BERT笔记
- scratch:从头训练,随机初始化,不使用预训练参数
台大李宏毅老师机器学习2021
视频链接:https://pan.baidu.com/s/1VPwtRIWrYYdkLzEBD4D5cg
提取码:jetn《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
Background
在学习Bert之前一定要对Transformer和self-attention比较了解,Bert就是Transformer中的Encoder的变体。Bert是一种pre-train model,而pre-train model通常是一种比较通用的model,可以适应多种任务而非某种特定的任务(例如命名体识别等),其通常先通过一些不带标签的数据进行预训练,训练好之后根据其如何应用到下游任务可分为两种:Feature-Based Approach和Fine-Tune Approach。
下游任务指的是真正关心的任务,由于在预训练时根据某种任务(例如选词填空)来让模型理解语义信息,这可能和你真正要需要做的不是一种任务,可以理解为预训练类似于高考前做的各种专项训练,这种专项练习比起直接让你做高考试卷更容易让你理解和掌握知识点。
Unsupervised Feature-Based Approach
Feature-Based Approach是通过某种pre-train model将token嵌入到一个更恰当的Embedding中,在下游任务中直接将这些Embedding应用于下游任务即可,其中最典型的代表时Word2Vec和ELMO。
Unsupervised Fine-Tune Approach
Fine-Tune Approach是先通过某种特定的任务使用未标注数据来预训练模型,然后使用少量下游任务的标注数据来训练模型,第二步的过程叫做模型的微调(fine-tune)。在这里pre-train model类似于一种胚胎干细胞,第一步是生产一个良好的胚胎干细胞,然后通过一些引导可以使胚胎干细胞分化为特定的体细胞在机体中完成特定的任务,Bert就是一种Fine-Tune Approach。Fine-Tune Approach也可以理解为一种Semi-Supervised Learning。
