手写Word2vec算法实现
1. 语料下载:https://dumps.wikimedia.org/zhwiki/latest/zhwiki-latest-pages-articles.xml.bz2 【中文维基百科语料】
2. 语料处理
(1)提取数据集的文本
下载的数据集无法直接使用,需要提取出文本信息。
安装python库:
pip install numpy pip install scipy pip install gensim
python代码:
'''
Description: 提取中文语料
Author: zhangyh
Date: 2024-05-09 21:31:22
LastEditTime: 2024-05-09 22:10:16
LastEditors: zhangyh
'''
import logging
import os.path
import six
import sys
import warnings
warnings.filterwarnings(action='ignore', category=UserWarning, module='gensim')
from gensim.corpora import WikiCorpus
if __name__ == '__main__':
program = os.path.basename(sys.argv[0])
logger = logging.getLogger(program)
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
logging.root.setLevel(level=logging.INFO)
logger.info("running %s" % ' '.join(sys.argv))
# check and process input arguments
if len(sys.argv) != 3:
print("Using: python process_wiki.py enwiki.xxx.xml.bz2 wiki.en.text")
sys.exit(1)
inp, outp = sys.argv[1:3]
space = " "
i = 0
output = open(outp, 'w',encoding='utf-8')
wiki = WikiCorpus(inp, dictionary={})
for text in wiki.get_texts():
output.write(space.join(text) + "\n")
i=i+1
if (i%10000==0):
logger.info("Saved " + str(i) + " articles")
output.close()
logger.info("Finished Saved " + str(i) + " articles")
运行代码提取文本:
PS C:\Users\zhang\Desktop\nlp 自然语言处理\data> python .\process_wiki.py .\zhwiki-latest-pages-articles.xml.bz2 wiki_zh.text 2024-05-09 21:43:10,036: INFO: running .\process_wiki.py .\zhwiki-latest-pages-articles.xml.bz2 wiki_zh.text 2024-05-09 21:44:02,944: INFO: Saved 10000 articles 2024-05-09 21:44:51,875: INFO: Saved 20000 articles ... 2024-05-09 22:22:34,244: INFO: Saved 460000 articles 2024-05-09 22:23:33,323: INFO: Saved 470000 articles
提取后的文本(有繁体字):

(2)转繁体为简体
- opencc工具进行繁简转换,下载opencc:https://bintray.com/package/files/byvoid/opencc/OpenCC
- 执行命令进行转换
opencc -i wiki_zh.text -o wiki_sample_chinese.text -c "C:\Program Files\OpenCC\build\share\opencc\t2s.json"
- 转换后的简体文本如下:

(3)分词(使用jieba分词)
- 分词代码:
'''
Description:
Author: zhangyh
Date: 2024-05-10 22:48:45
LastEditTime: 2024-05-10 23:02:57
LastEditors: zhangyh
'''
#文章分词
import jieba
import jieba.analyse
import codecs
import os
import sys
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
# def cut_words(sentence):
# return " ".join(jieba.cut(sentence)).encode('utf-8')
f=codecs.open('data\\wiki_sample_chinese.text','r',encoding="utf8")
target = codecs.open("data\\wiki_word_cutted_result.text", 'w',encoding="utf8")
line_num=1
line = f.readline()
while line:
print('---- processing', line_num, 'article----------------')
line_seg = " ".join(jieba.cut(line))
target.writelines(line_seg)
line_num = line_num + 1
line = f.readline()
f.close()
target.close()
# exit()
# while line:
# curr = []
# for oneline in line:
# #print(oneline)
# curr.append(oneline)
# after_cut = map(cut_words, curr)
# target.writelines(after_cut)
# print ('saved',line_num,'articles')
# exit()
# line = f.readline1()
# f.close()
# target.close()
- 分词后的结果

