并查集
并查集是一种树型数据结构,用于查找不相交的子集,并将他们合并在一起,简称并查集。并查集分为拆分、查找和合并三个操作。
并查集
查找
- pre数组记录所有结点的前驱结点,根节点的前驱结点是它自己
- find函数先找到x的根节点
int pre[1000];//1.
int find(int x)//2.
{
int r=x;
while ( pre[r] != r )//3.
r=pre[r];
return r ;
}
注释:
- 记录前驱结点
- 查找根节点
- 找到根节点 r
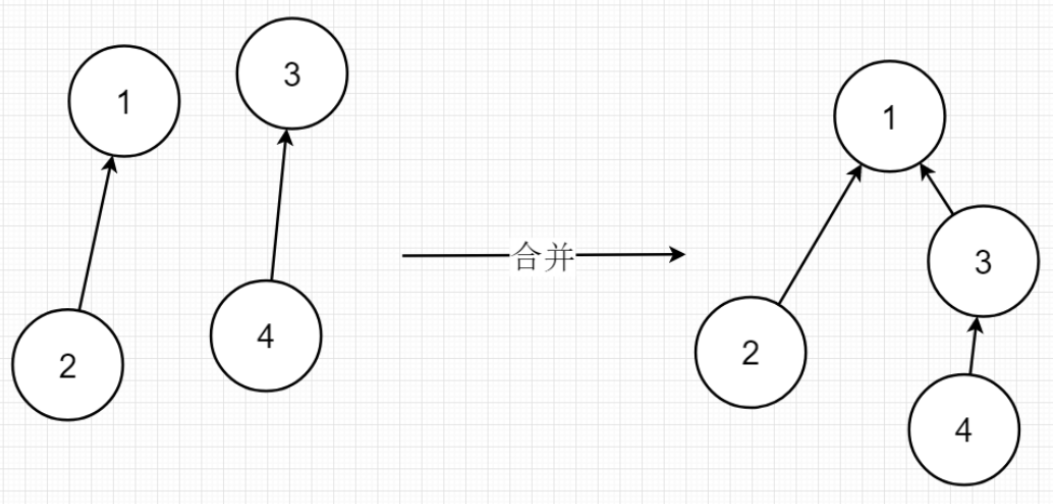
合并
-
join函数先找到两个变量的根节点
-
如果他们相同则说明两个变量在同一个集合中
-
如果不同则将其中一个根节点设置为另外一个根节点的前驱
-
void join(int x,int y)//1.
{
int fx=find(x),fy=find(y);
if(fx!=fy)
pre[fx ]=fy;
}
注释:
- 判断x y是否连通,如果已经连通,就不用管了 如果不连通,就把它们所在的连通分支合并起。
并查集的优化
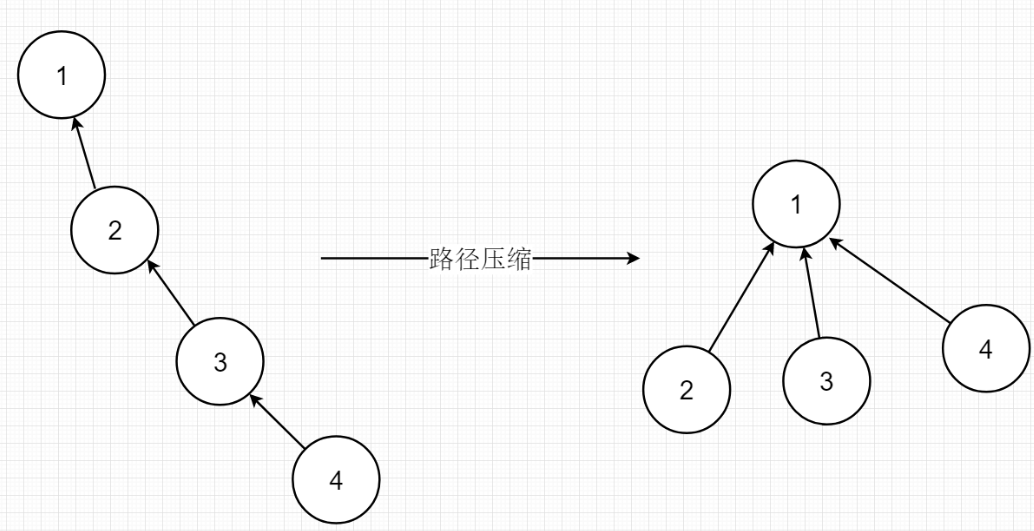
路径压缩
路径压缩是在寻找根结点的过程中,将子集中所有的点的前驱设置为根结点。
为什么要进行路径压缩呢?因为在并查集合并过程中,他有可能变成一个单链表,这样每次寻找根结点要遍历子集中所有的结点。进行路径压缩之后,每次寻找根结点只需访问他的父结点就可找到根结点。
优化后的find函数:
int pre[1000 ];
int find(int x)
{
int r=x;
while ( pre[r] != r )
r=pre[r];
int i=x , j ;
while( i != r )//1.
