

论文解读-《Classic GNNs are Strong Baselines assessing GNNs for Node Classification》
1. 论文介绍
论文题目:Classic GNNs are Strong Baselines: Reassessing GNNs for Node Classification
论文领域:图神经网络
论文发表:NIPS 2024
论文背景:

2. 论文摘要
图变换器(GT)最近成为传统消息传递图神经网络(GNN)的流行替代品,因为它们在理论上具有优越的表达能力,并且在标准节点分类基准测试上报告了令人印象深刻的性能,通常显著优于GNN。在本文中,我们进行了彻底的实证分析,以重新评估三个经典GNN模型(GCN、GAT和GraphSAGE)对GT的性能。我们的发现表明,由于GNN中的次优超参数配置,以前报道的GTs的优越性可能被夸大了。值得注意的是,通过轻微的超参数调整,这些经典GNN模型实现了最先进的性能,在所检查的18个不同数据集中的17个中匹配甚至超过最近的GT。此外,我们进行了详细的消融实验的研究,以研究各种GNN配置(如归一化、丢失、剩余连接和网络深度)对节点分类性能的影响。我们的研究旨在促进图机器学习领域更高标准的经验严谨性,鼓励更准确地比较和评估模型能力。
3. 论文介绍
在最近的一些研究表明,Graph Transformer在图分类问题上取得了最好的效果,源自关注全局特征的特点。但对于一些只需要关注局部特征,而不重视全局特征的来说,传统的GNN仍然有其优势。
这就有了本文的核心问题:以信息传递为基础的GNN在节点分类上的潜力是否被低估了?