3. 模型训练
(1)skip-gram模型
'''
Description:
Author: zhangyh
Date: 2024-05-12 21:51:03
LastEditTime: 2024-05-16 11:08:59
LastEditors: zhangyh
'''
import numpy as np
import pandas as pd
import pickle
from tqdm import tqdm
import os
import sys
import random
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
def load_stop_words(file = "作业-skipgram\\stopwords.txt"):
with open(file,"r",encoding = "utf-8") as f:
return f.read().split("\n")
def load_cutted_data(num_lines: int):
stop_words = load_stop_words()
data = []
# with open('wiki_word_cutted_result.text', mode='r', encoding='utf-8') as file:
with open('作业-skipgram\\wiki_word_cutted_result.text', mode='r', encoding='utf-8') as file:
for line in tqdm(file.readlines()[:num_lines]):
words_list = line.split()
words_list = [word for word in words_list if word not in stop_words]
data += words_list
data = list(set(data))
return data
def get_dict(data):
index_2_word = []
word_2_index = {}
for word in tqdm(data):
if word not in word_2_index:
index = len(index_2_word)
word_2_index[word] = index
index_2_word.append(word)
word_2_onehot = {}
word_size = len(word_2_index)
for word, index in tqdm(word_2_index.items()):
one_hot = np.zeros((1, word_size))
one_hot[0, index] = 1
word_2_onehot[word] = one_hot
return word_2_index, index_2_word, word_2_onehot
def softmax(x):
ex = np.exp(x)
return ex/np.sum(ex,axis = 1,keepdims = True)
# 负采样
# def negative_sampling(word_2_index, word_count, num_negative_samples):
# word_probs = [word_count[word]**0.75 for word in word_2_index]
# word_probs = np.array(word_probs) / sum(word_probs)
# neg_samples = np.random.choice(len(word_2_index), size=num_negative_samples, replace=True, p=word_probs)
# return neg_samples
if __name__ == "__main__":
batch_size = 562 # 定义批量大小
data = load_cutted_data(5)
word_2_index, index_2_word, word_2_onehot = get_dict(data)
word_size = len(word_2_index)
embedding_num = 100
lr = 0.01
epochs = 200
n_gram = 3
# num_negative_samples = 5
# 计算词频
# word_count = dict.fromkeys(word_2_index, 0)
# for word in data:
# word_count[word] += 1
batches = [data[j:j+batch_size] for j in range(0, len(data), batch_size)]
w1 = np.random.normal(-1,1,size = (word_size,embedding_num))
w2 = np.random.normal(-1,1,size = (embedding_num,word_size))
for i in range(epochs):
print(f'-------- epoch {i + 1} --------')
for batch in tqdm(batches):
for i in tqdm(range(len(batch))):
now_word = batch[i]
now_word_onehot = word_2_onehot[now_word]
other_words = batch[max(0, i - n_gram): i] + batch[i + 1: min(len(batch), i + n_gram + 1)]
for other_word in other_words:
other_word_onehot = word_2_onehot[other_word]
hidden = now_word_onehot @ w1
p = hidden @ w2
pre = softmax(p)
# A @ B = C
# delta_C = G
# delta_A = G @ B.T
# delta_B = A.T @ G
G2 = pre - other_word_onehot
