1.监督学习和无监督学习
下面用最通俗、最精炼的方式带你一次搞懂「监督学习」和「无监督学习」。
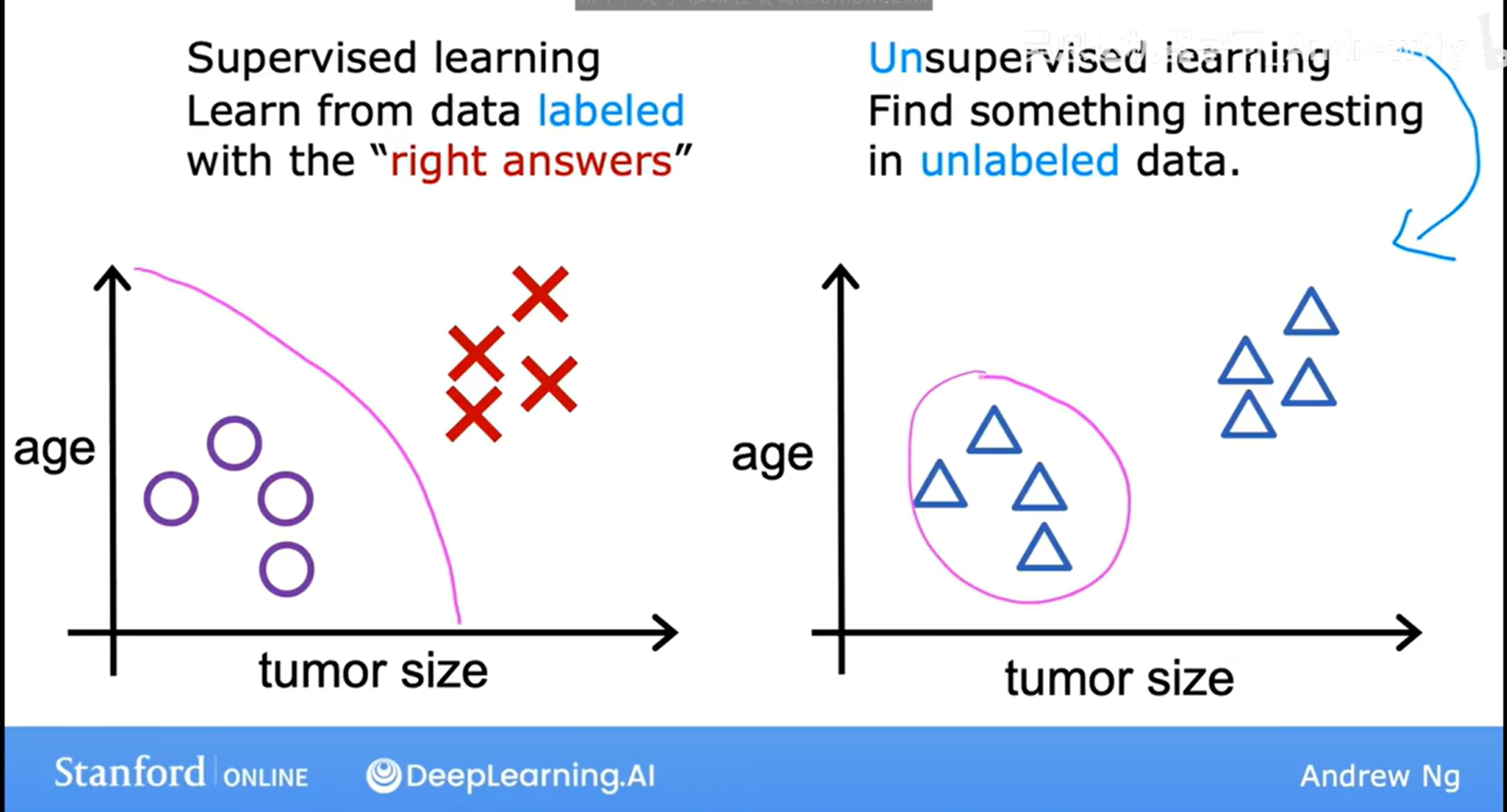
一、监督学习(Supervised Learning)
-
核心思想
拿“带答案的题”做训练,让模型学会“看到新题就能给出答案”。 -
数据长什么样
每条样本 = 特征 X + 标签 y(正确答案)。
例子:
• 房价预测:X = 面积、楼层、学区;y = 真实成交价。
• 垃圾邮件识别:X = 邮件文本;y = 0 正常 / 1 垃圾。 -
典型任务
• 回归:y 是连续值(房价、温度)。
• 分类:y 是离散类别(猫/狗、良性/恶性)。 -
常用算法
线性/逻辑回归、决策树、随机森林、SVM、神经网络、XGBoost…… -
训练流程
喂数据 → 算误差 → 反向调参 → 误差最小化 → 部署模型。
二、无监督学习(Unsupervised Learning)
-
核心思想
只有“题目”没有“答案”,让模型自己去找数据里隐藏的结构或规律。 -
数据长什么样
只有特征 X,没有标签 y。 -
典型任务
• 聚类:把相似样本自动分到同一组(用户分群、图像分割)。
• 降维:把高维数据压缩成低维,方便可视化或加速后续训练(PCA、t-SNE)。
• 异常检测:找出“跟大多数样本不一样”的点(信用卡欺诈、设备故障)。
• 密度估计:估计数据分布,生成新样本(GAN、VAE)。 -
常用算法
K-Means、DBSCAN、PCA、t-SNE、AutoEncoder、GMM、Isolation Forest……
三、一句话对比
监督学习:老师批改作业,学生学会答题;
无监督学习:没有老师,学生自己摸索数据里的“潜规则”。
四、延伸
• 半监督学习:有少量标签 + 大量无标签,降低标注成本。
• 自监督学习:把输入的一部分当“伪标签”,典型如 BERT、GPT。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号