Bert
Bert是一种Fine-Tune 方法,那它的使用一定分为预训练和微调两个步骤,接下来首先讲Bert的结构,然后讲Bert的使用。
Bert的结构
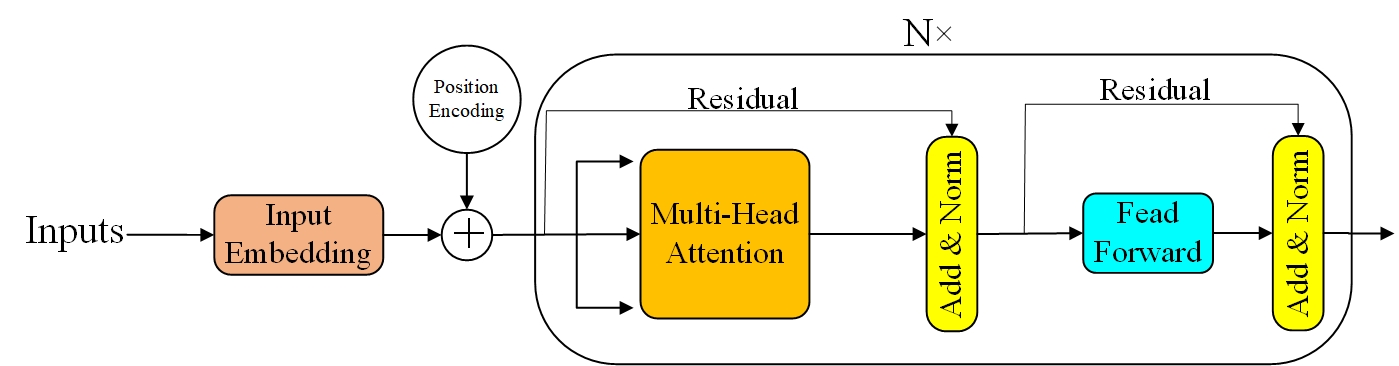
论文中说Bert的结构与Transformer中的Encoder结构几乎相同,如图1所示为Transformer的Encoder部分,在论文中模型的层数(Transformer block)表示为L,隐藏单元的大小表示为H,self-attention的head数量表示为A,在所有情况下,将feed-forward/filter的大小设置为4H,即H = 768时为3072,H = 1024时为4096。论文中提出了两种模型结构:
- \(BERT_{BASE}\):L=12,H=768,A=12,Total Parameters=110M
