
论文解读-《GraphEdit Large Language Models for Graph Structure Learning》
1. 论文介绍
论文题目:GraphEdit: Large Language Models for Graph Structure Learning
论文领域:图结构学习,LLM
论文地址:https://arxiv.org/abs/2402.15183
论文代码:https://github.com/HKUDS/GraphEdit
论文背景:

2. 论文摘要
图结构学习(GSL)专注于通过生成新颖的图结构,捕捉图结构数据中节点之间的内在依赖关系和交互。图神经网络(GNN)作为有前景的 GSL 解决方案出现,利用递归消息传递编码节点间的相互依赖关系。然而,许多现有的 GSL 方法高度依赖显式图结构信息作为监督信号,因此容易受到数据噪声和稀疏性等挑战。在本研究中,我们提出了 GraphEdit 方法,利用大型语言模型(LLM)学习图结构化数据中的复杂节点关系。通过对图结构进行指令调优,增强大型语言模型的推理能力,我们旨在克服显式图结构信息的局限,提升图结构学习的可靠性。我们的方法不仅有效去噪声连接,还从全局视角识别节点间的依赖关系,全面理解图结构。我们在多个基准数据集上进行了大量实验,以展示 GraphEdit 在不同环境中的有效性和鲁棒性。
3. 相关介绍
传统的图学习,仅仅依靠显式的图结构作为监督信号,可能因为噪声和数据缺失等问题,而产生不准确的问题,需要有更稳健的图结构学习框架,以适应图结构化数据。
图表示学习
重点捕捉图中节点的有意义且意义丰富的表示,从而能够分析和建模图数据中复杂的关系和模式。
4. 核心算法
整个算法的框架为:基于LLM的指令微调,基于LLM的边预测,LLM增强的结构精炼
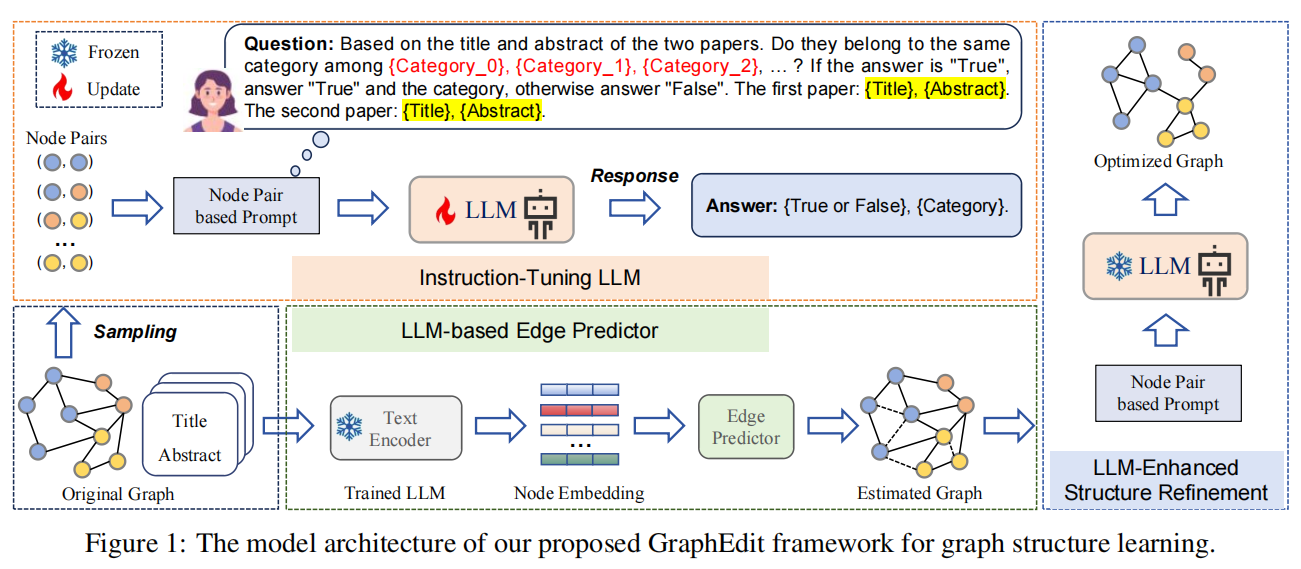
4.1 指令调优LLM(Instruction-Tuning LLM)
在依赖图结构的节点分类任务中,最优情况是最大化同类内的连接,同时最小化类间连接。基于这一原则,我们的方法旨在利用大型语言模型(LLM)的知识,考虑节点间潜在的依赖关系,同时考虑与各个节点相关的文本语义。
提示创建阶段
- 第一个目标是评估节点对指标的一致性。使语言模型能够准确掌握所需的图结构
- 第二个目标是基于标签的一致性。涉及确定这些节点所需要的具体类别。
采用随机抽样技术从训练数据$N_{train}$中选择 节点对 $(n_i, n_j)$,用于调优LLM的节点对是从训练集中随机抽取的。
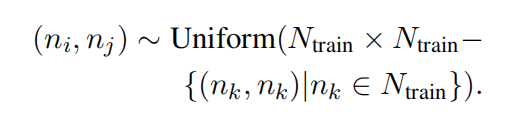
4.2 基于LLM的边预测器(LLM-based Edge Predictor)
引入一个轻量级边预测器,帮助LLM在图中节点中选择候选边g。为了确保语义一致,利用每个节点从训练出来的LLM中推导的表示。表示为:
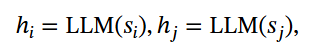
基于节点标签,$c_n$的构建为构造训练集标签方式为
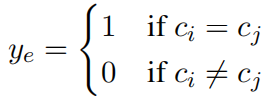
将每个节点对中两个节点的表示串联起来,将连接后的表示输入到一个预测层,从而获得该边存在的概率。使用交叉熵作为损失函数。
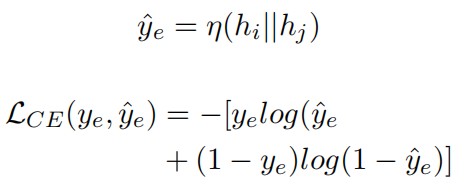
4.3 LLM增强结构精炼(LLM-enhanced Structure Refinement)
根据每一个节点的存在可能性估计,识别出top-K条候选边,连同图的原始边,随后通过提示由LLM进行评估。