{
j = pre[ i ];//2.
pre[ i ]= r ;//3.
i=j;
}
return r ;
}
注释:
- 路径压缩
- 在改变上级之前用临时变量j记录下他的值
- 把上级改为根节点
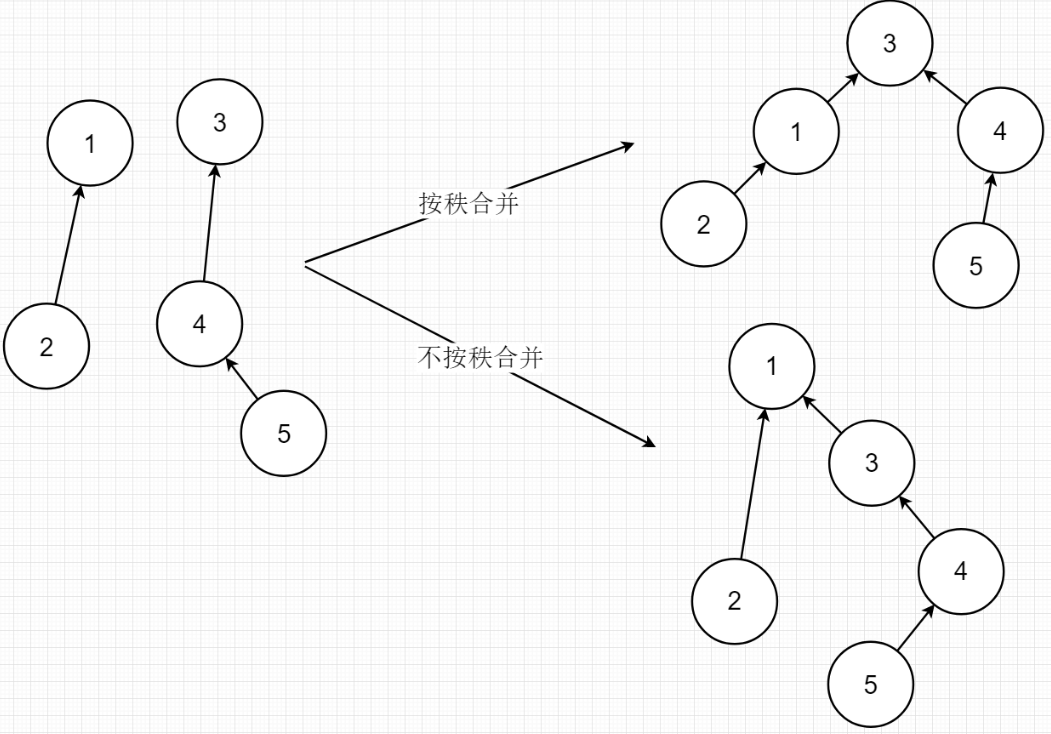
按秩(Rank)合并
按秩合并就是在合并过程中将元素所在深度小的集合合并到元素所在深度大的集合
为什么要按秩合并呢?因为如果将元素深度大的集合合并到小的集合,那么合并后的集合深度则等于较大的深度加一。如果将深度小的集合合并到深度大的集合,则合并后的集合深度不变。
优化后的join函数:
void join(int x, int y)
{
int fx=find(x),fy=find(y);
if(rank[fx]>rank[fy])//1.
pre[fy] = pre[fx];//2.
else
{
pre[fx] = fy;
if(rank[fx]==rank[fy])//3.
rank[fy]++;
}
}
注释:
- rank数组为当前结点秩的值
- 只需要比较根结点的rank值就够了
- 修改时也只用修改根结点的rank值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号