

论文解读-《Representation Learning on Graphs with Jumping Knowledge Networks》
1. 论文介绍
论文题目:Representation Learning on Graphs with Jumping Knowledge Networks
论文领域:图神经网络
论文发表:ICML 2018
论文背景:

2. 论文摘要
最近用于图的表示学习的深度学习方法遵循邻域聚合过程。我们分析了这些模型的一些重要性质,并提出了克服这些性质的策略。特别是,节点表示从中提取的“相邻”节点的范围强烈依赖于图结构,类似于随机游动的扩展。为了适应局部邻域属性和任务,我们探索了一种架构——跳跃知识(JK)网络——该架构灵活地为每个节点利用不同的邻域范围,以实现更高的结构感知表示。在社会、生物信息学和引文网络的许多实验中,我们证明我们的模型实现了最先进的性能。此外,将JK框架与图卷积网络、图SAGE和图注意网络等模型相结合,可以一致地提高这些模型的性能。
3. 相关工作
图的节点的表征学习的目的是从节点和其邻居节点中提取高阶段的特征。
对于图卷积网络GCN有一个观察,只有2层的GCN是表现最好的,当层数增加时,反而表现更差。借用计算机视觉中的残差连接,给GCN加入残差连接后,也没法跟2层GCN的表现优秀。针对这个现象,作者研究了邻域聚合方法的属性和局限性,分析后,提出了一种新的不同于现存方法的结构,能够自适应学习,可感知结构的特征学习方法。
本文定义:一个节点的影响分布:对一个节点来说任何在该节点特征表示范围内的其他节点的集合。
针对2层GCN表现比多层表现更好的直观原因是:2阶的随机游走影响会集中在本地邻域,而高阶的特征包含的信息可能会被均值化而被平滑掉。
不同的子图结构,随机游走方法在子图走相同的步骤后,变成的状态也是很大的不同。如在core稠密区域的a,在tree边缘区域出发的为b,在边缘出发的5步的c。

3.1 邻域聚合技术
一个典型的邻域整合技术通常可以表示为
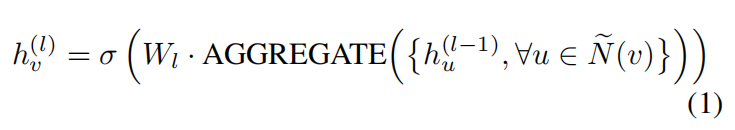
带skip连接的邻域整合技术,其中有连接combine操作
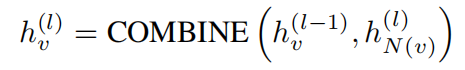
combine是非常关键的操作,可以帮助不同层跳过连接联系在一起。
带方向偏置的邻域整合技术
过去的对邻居的采样是平均的,可以针对重要的邻居进行更大权重的关注。这个可视为带方向偏置的邻域整合技术,因为本节点受到不同节点的影响不一样。
3.2 影响分布和随机游走
影响分布值:定义节点x在不同层之间的特征向量,对于x和y节点之间的关系比较。
节点 x 受节点 y 影响的分数 I(x, y),定义为雅可比矩阵(Jacobian matrix)对应元素绝对值的和。
雅可比矩阵衡量:节点 y 的输入特征变化,对节点 x 最后一层隐藏特征的影响幅度。
对矩阵所有元素取绝对值再求和,得到 x 与 y 间的 “影响强度” 量化值 I(x, y)。
这套定义把图节点间的 “影响关系”,通过导数(雅可比矩阵)量化,再归一化得到分布。能用于分析:哪些节点对目标节点 x 影响最大(找关键 “影响源”);节点特征传递、模型决策过程中,图结构如何通过特征交互产生作用。就是用数学工具(雅可比矩阵 + 归一化),给图节点间的 “影响” 做了可计算、可解释的定义,是图神经网络可解释性、影响分析的基础方法之一 。

定义2,随机游走的分布定义为


随机游走分布的一个重要特性是,如果图形是非二分的,则随着t的增加和收敛到极限分布,它会变得更加分散。收敛速率取决于子图的结构,并且可以由随机游走的过渡矩阵的频谱间隙(或传递性)来限制。
不同的聚合模型的影响分布的范围,可以视为是视野域可以捕获到的信息。那么久可以在GCN和随机游走之间建立联系。可以有下面的理论