delta_w2 = hidden.T @ G2
G1 = G2 @ w2.T
delta_w1 = now_word_onehot.T @ G1
w1 -= lr * delta_w1
w2 -= lr * delta_w2
with open("作业-skipgram\\word2vec_skipgram.pkl","wb") as f:
# with open("word2vec_skipgram.pkl","wb") as f:
pickle.dump([w1, word_2_index, index_2_word, w2], f)
(2)CBOW 模型
'''
Description:
Author: zhangyh
Date: 2024-05-13 20:47:57
LastEditTime: 2024-05-16 09:21:40
LastEditors: zhangyh
'''
import numpy as np
import pandas as pd
import pickle
from tqdm import tqdm
import os
import sys
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
def load_stop_words(file = "stopwords.txt"):
with open(file,"r",encoding = "utf-8") as f:
return f.read().split("\n")
def load_cutted_data(num_lines: int):
stop_words = load_stop_words()
data = []
with open('wiki_word_cutted_result.text', mode='r', encoding='utf-8') as file:
# with open('作业-CBOW\\wiki_word_cutted_result.text', mode='r', encoding='utf-8') as file:
for line in tqdm(file.readlines()[:num_lines]):
words_list = line.split()
words_list = [word for word in words_list if word not in stop_words]
data += words_list
data = list(set(data))
return data
def get_dict(data):
index_2_word = []
word_2_index = {}
for word in tqdm(data):
if word not in word_2_index:
index = len(index_2_word)
word_2_index[word] = index
index_2_word.append(word)
word_2_onehot = {}
word_size = len(word_2_index)
for word, index in tqdm(word_2_index.items()):
one_hot = np.zeros((1, word_size))
one_hot[0, index] = 1
word_2_onehot[word] = one_hot
return word_2_index, index_2_word, word_2_onehot
def softmax(x):
ex = np.exp(x)
return ex/np.sum(ex,axis = 1,keepdims = True)
if __name__ == "__main__":
batch_size = 562
data = load_cutted_data(5)
word_2_index, index_2_word, word_2_onehot = get_dict(data)
word_size = len(word_2_index)
embedding_num = 100
lr = 0.01
epochs = 200
context_window = 3
batches = [data[j:j+batch_size] for j in range(0, len(data), batch_size)]
w1 = np.random.normal(-1,1,size = (word_size,embedding_num))
w2 = np.random.normal(-1,1,size = (embedding_num,word_size))
for i in range(epochs):
print(f'-------- epoch {i + 1} --------')
for batch in tqdm(batches):
for i in tqdm(range(len(batch))):
target_word = batch[i]
context_words = batch[max(0, i - context_window): i] + batch[i + 1: min(len(batch), i + context_window + 1)]
# 获取上下文词的词向量的平均值作为输入
context_vectors = np.mean([word_2_onehot[word] for word in context_words], axis=0)
# 计算输出层
hidden = context_vectors @ w1
p = hidden @ w2
pre = softmax(p)
# 交叉熵损失函数
# loss = -np.log(pre[word_2_index[target_word], 0])
# 反向传播更新参数
G2 = pre - word_2_onehot[target_word]
delta_w2 = hidden.T @ G2
G1 = G2 @ w2.T
delta_w1 = context_vectors.T @ G1
w1 -= lr * delta_w1
w2 -= lr * delta_w2
# with open("作业-CBOW\\word2vec_cbow.pkl","wb") as f:
with open("word2vec_cbow.pkl","wb") as f:
pickle.dump([w1, word_2_index, index_2_word, w2], f)
4. 训练结果