- \(BERT_{LARGE}\):L=24,H=1024,A=16, Total Parameters=340M
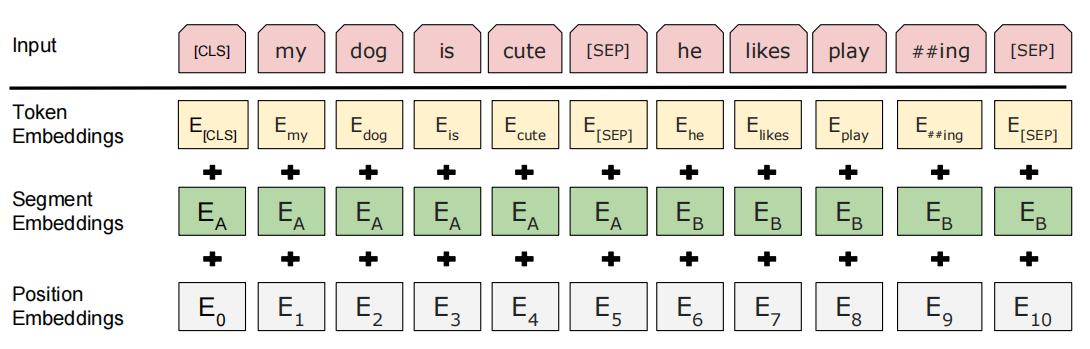
对于Bert的输入是通过将Token Embedding、Segment Embedding和Position Embedding相加得来的:
- Token Embedding:使用30000个token的词汇表的WordPiece嵌入,其中[CLS]和[SEP]为特殊标记,[CLS]总是位于Input的开始位置,[SEP]则是分隔符,用于分割两个句子,##表示分词符号
- Segment Embedding:用来区分句子的嵌入,如果是两个句子则对两个句子加上一个不同的Segment Embedding,如果只有一个句子则整个句子加上的Segment Embedding都相同
- Position Embedding:将位置信息嵌入到Input中
Pre-training BERT
Task #1: Masked LM