根据对比实验
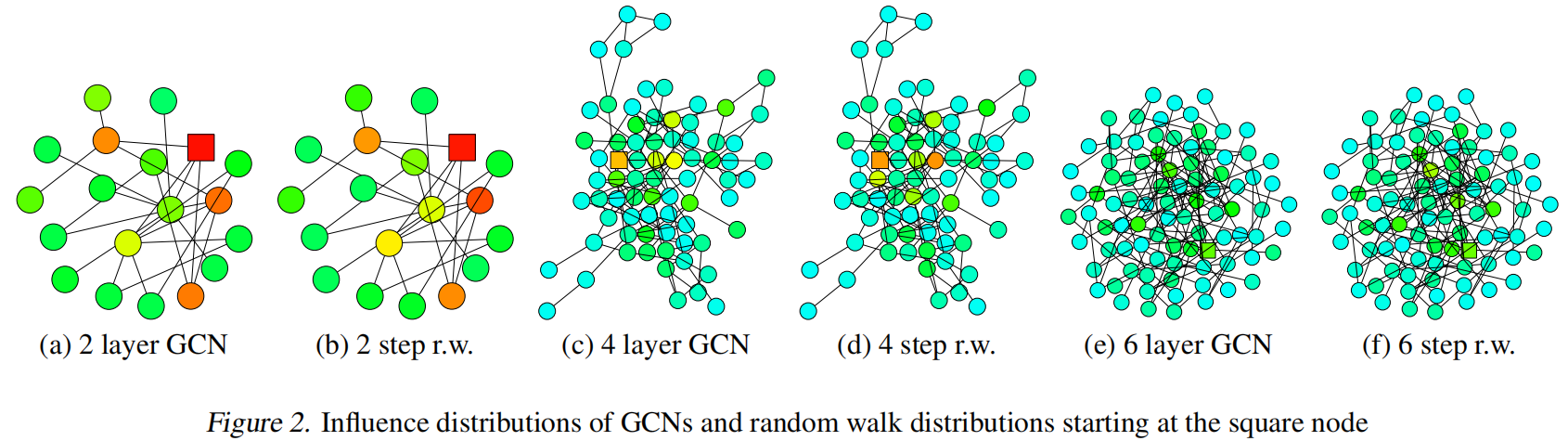
对比了GCN和随机游走两个算法,在以正方形为起点的开始的影响分布,颜色更深代表影响越大。可以看出当深度加大时,过多的平均操作会让覆盖到的所有节点均值化。
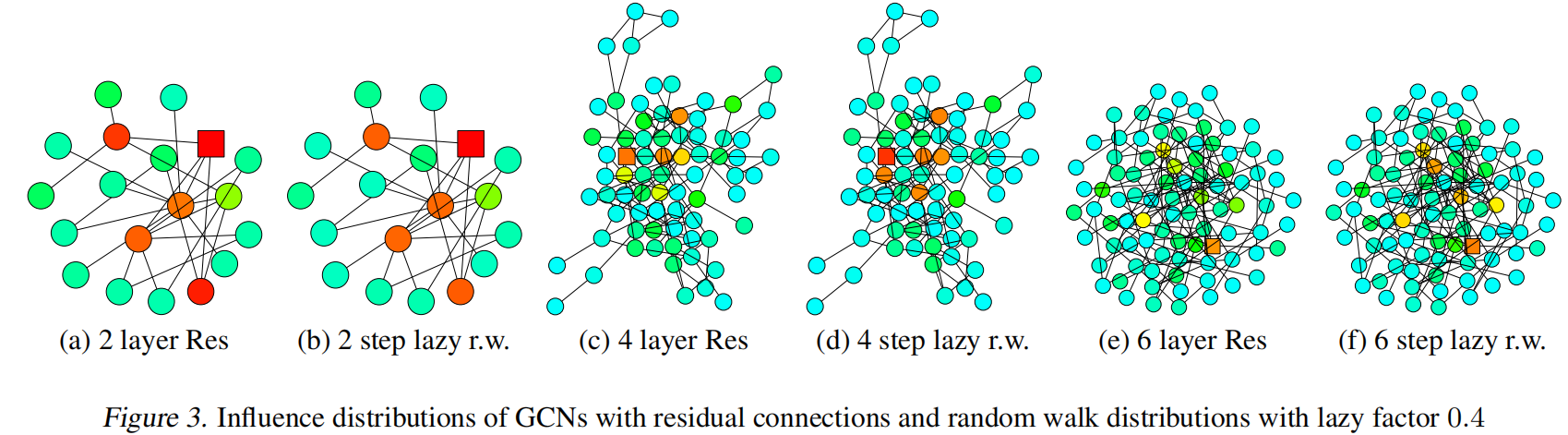
带残差的连接,更倾向于专注于本地的更有用的结构信息。
总结上面的观察,大的影响范围可能会导致过多的平均操作而使得效果不好,并且小的影响范围也可能会使得邻域聚合不稳定或者聚合信息不充足。
4. JKN模型(Jumping Knowledge Network)
本文提出了两个改进,跳跃连接和子串选择自适应聚合方法。