(1)余弦相似度计算
'''
Description:
Author: zhangyh
Date: 2024-05-13 20:12:56
LastEditTime: 2024-05-16 21:16:19
LastEditors: zhangyh
'''
import pickle
import numpy as np
# w1, voc_index, index_voc, w2 = pickle.load(open('word2vec_cbow.pkl','rb'))
w1, voc_index, index_voc, w2 = pickle.load(open('作业-CBOW\\word2vec_cbow.pkl','rb'))
def word_voc(word):
return w1[voc_index[word]]
def voc_sim(word, top_n):
v_w1 = word_voc(word)
word_sim = {}
for i in range(len(voc_index)):
v_w2 = w1[i]
theta_sum = np.dot(v_w1, v_w2)
theta_den = np.linalg.norm(v_w1) * np.linalg.norm(v_w2)
theta = theta_sum / theta_den
word = index_voc[i]
word_sim[word] = theta
words_sorted = sorted(word_sim.items(), key=lambda kv: kv[1], reverse=True)
for word, sim in words_sorted[:top_n]:
# print(f'word: {word}, similiar: {sim}, vector: {w1[voc_index[word]]}')
print(f'word: {word}, similiar: {sim}')
voc_sim('学院', 20)
(2)可视化展示
'''
Description:
Author: zhangyh
Date: 2024-05-16 21:41:33
LastEditTime: 2024-05-17 23:50:07
LastEditors: zhangyh
'''
import numpy as np
import pandas as pd
import pickle
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = ['Microsoft YaHei', 'SimHei', 'sans-serif']
# Load trained word embeddings
with open("word2vec_cbow.pkl", "rb") as f:
w1, word_2_index, index_2_word, w2 = pickle.load(f)
# Select specific words for visualization
visual_words = ['研究', '电脑', '雅典', '数学', '数学家', '学院', '函数', '定理', '实数', '复数']
# Get the word vectors corresponding to the selected words
subset_vectors = np.array([w1[word_2_index[word]] for word in visual_words])
# Perform PCA for dimensionality reduction
pca = PCA(n_components=2)
reduced_vectors = pca.fit_transform(subset_vectors)
# Visualization
plt.figure(figsize=(10, 8))
plt.scatter(reduced_vectors[:, 0], reduced_vectors[:, 1], marker='o')
for i, word in enumerate(visual_words):
plt.annotate(word, xy=(reduced_vectors[i, 0], reduced_vectors[i, 1]), xytext=(5, 2),
textcoords='offset points', ha='right', va='bottom')
plt.title('Word Embeddings Visualization')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.grid(True)
plt.show()
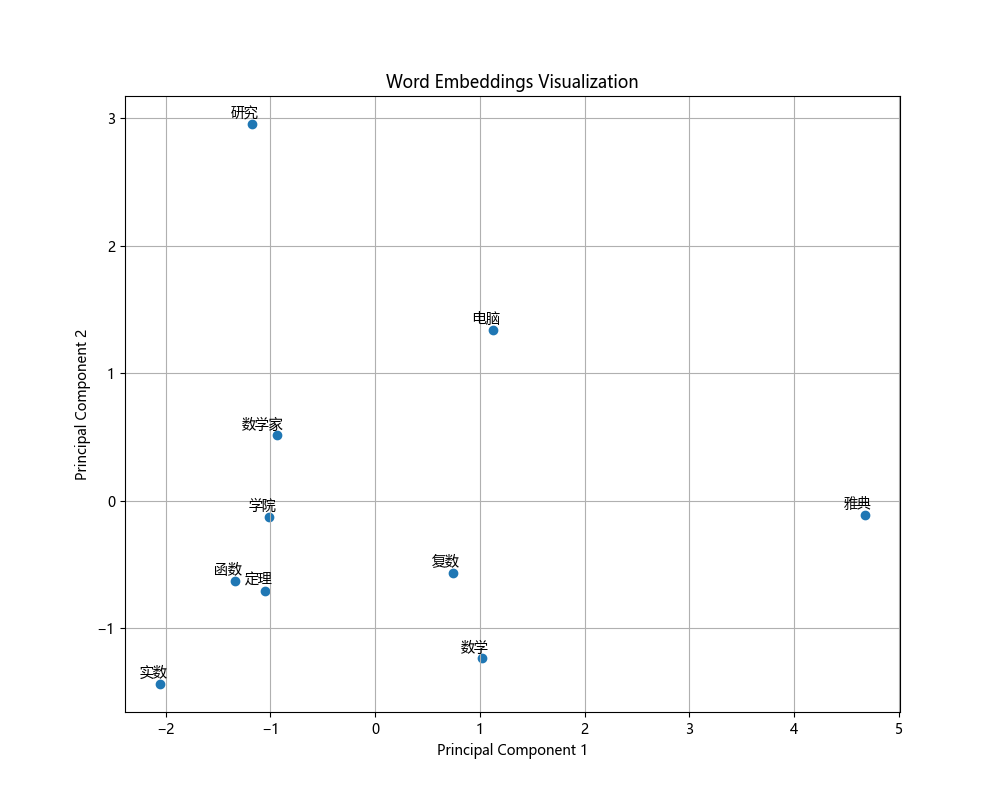
(3)类比实验探索(例如:王子 - 男 + 女 = 公主)
'''
Description:
Author: zhangyh
Date: 2024-05-16 23:13:21
LastEditTime: 2024-05-19 11:51:53
LastEditors: zhangyh
'''
import numpy as np
import pickle
from sklearn.metrics.pairwise import cosine_similarity
# 加载训练得到的词向量
with open("word2vec_cbow.pkl", "rb") as f:
w1, word_2_index, index_2_word, w2 = pickle.load(f)
# 计算类比关系
v_prince = w1[word_2_index["王子"]]
v_man = w1[word_2_index["男"]]
v_woman = w1[word_2_index["女"]]
v_princess = v_prince - v_man + v_woman
# 找出最相近的词向量
similarities = cosine_similarity(v_princess.reshape(1, -1), w1)
most_similar_index = np.argmax(similarities)
most_similar_word = index_2_word[most_similar_index]
print("结果:", most_similar_word)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号