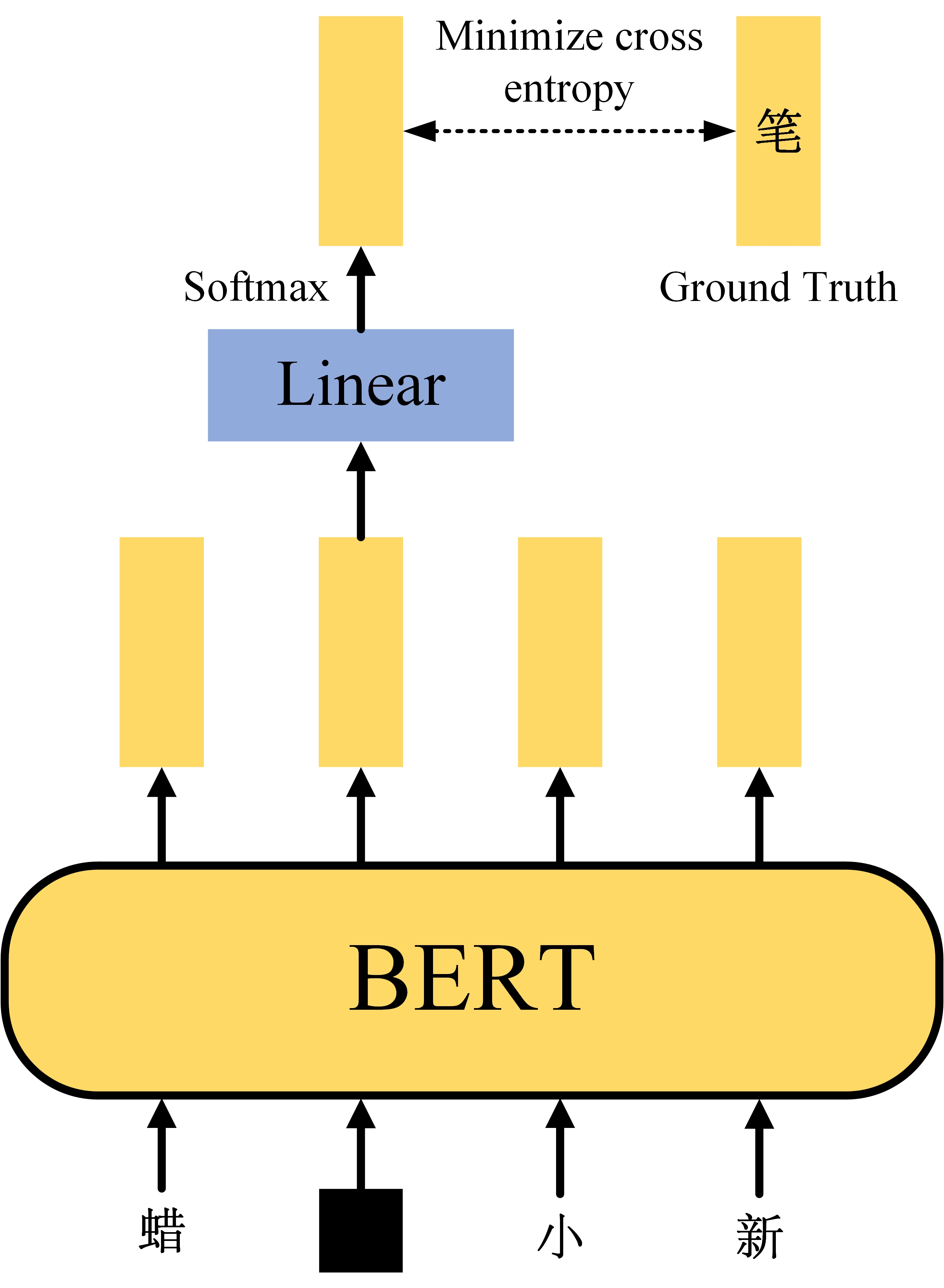
如图3是bert的第一种预训练方法完形填空,其使用一种Mask方法,可以是一个特殊标记或者随机替换,将Sequence中的部分给盖住,让bert预测出被盖住部分原始信息,注意在bert预测的过程中,只使用通过被盖住部分生成的输出向量进行预测。
Task #2 Next Sentence Prediction (NSP)
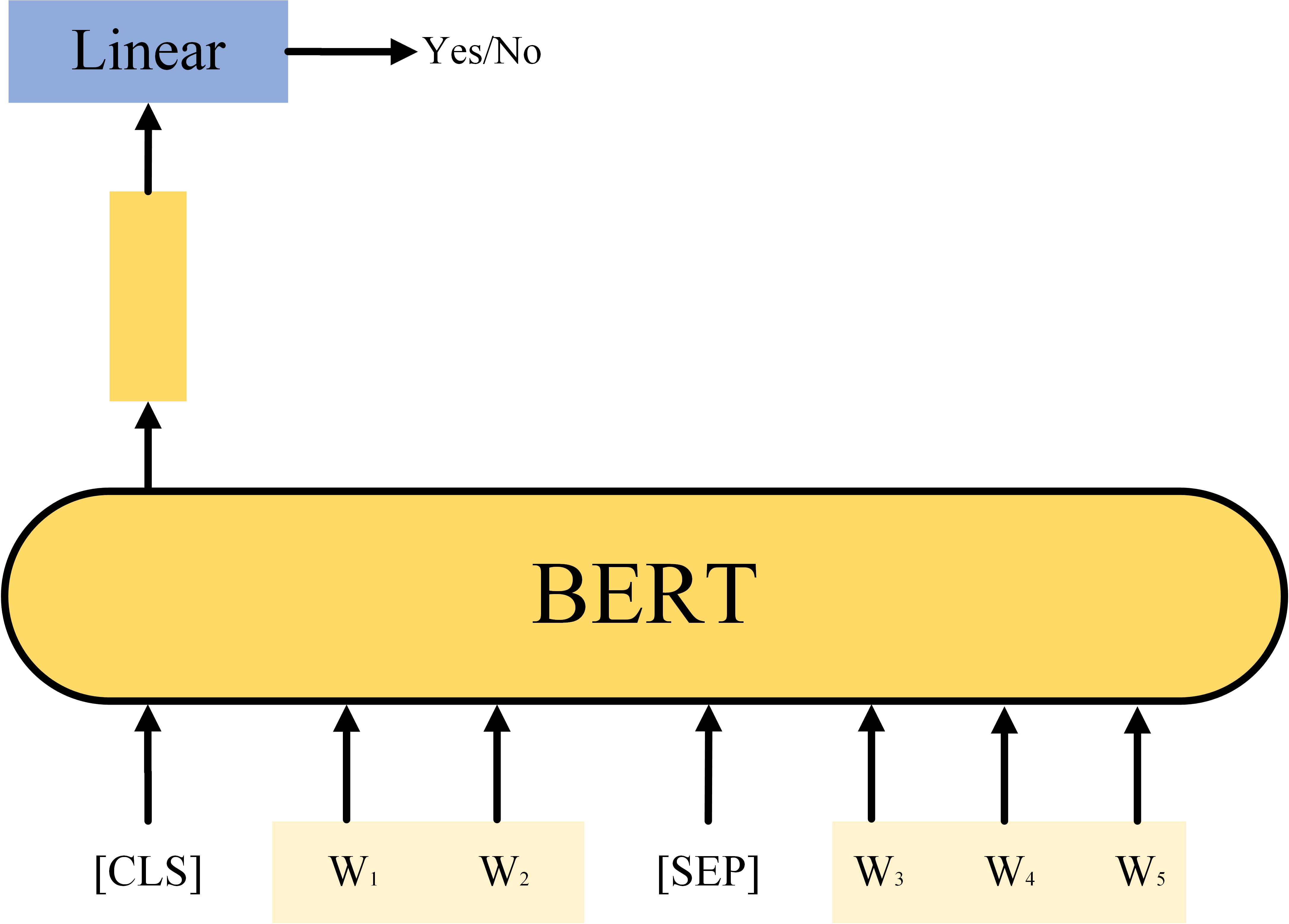
如图4是bert的第二种预训练方法下一个句子预测,给定两个句子,通过bert预测它们是否是连在一起的句子,[CLS]和[SEP]是在输入部分提到的两个特殊标记,注意在进行预测时只是用通过[CLS]生成的输出向量进行预测。
但是在RoBERTa中发现NSP好像不是那么有用,许多人认为这个任务可能过于简单,bert并没有从中学到很多东西。后来在ALBERT中使用了一种新的方法:Sentence Order Prediction(SOP),就是给定两个连在一起的句子,打乱它们的顺序,问bert这两个句子原来的顺序是什么。