本文选择了三个经典的GNN模型,GCN,GAT 和 GraphSAGE ,在不同的数据集上进行实验,探讨训练的关键超参数的影响,包括归一化,droput,残差连接,和网络深度等的影响。
根据实验,发现了以下两个关键点
- 1,在正确恰当的超参数训练下,经典GNN可以在具有多达数百万个节点的同配图和异配图的节点分类中实现极具竞争力的性能,经典GNN的表现优于最先进的GT(Graph Transformer),在18个数据集中的17个数据集上排名第一 。之前声称的GT优于经典GNN是夸大了,可能是超参数配置非最优导致的
- 2,消融实验发现GNN的超参数技术的重要性;(1)归一化对大型数据是至关重要的;(2)dropout对所有方法都有促进作用;(3)残差连接可以提高性能,特别是异构图上;(4)在异构图上,更深的GNN通常表现更好
3.1 节点分类的经典GNN
以消息传递为基础的GNN,每一层的节点的特征向量,可以表示为
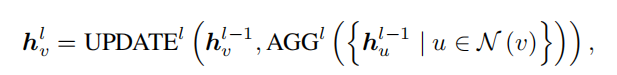
核心思想就是捕获邻居节点N,从中提取特征,聚合到本节点中,然后选择特定的更新方式来更新本节点的特征向量。
对于标准的GCN,可以表示为
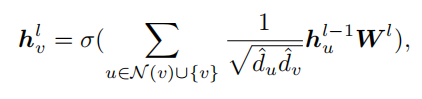
对于GraphSAGE,表示为
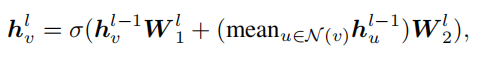
对于GAT(Graph Attention Networks),利用Masked的自我注意力来进行分配权重
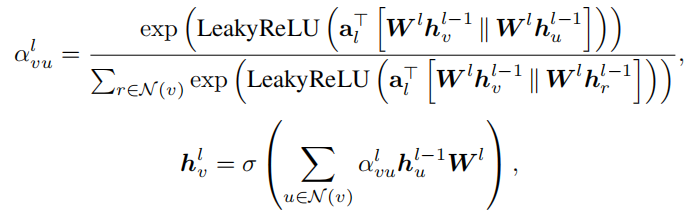
