大模型学习笔记(一)—— transformer
写在前面,一定要看懂self attention的代码实现,注意矩阵乘是谁@谁,矩阵乘不可以变换位置!!!
Attention的出现
由于翻译任务往往不是1 vs 1的翻译,因此输入与输出不等长,所以出现了encoder-decoder的形式:
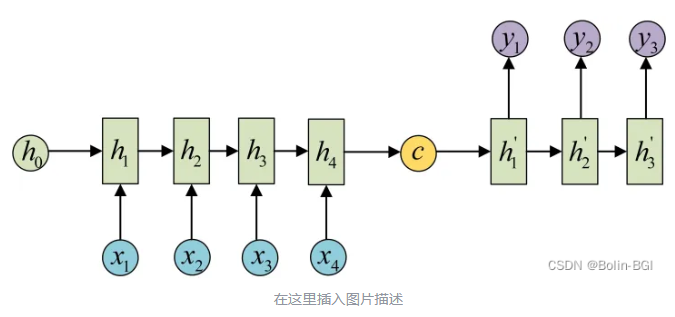
RNN具有短期记忆的问题,随着输入序列的增加,以前的输入的影响会越来越小。
传统encoder-decoder的缺陷
在传统的Encoder-Decoder结构中,Encoder处理一个输入序列,把它压缩成一个固定长度的向量c(也叫 context vector,上下文向量),然后这个c被Decoder用来逐步生成输出序列。比如:
- 输入序列:
I am a student(长度为4)。 - Encoder输出的最终隐藏状态
h4就是c。 - Decoder使用这个
c作为起点,开始翻译成另一个语言的句子。
不管输入序列有多长(比如一个 20 个词的长句子),最终都被压缩成一个固定长度的向量c,就会造成信息的丢失。
Attention如何解决这个问题?
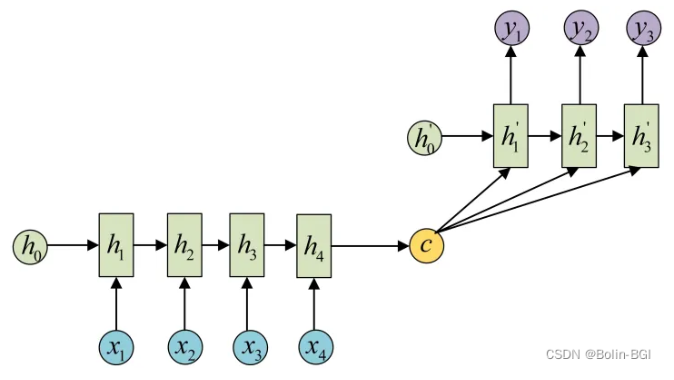
Attention机制通过在每个时间输入不同的c来解决这个问题,也就是说不再把全部信息压缩成一个c,Decoder每生成一个词时,可以动态地访问Encoder输出的所有隐藏状态(也就是输入序列每一步的编码),并根据当前生成内容“选择性关注”原始输入的不同部分。
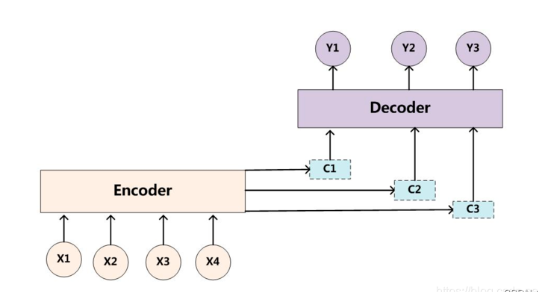
对于decoder而言,它获取的隐状态输入就需要有着重点,也就是"注意"到,哪里的信息更重要。因此encoder输出的隐状态,就需要对每一个输入有选择,这个选择就是注意力,本质上是给Encoder输出的每一个隐状态h_t一个权重(α),那么context vector (当前时刻) = ∑ (attention weight α_i × encoder output h_i)。
那么,接下来有了第二个问题:权重怎么计算?