Fine-Tune
General Language Understanding Evaluation(GLUE)是一个数据集集合,GLUE同样也有一个中文版本的数据集中文语言理解测评基准(CLUE)
不同种类的下游任务,对Bert的fine-tune方法不同,接下来介绍对于四种不同的下游任务时bert的fine-tune方法
Case1 Seq2Class
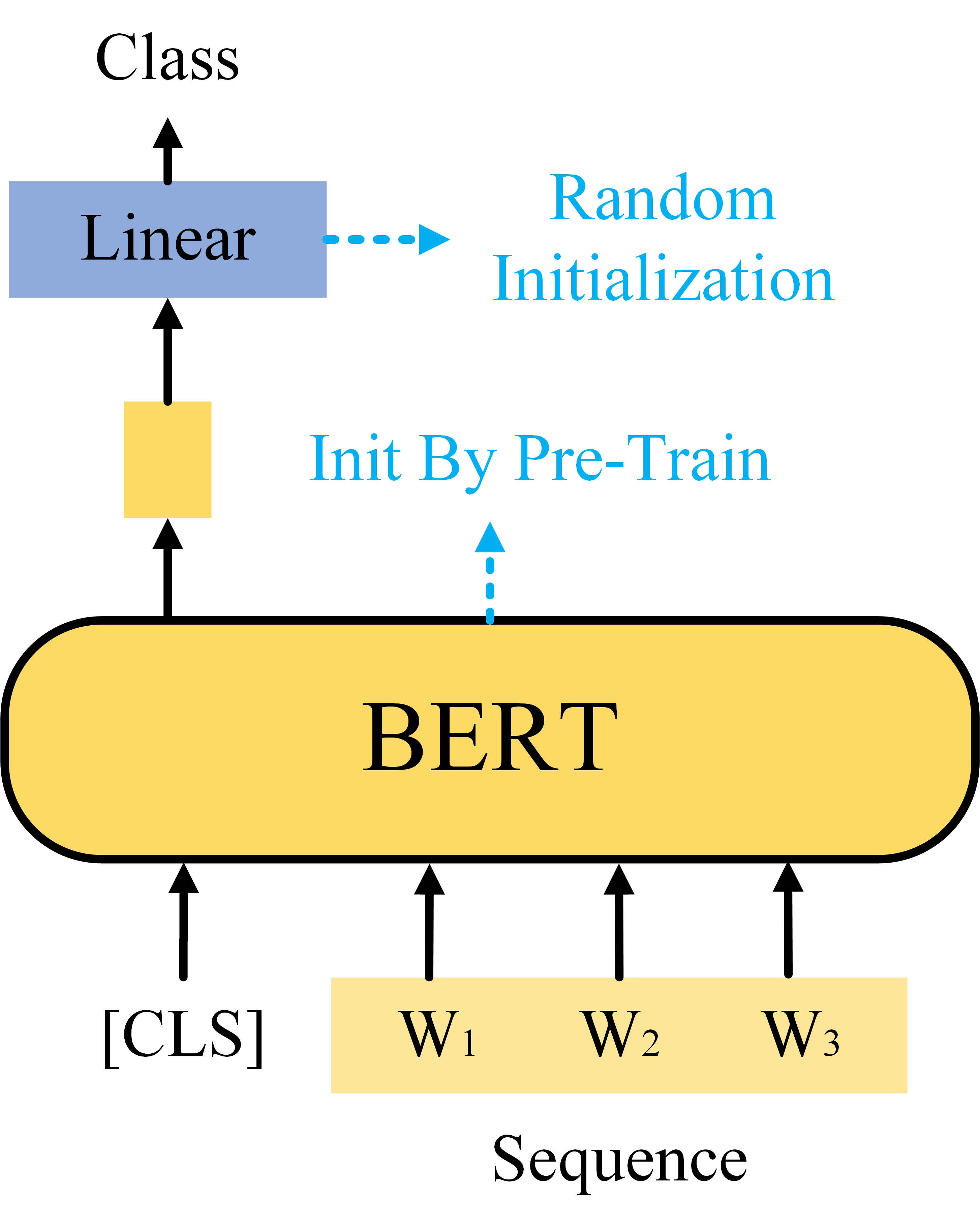
这里讲的是一类任务,即输入一个Sequence,输出是一个Class,例如情感分析:输入一段文本,用模型分析这个文本中表达的是正面情绪还是负面情绪。这类任务的Bert模型的参数是由预训练来进行初始化的,而它的linear layer的参数是随机初始化的,微调方法就是先将模型预训练好,之后使用带标注的数据集进行训练,训练时只使用由[CLS]生成的输出向量。
Case2 Seq2SameSeq