同构图和异构图:GNN模型默认假设图中的节点是同构的。通常认为基于这种同构假设,GNN不能很好地推广到异构图,然而标准的GCN在应用中可以很好的处理异构图。
3.2 训练GNN的关键超参数技术
归一化(Normalization)
一般常用的有layer Normalization和Batch Normalization,一般是在激活函数之前的一层使用
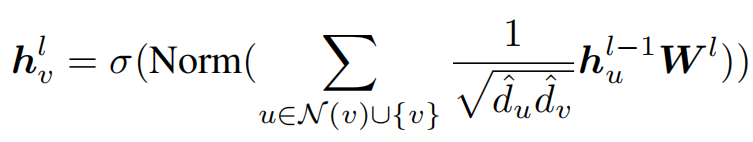
归一化技术可以通过减少协变量偏差来稳定训练过程。使得节点的特征空间维持在一个更加稳定的分布上,有了归一化,就可以使用更高的学习率和更快的收敛速度。
Dropout通过减少隐藏层之间的相互适应来避免过拟合问题。常用于CNN问题上,发现也适用于GNN领域。一般dropout是在激活函数后面的使用
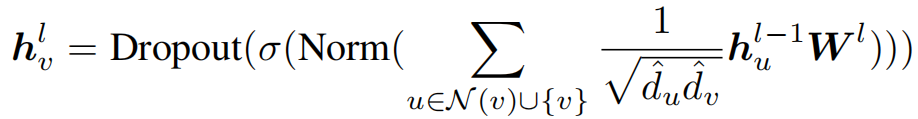
残差连接,直接把输入连接到输出从而减缓了梯度消散的问题。线性残差连接可以表示为

网络深度:越深的网络一般可以提取更复杂,更高阶的特征。然后GNN的深度增加会导致过度平滑问题。
已有的一些研究提出的DeepGCN和DeeperGCN,使用到了56和112层的深度。在本文发现浅层GNN同样可以达到相等效果,一般是在2-10层的范围。
4. 实验设置
采用了多种的数据类型,有同质图的,类似Cora等出版物数据,有异质图,类似Squirrel等数据。还有一类是大型图
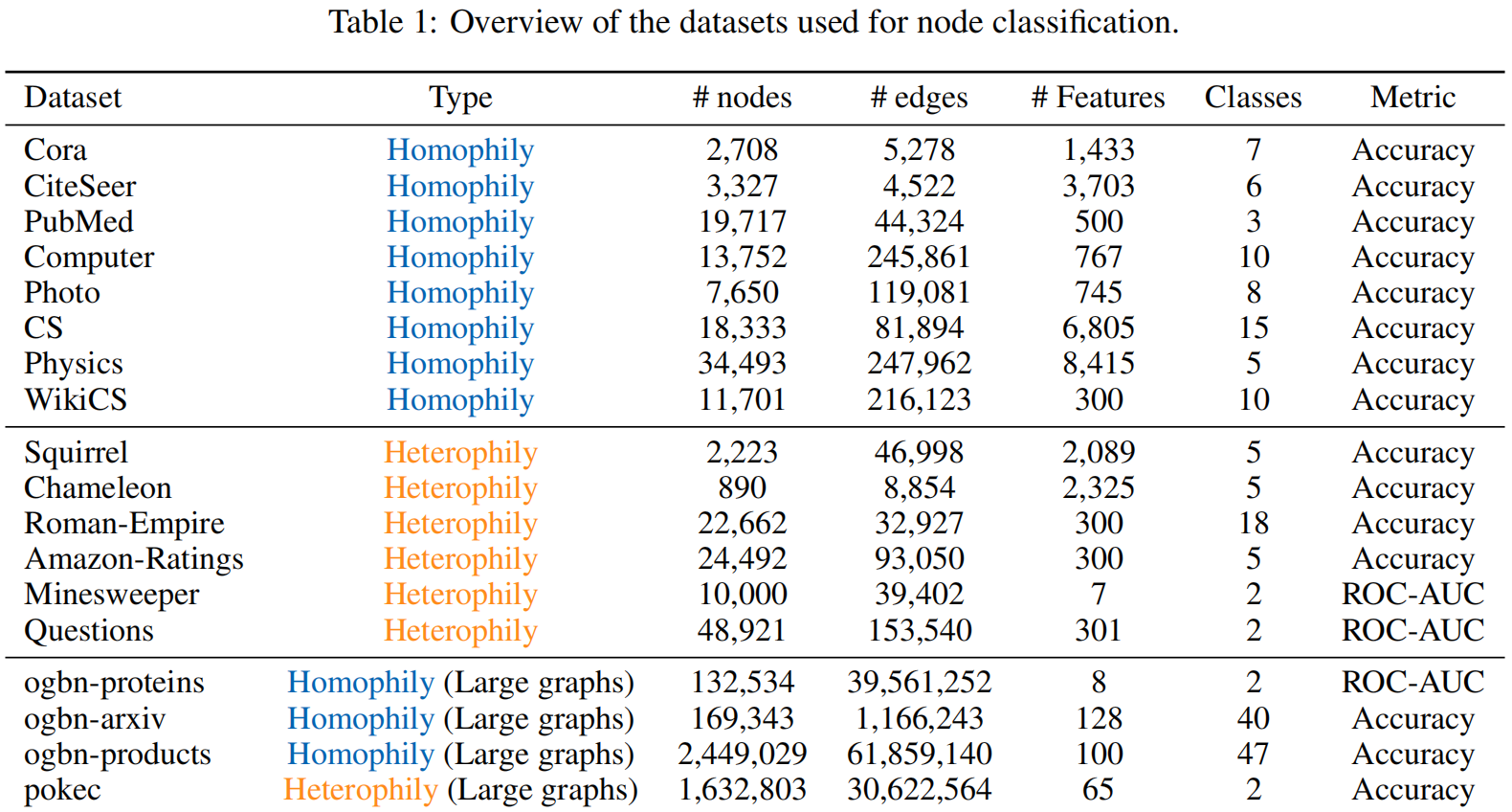