由LLM利用这些信息决定哪些边应被纳入最终图结构。
图结构细化过程可以总结为:

更新后的邻接矩阵,是通过将边预测器的输出与原始邻接矩阵结合得到A的。融合过程将边预测器的预测结构整合到现有的图结构中。
精细后的邻接矩阵A代表了LLM的知情选择,涵盖了边的包含和移除。
5. 实验设置
5.1 基础实验
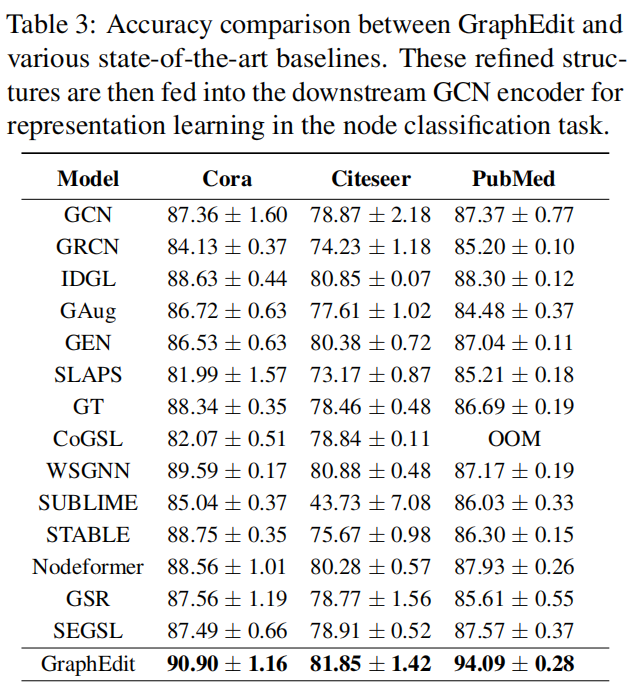
三个代表性数据集:Cora、PubMed 和 Citeseer。这些数据集被广泛认可为图学习任务的基准。
为了全面验证我们的 GraphEdit 模型的有效性,我们将其与 13 个基于训练策略分为三组的图结构学习基线进行了比较。
预训练模型(Pre-Training Models):训练过程包含两个阶段:预训练增强图结构,然后利用该精炼结构训练GNN等下游任务
Iter-Training 模型: 根据优化的GNN生成的预测和表示,自适应得学习图结构。然后学到的结构用于后续迭代中训练新的GNN模型。
共同训练模型(Co-Training Models):负责生成图结构的神经网络与GNN并行进行协同优化。协同优化确保了学习过程的更加高效和集成。
在选择候选边时,我们尝试了从 1 到 5 的不同 top-k 值。这一探索使我们能够研究变换选定边数量的影响,并确定最佳设置。为了确保结果的稳健性,我们重复所有实验 10 次,并计算结果的平均值和标准差。为了促进公平比较,我们采用网格搜索策略调整各种基线参数。
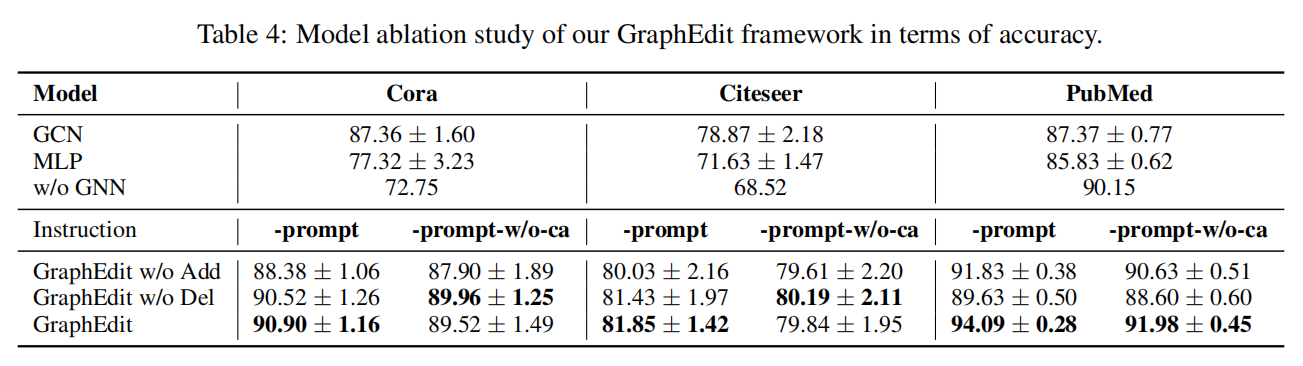
5.2 消融实验
“-prompt”符号指的是利用两阶段指令调优范式来微调 LLM。这些指令包括预测边的存在以及特定连接节点类别的任务;
“-prompt-w/o-ca” 表示通过简化指令对 LLM 进行微调,这些指令不涉及预测特定节点类别;
6. 总结
通过微调技术来构建一个专门学习图结构的LLM,其实就是将两个节点输入,以判断两个节点之间的关系为标签。
7. 个人感悟
关于如何微调一个LLM的,在这方面的技术和经验了解的比较少,以后再回头来看看这个论文。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号