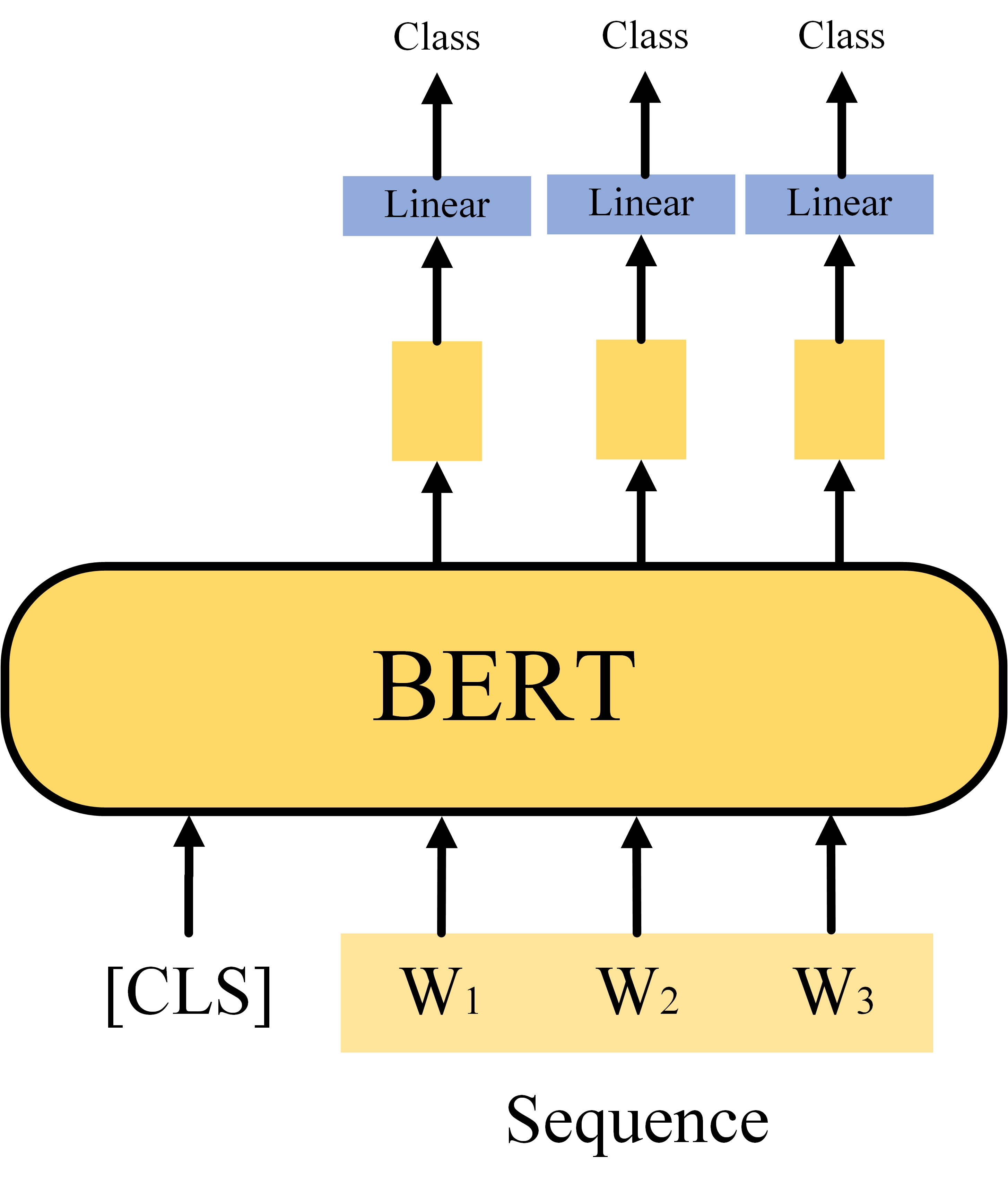
这里讲的这一类任务是输入是一个Sequence,输出是一个相同大小的Sequence,例如POS Tagging,即给定一个句子,模型预测出句子中每个单词的词性。同Case1一样,这里的Bert的参数通过预训练进行初始化,Linear Layer的参数则随机初始化,通过微调进行优化。
Case3 TwoSeq2Class
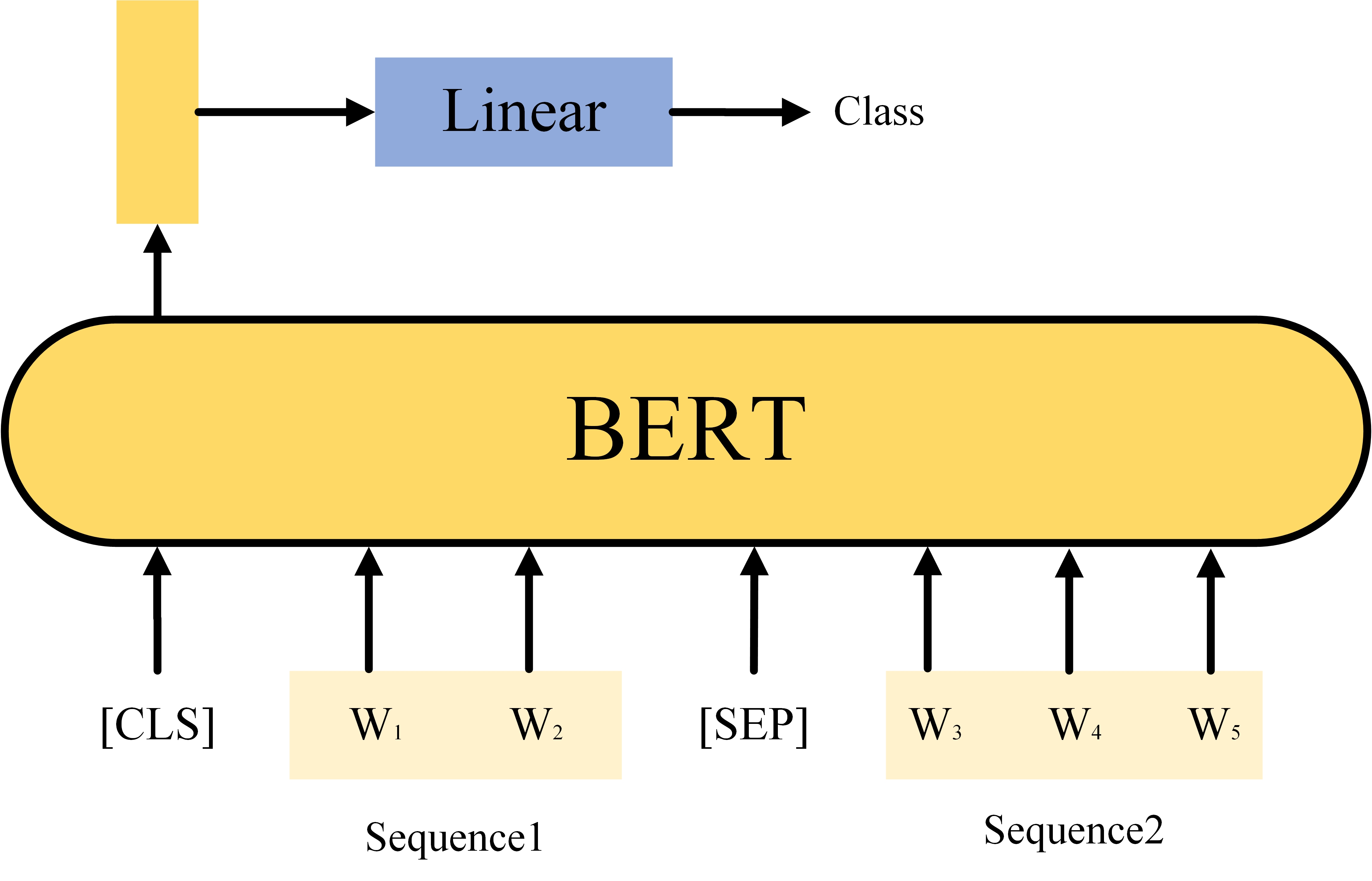
这个任务是输入两个Sequence,输出一个Class,参数初始化方法同上,典型任务是Natural Language Inference(NLI),就是给点一个前提和一个假说,判断这个假说是否符合前提。
Case4 Extraction-bassed Quetion Answering(QA)
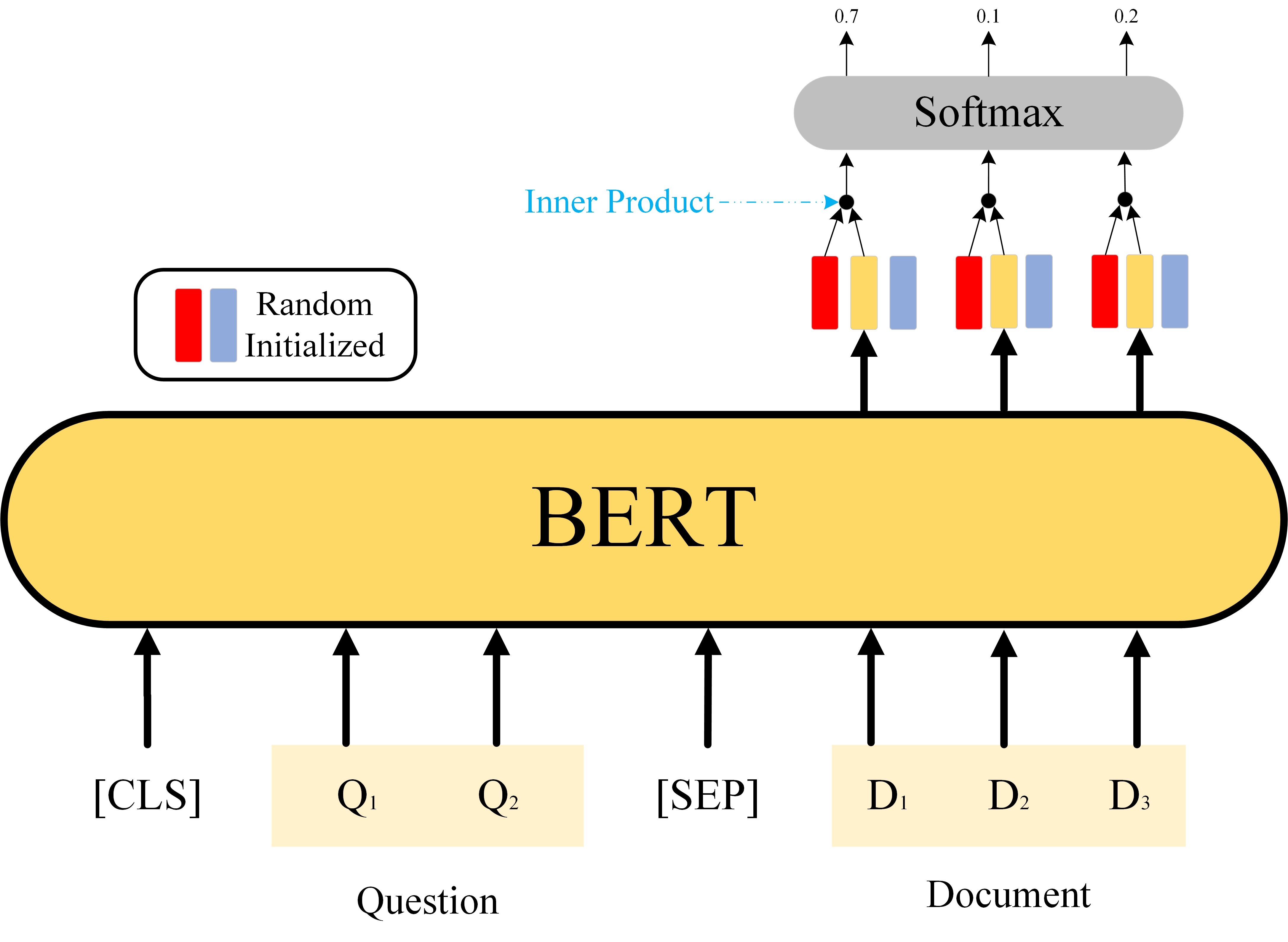