本文采用的经典GNN为三个,GCN,GAT,GraphSAGE。对比的GT主要为当前最为先进的。有SGFormer,Polynormer,GOAT,NodeFormer,NAGphormer,还有很强的GTs有:GraphGPS和Exphormer。
超参数设置:实验跑五次,以不同的随机数开始,最后取均值和方差。
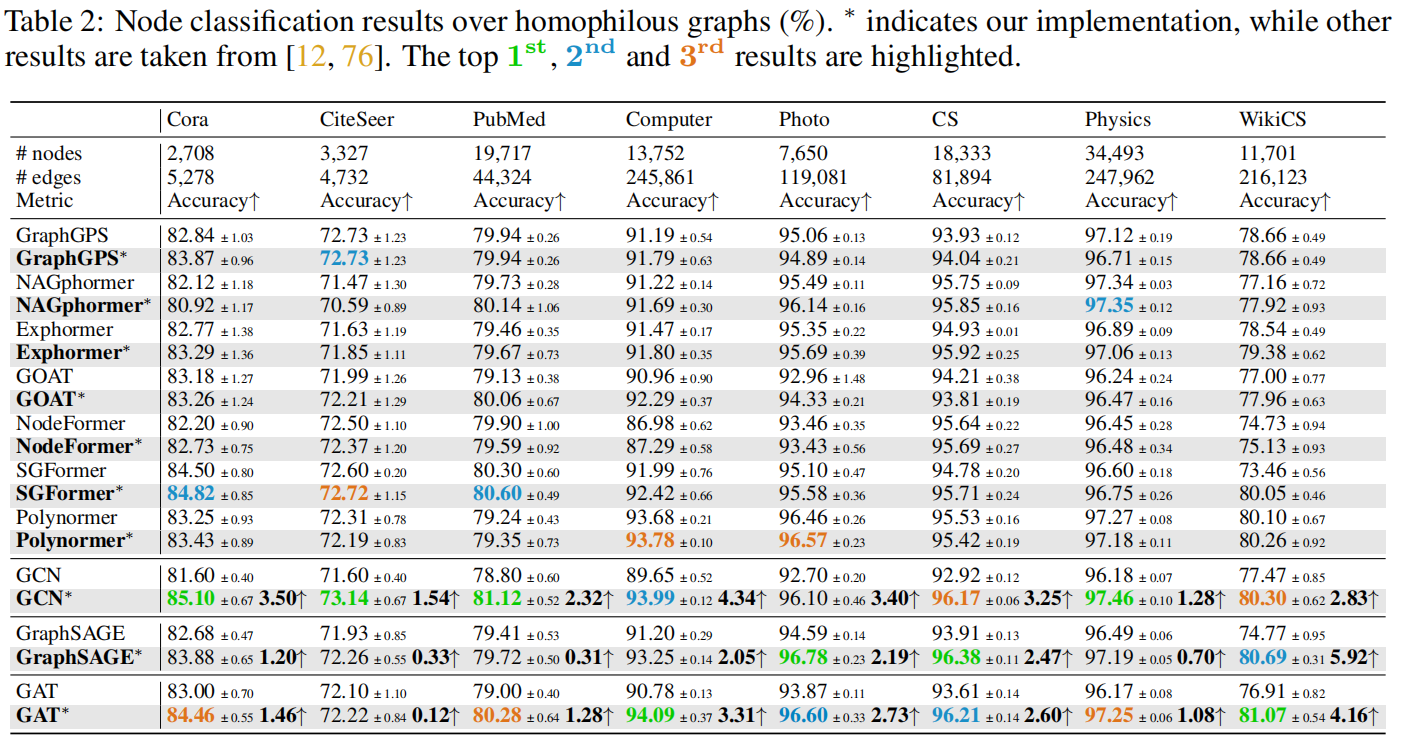
同质图的数据下的实验结果:可以发现经典的GNN模型,只需要对超参数的轻微调整,就可以在同质图数据上表现优异,在很多数据集上超过当前SOTA的graph transformer
异质图下的实验结果数据,本文的实验不仅让经典的GNN获得了比原paper更好的效果,也在很多数据集上比当前SOTA的GT表现更好。
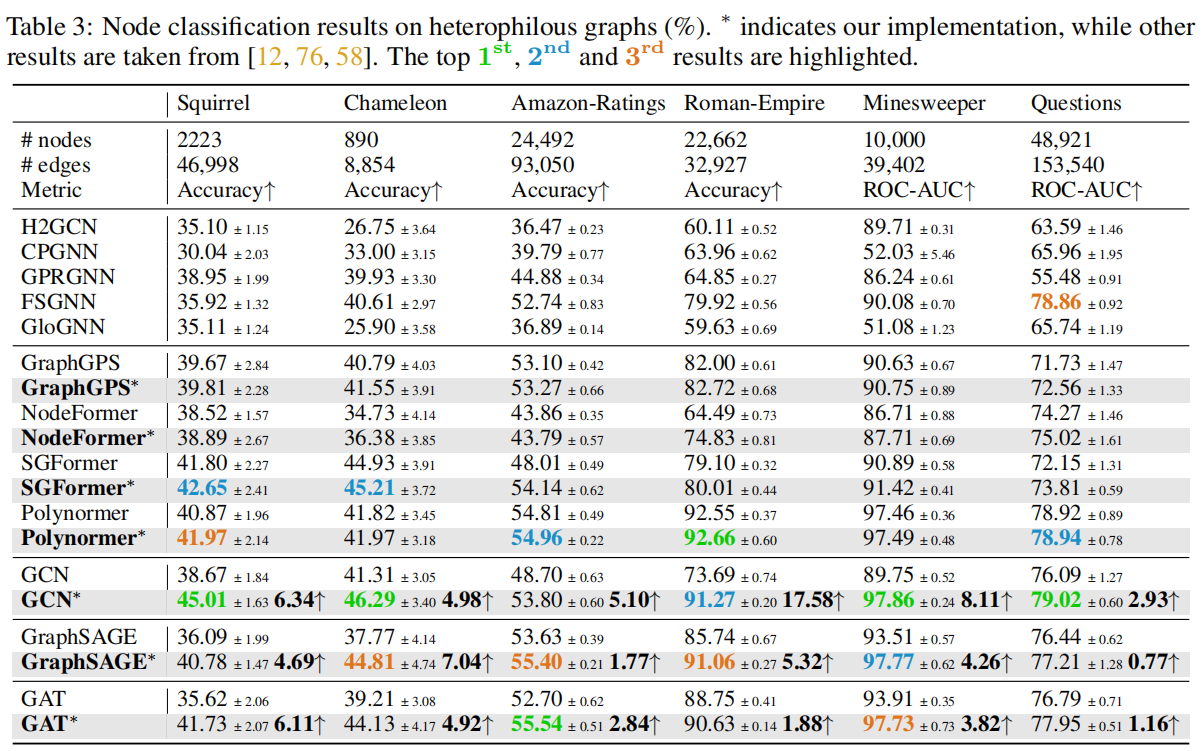
经典GNN的胜利,在侧面上也说明了当前火热的Graph Transformer还没有完全解决GNN的常见问题,如过度平滑和长距离依赖问题。
从实验数据得到几个观察
观察1:归一化(BN或LN)对于大尺度图上的节点分类很重要,但对于小尺度图则不太重要。
观察2:dropout始终被认为对节点分类至关重要
观察3:残差连接可以显著提高特定数据集上的性能,在异质图上表现出比同质图更显著的效果。
观察4:与同质图相比,深度更高的网络通常导致异质图的性能提高。
5. 结论
在日常实验中发现GNN还可以继续对其结构优化这一现象,就可以看出当前很多方法的根基不稳。确实有很多地方可以优化的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号