 85169D| 15939| 72| | 21889| 14040| 5| | 84596F| 14514| 1| | 22150| 15835| 6| | 22182| 17019| 1| | 22755| 14215| 12| | 22515| 12578| 6| | 21071| 18106| 8| | 21507| 14646| 216| | 22956| 14329| 6| | 22630| 14156| 2| | 22278| 13455| 0| | 22778| 12924| 1| +---------+----------+-------------+ only showing top 20 rows Time taken for original table: 1.499758699999802 seconds

# Get the DeltaTable object for the online_retail table deltaTable = DeltaTable.forPath(spark, "/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/online_retail") # Optimize the table with Z-Ordering on StockCode and CustomerID deltaTable.optimize().executeZOrderBy("StockCode", "CustomerID")
Equivalent SQL Query:
OPTIMIZE delta_table_name
ZORDER BY (StockCode, CustomerID);
# Query the Z-Ordered table query = "spark.sql(\"SELECT StockCode, CustomerID, SUM(Quantity) AS TotalQuantity FROM delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/online_retail` GROUP BY StockCode, CustomerID\").show()" query_time = timeit.timeit(query, number=1, globals=globals()) print(f"Time taken for z-ordered table: {query_time} seconds")
+---------+----------+-------------+ |StockCode|CustomerID|TotalQuantity| +---------+----------+-------------+ | 84744| 15281| 12| | 20723| 16112| 10| | 21577| 12393| 12| | 21314| 15346| 8| | 22364| 13408| 12| | 22326| 17965| 7| | 21390| 13488| 24| | 85169D| 15939| 72| | 21889| 14040| 5| | 84596F| 14514| 1| | 22150| 15835| 6| | 22182| 17019| 1| | 22755| 14215| 12| | 22515| 12578| 6| | 21071| 18106| 8| | 21507| 14646| 216| | 22956| 14329| 6| | 22630| 14156| 2| | 22278| 13455| 0| | 22778| 12924| 1| +---------+----------+-------------+ only showing top 20 rows Time taken for z-ordered table: 0.6434761300006357 seconds
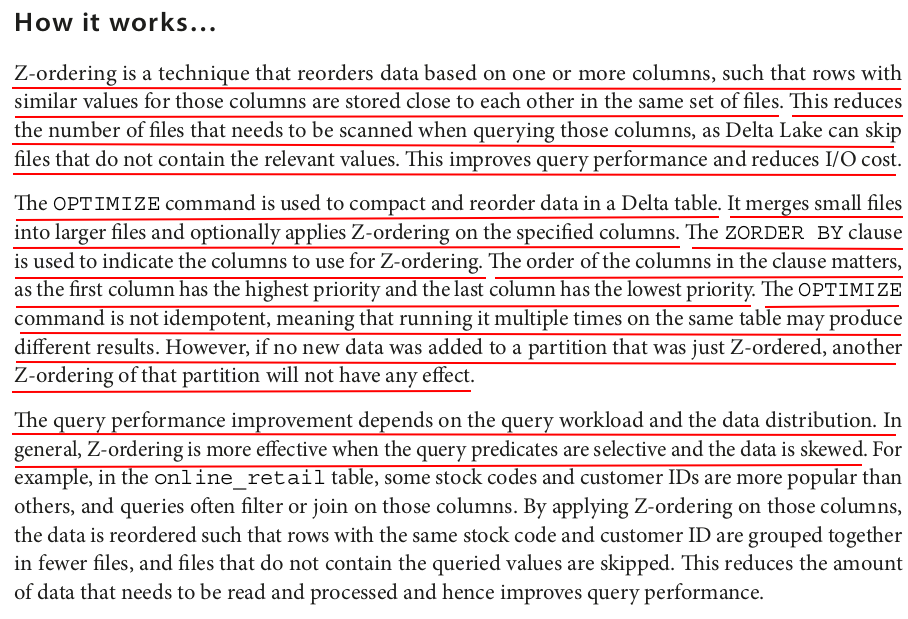
Z-Ordering in Delta Lake (PySpark & SQL)
Z-Ordering is a data skipping technique in Delta Lake that physically reorganizes data within Parquet files to improve query performance. It is particularly useful when filtering on multiple columns, reducing the amount of data read.
spark.stop()