根据上面的网络架构图,每一层都比邻居层多一跳的聚合操作,且在最后一层,选择性地连接所有中间表达层。
聚合方式:
1,串联组合 Concatenation,最直接的方式。后面一般接着一个线性转换,如果线性转换的权重是节点之间共享的那方法就不是节点自适应。这个方法一般适用于小图或者有规律结构的图。
2,最大池化操作max-pooling,找到所有特征层中最有信息量的层。该方法是自适应的,不需要引入其他参数来学习。
3,基于LSTM的注意力机制,LSTM-attention是节点自适应因为每一个节点的注意力权重都不一样,一般适用于大图复杂图不适用于小图可能会过拟合。
层聚合函数设计的关键思想是在查看所有层上学习到的特征后,确定节点的子图特征在不同范围内的重要性,而不是对所有节点优化和固定相同的权重。
逐层最大池化隐式地自适应地学习不同节点的影响局部性。分层注意力的证明也类似。
将这一结果与其他聚合机制的影响分布进行对比,我们看到 JK 网络在邻域范围的节点自适应性上确实存在差异。

演示了6层JKNet在不同子图结构上的表现
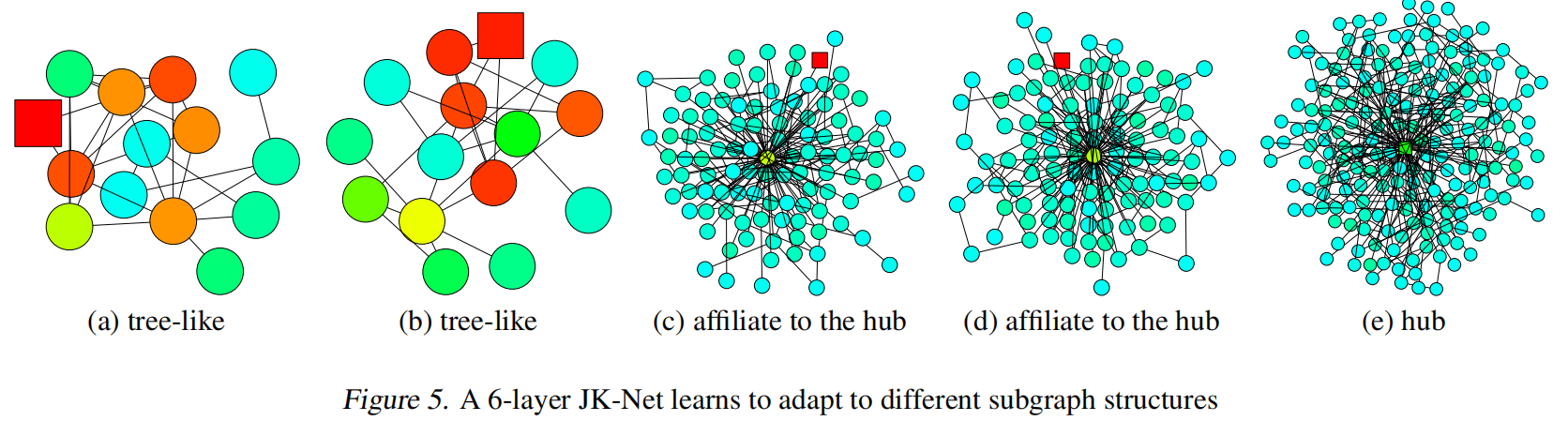
结构的讨论
该算法的图结构类似计算机视觉中的算法DenseNet算法。
5. 实验设置
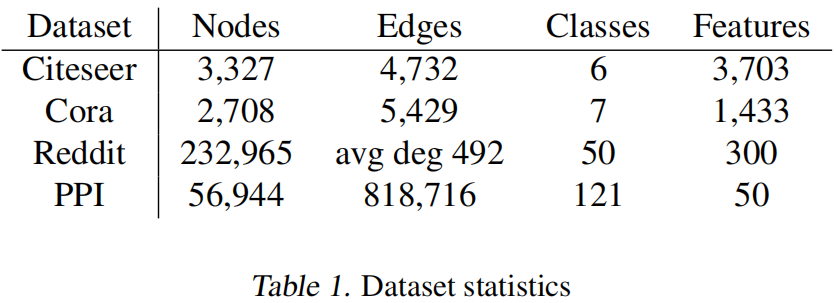
在四个基准数据集上,索引网络数据集Citeseer,Cora,在线社区关联Reddit,蛋白质交互网络PPI。
在Citeseer,Cora和Reddit上是transductive的方式,在PPI数据上是inductive的方式。
对比的方法有三个,GCN,GraphSAGE和GAT三种方法,在transductive的数据集上的表现

在PPI数据集上的表现

6. 总结
通过多层网络聚合的方式,加上自适应的选择多个层的特征,JKnet提高了对图的特征提取效果,更适合于有着多样子图结构的图数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号