

Warning FailedScheduling 89s default-scheduler 0/1 nodes are available: 1 node(s) had untolerated taint {node.cloudprovider.kubernetes.io │
│ /uninitialized: true}. preemption: 0/1 nodes are available: 1 Preemption is not helpful for scheduling.. │
│ Warning FailedScheduling 77s default-scheduler 0/1 nodes are available: 1 Too many pods. preemption: 0/1 nodes are available: 1 No preemp │
│ tion victims found for incoming pod..
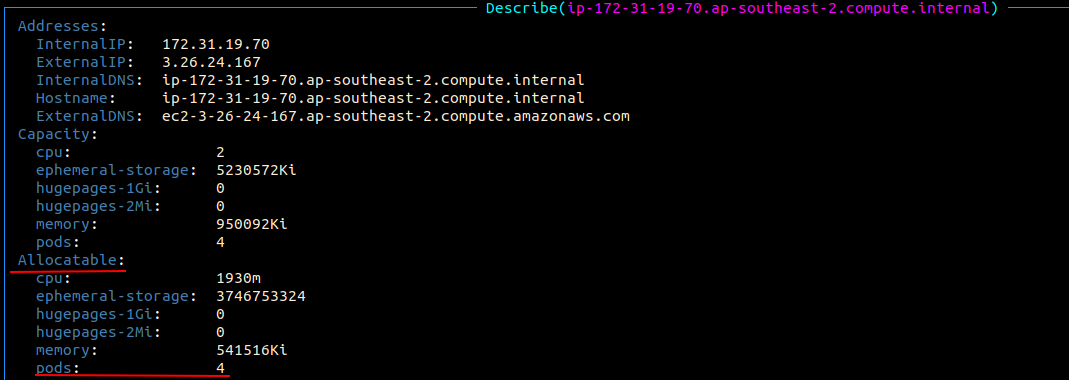
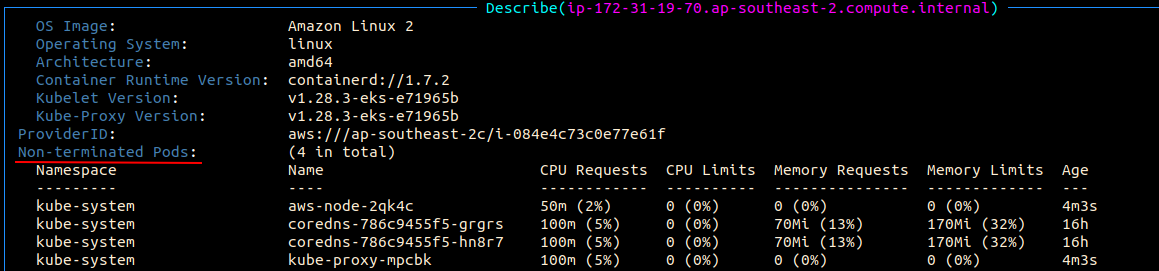
The cause is that 4 running kube-system pods have taken up all allocatable pod slots.
How the maximum number of pods is calculated can be found here: https://github.com/awslabs/amazon-eks-ami/blob/master/files/eni-max-pods.txt :
# Mapping is calculated from AWS EC2 API using the following formula: # * First IP on each ENI is not used for pods # * +2 for the pods that use host-networking (AWS CNI and kube-proxy) # # # of ENI * (# of IPv4 per ENI - 1) + 2 # # https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/using-eni.html#AvailableIpPerENI ...... t3.micro 4 t3.nano 4 t3.small 11 ......
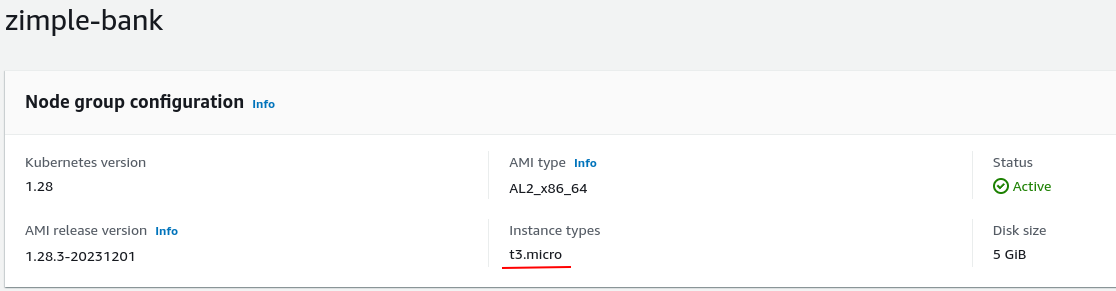
The resolution will be deleting the node group and creating a new one with instance type of t3.small.
After deleting the node group, need to manually delete the deployment, because deleting node group won't automatically delete deployment. By the way, deleting depoyment will delete its managed pods as well.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号