from delta import configure_spark_with_delta_pip from pyspark.sql import SparkSession from pyspark.sql.functions import rand, when builder = (SparkSession.builder .appName("data-skipping-delta-table") .master("spark://ZZHPC:7077") .config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") .config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")) spark = configure_spark_with_delta_pip(builder).getOrCreate() spark.sparkContext.setLogLevel("ERROR")
%load_ext sparksql_magic %config SparkSql.limit=20
# A large data frame with 1 million rows df = (spark.range(0, 1000000) .withColumn("salary", 100*(rand() * 100).cast("int")) .withColumn("gender", when((rand() * 2).cast("int") == 0, "M").otherwise("F")) .withColumn("country_code", when((rand() * 4).cast("int") == 0, "US") .when((rand() * 4).cast("int") == 1, "CN") .when((rand() * 4).cast("int") == 2, "IN") .when((rand() * 4).cast("int") == 3, "BR") .otherwise('RU'))) df.show(5)
+---+------+------+------------+ | id|salary|gender|country_code| +---+------+------+------------+ | 0| 800| F| RU| | 1| 7500| F| BR| | 2| 9200| M| RU| | 3| 6600| F| RU| | 4| 500| M| RU| +---+------+------+------------+ only showing top 5 rows
(df.write .format("delta") .mode("overwrite") .save("../data/tmp/employee_salary"))

df = (spark.range(0, 1000) .withColumn("salary", 100*(rand() * 100).cast("int")) .withColumn("gender", when((rand() * 2).cast("int") == 0, "M").otherwise("F")) .withColumn("country_code", when((rand() * 4).cast("int") == 0, "US") .when((rand() * 4).cast("int") == 1, "CN") .when((rand() * 4).cast("int") == 2, "IN") .when((rand() * 4).cast("int") == 3, "BR") .otherwise('RU'))) (df.write .format("delta") .mode("append") .save("../data/tmp/employee_salary"))
%%sparksql DESCRIBE HISTORY delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/tmp/employee_salary`


%%sparksql OPTIMIZE delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/tmp/employee_salary`


spark.conf.set("spark.databricks.delta.retentionDurationCheck.enabled", "false")
%%sparksql VACUUM delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/tmp/employee_salary` RETAIN 0 HOURS

spark.stop()

from delta import configure_spark_with_delta_pip from pyspark.sql import SparkSession from pyspark.sql.functions import rand, when import timeit builder = (SparkSession.builder .appName("compression-delta-table") .master("spark://ZZHPC:7077") .config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") .config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")) spark = configure_spark_with_delta_pip(builder).getOrCreate() spark.sparkContext.setLogLevel("ERROR")
%load_ext sparksql_magic %config SparkSql.limit=20
# A large data frame with 1 million rows df = (spark.range(0, 1000000) .withColumn("salary", 100*(rand() * 100).cast("int")) .withColumn("gender", when((rand() * 2).cast("int") == 0, "M").otherwise("F")) .withColumn("country_code", when((rand() * 4).cast("int") == 0, "US") .when((rand() * 4).cast("int") == 1, "CN") .when((rand() * 4).cast("int") == 2, "IN") .when((rand() * 4).cast("int") == 3, "BR") .otherwise('RU'))) df.show(5)
+---+------+------+------------+ | id|salary|gender|country_code| +---+------+------+------------+ | 0| 8100| M| BR| | 1| 3500| M| US| | 2| 7800| F| RU| | 3| 1400| F| CN| | 4| 1500| F| BR| +---+------+------+------------+ only showing top 5 rows
# Write the DataFrame to a Delta Lake table with the default compression codec (snappy) (df.write.format("delta") .mode("overwrite") .save("../data/tmp/employee_salary_snappy"))
Snappy is a fast, block-based compression algorithm developed by Google. It is widely used in big data frameworks like Apache Spark, Hadoop, and Kafka due to its high speed and reasonable compression ratio.
query = "(spark.read.format(\"delta\").load(\"../data/tmp/employee_salary_snappy\").write.mode(\"overwrite\").format(\"noop\").save())" snappy_time = timeit.timeit(query, number=1, globals=globals()) print(f"Snappy Compression query time: {snappy_time} seconds")
Snappy Compression query time: 1.3332887329961522 seconds
- The "noop" (No-Operation) format is a dummy output format in Spark.
- It does not write data to any storage but executes the query plan as if it were writing.
- This is useful for benchmarking, debugging, and performance testing without actually persisting data.
 zstd, brotli
zstd, brotli

(df.write.format("delta") .mode("overwrite") .option("compression", "zstd") .save("../data/tmp/employee_salary_zstd"))

query = "(spark.read.format(\"delta\").load(\"../data/tmp/employee_salary_zstd\").write.mode(\"overwrite\").format(\"noop\").save())" zstd_time = timeit.timeit(query, number=1, globals=globals()) print(f"zstd Compression query time: {zstd_time} seconds")
zstd Compression query time: 0.854245324000658 seconds

spark.stop()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号