这个任务是一个QA系统,输入是一个问题和一篇文章,输出是两个正整数s和e,表示在文章中从第s个单词开始,到第e个单词结束是输入问题的答案。如图8,红色的向量用来预测正整数s,蓝紫色向量用来预测正整数e,这两个向量都是随机初始化,用红色向量对所有由Document中的Word产出的向量做点积后送入Softmax产出各自的概率,选取概率最大的那个位置作为正整数s,e的产生过程同s类似。
Case5 Seq2Seq
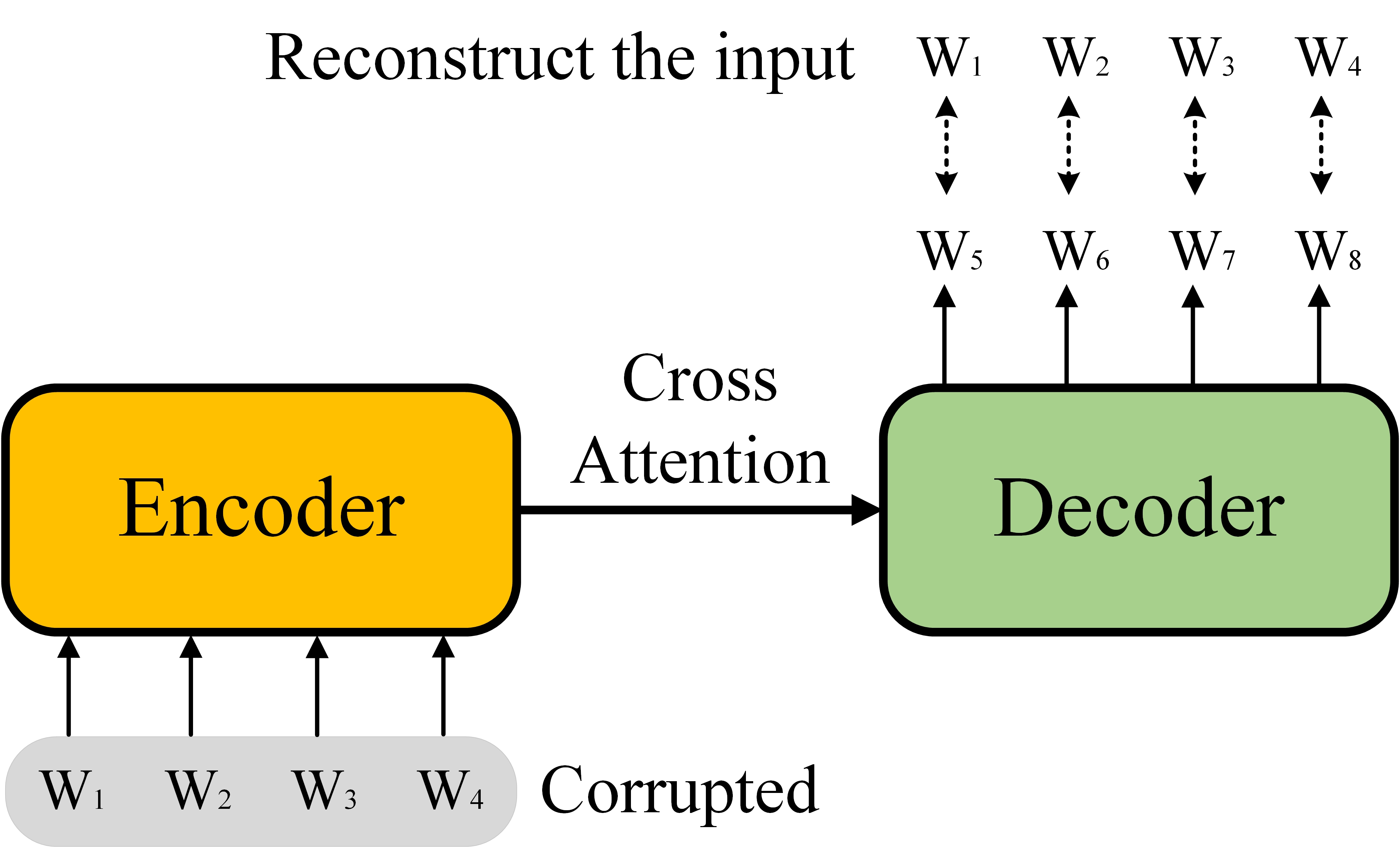
对于Seq2Seq Model,Bert通过将原始数据进行随机扰动,之后通过Transformer模型对原始Sequence进行重建来预训练Decoder。Google的Transfer Text-to-Text Transformer(T5)是一个训练在Colossal Clean Crawled Corpus(C4)数据集上的Seq2Seq Model。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号