权重的计算方式
对于Decoder而言,每一个位置都需要有自己的注意力,且每一个位置的注意力肯定是不一样的,这就推断出:每一个Decoder时间步的权重是根据当前时间步的隐状态和Encoder的隐状态一起计算出来的。计算注意力权重:
αₜᵢ = score(s_t, hᵢ) # i 从 1 到 n
aₜ = softmax([αₜ₁, αₜ₂, ..., αₜₙ]) # 权重向量
c_t = Σᵢ (aₜᵢ · hᵢ)
其中:score是注意力打分函数,transformer中最常用的就是:
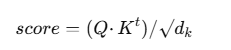
Attention机制
相比较于原来的RNN结构,Encoder的结构并没有改变,只是每一个时间步都输出了隐状态。attention是Decoder时,添加了注意力机制,计算了context vector与上一个时间步的输出一起做拼接,来预测当前时间步的输出。
-
Encoder的工作:
h_t = RNN(h_{t-1}, x_t) x_t 是第 t 个位置的输入词(嵌入) h_{t-1} 是上一个时间步的隐藏状态 -
Decoder的工作:
s_t = RNN(s_{t-1}, y_{t-1}, c_t) y_{t-1} 是上一个时间步的输出词的嵌入(注意是目标序列的词) s_{t-1} 是上一个隐藏状态 c_t 是当前时间步的上下文向量
QKV是什么?
上述基于RNN的attention没有显式的说明KQV这样的概念,因为KQV本身就是transformer之后才有的概念,但是看transformer里KQV的职能,仍然可以把基于encoder-decoder的attention划分到KVQ结构里:
| 角色 | 对应 | 来自哪里 |
|---|---|---|
| Query (Q) | Decoder 当前时间步的隐藏状态 s_t |
Decoder |
| Key (K) | Encoder 所有时间步的隐藏状态 h₁...h_Tx |
Encoder |
| Value (V) | Encoder 所有时间步的隐藏状态 h₁...h_Tx |
Encoder |
Attention是一种子结构,它的作用是:让当前的Query去从一堆Key-Value对中选择相关的Value,作为“上下文”提供给 Decoder 来生成输出。
在基于RNN的attention中,Query就是s_t,用来和Key也就是h₁...h_Tx生成score,这个score让它判断Value的重要性,获取当前时间步的输出。不过,这里也可以看出来,基于RNN的encoder和decoder结构的缺陷:必须按照顺序一个个预测输出,时间成本过高。为了解决这个问题,transformer使用Attention替代时间序列依赖。
Self Attention
在Encoder-Decoder框架中,Query是Decoder的隐状态,因为输入Source和输出Target内容是不一样的,任务站在输出的角度去“注意”输入内容的重要性,但是对于文本生成类任务而言,在后续对话中,模型应该关注的是自己之前生成的对话内容,不是最原始的问题,因此Self Attention相比较于Attention,最大的改变就是Query=Key=Value=X * w_{i} i ∈ {k, q, v},也就是说KQV都是经过输入X演变而来的。
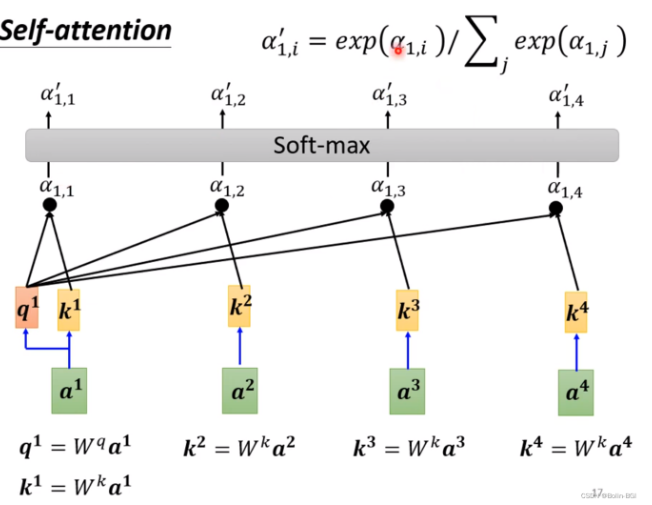
如上图所示,对于一个输入序列[a_1, a_2,...a_n]而言,分别可以与对应的参数矩阵点乘获得K向量[k_1, k_2,...k_n],Q向量[q_1, q_2,...q_n],V向量[v_1, v_2,...v_n]。对于第一个输入a_1而言,它对应的q_1想要计算注意力,就需要和[k_1, k_2,...k_n]分别计算,然后再进行归一化softmax处理之后,得到a_1对于其他所有输入得attention score,attention score再与[v_1, v_2,...v_n]做点积,就是最终的预测结果,如下图所示:
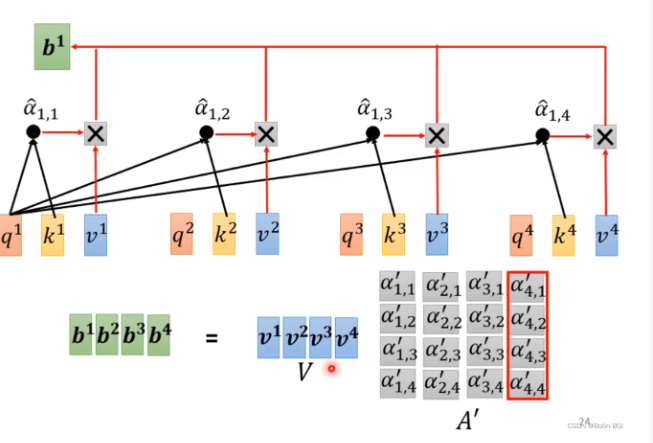
那么现在清楚了,对于长度为n的序列,生成的attention score的大小是nxn,再与V向量做矩阵乘后,得到长度为n的输出序列。
Self Attention的score的计算方法为:
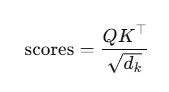
其中,由于每一个句子做了分词+词嵌入,所以一个词是大小为embed_dim的向量,所以做点乘以后会很大,softmax 会趋于极端(0或1),梯度变得很小(饱和),训练变困难,所以要除以一个scale`。
下面附赠代码实现:
import torch
import torch.nn.functional as F
class SelfAttention(torch.nn.Module):
def __init__(self, embed_dim):
super().__init__()
self.embed_dim = embed_dim
self.scale = embed_dim ** 0.5
# W^Q, W^K, W^V
self.W_Q = torch.nn.Linear(embed_dim, embed_dim)
self.W_K = torch.nn.Linear(embed_dim, embed_dim)
self.W_V = torch.nn.Linear(embed_dim, embed_dim)
def forward(self, x):
# x: [batch_size, seq_len, embed_dim]
Q = self.W_Q(x) # [batch_size, seq_len, embed_dim]
K = self.W_K(x) # same shape
V = self.W_V(x) # same shape
# 计算 Attention Scores: Q @ K^T
scores = torch.matmul(Q, K.transpose(-2, -1)) / self.scale # [batch, seq_len, seq_len]
# 归一化
weights = F.softmax(scores, dim=-1) # [batch, seq_len, seq_len]
# 加权求和 Value
out = torch.matmul(weights, V) # [batch, seq_len, embed_dim]
return out
Multi-head Self-attention
为什么需要Multi-head?
多头注意力机制的核心思想是“将注意力计算分成多个子空间并行计算,每个子空间叫一个头(Head)。”
单头注意力机制的核心问题——单头注意力的表达能力太弱,比如翻译这句话:“The cat that was chased by the dog ran away.”:有的词要关注近邻语法结构(如:the 和 cat);有的词要关注远程依赖(如:cat 和 ran);有的词关注语义上类似的词;有的关注句法结构(比如主语、宾语),单头只能学其中一种关系,不够用。
多个头并行学习多种语义、句法关系,从不同上下文解读含义。
Multi-head原理
┌──────────────┐
Input →──► Linear(QKV) ├─┬──► Head1: Attention(Q₁,K₁,V₁)
└──────────────┘ │
├──► Head2: Attention(Q₂,K₂,V₂)
│
├──► ...
│
└──► HeadN: Attention(Qₙ,Kₙ,Vₙ)
Heads拼接 → Concat → Linear → Output
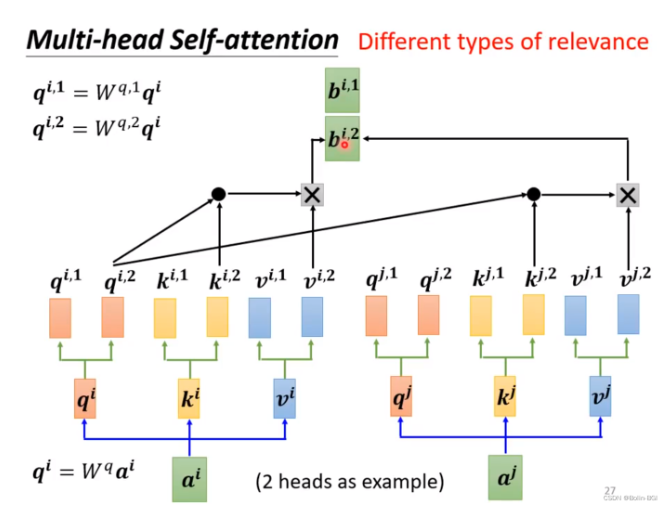
和单头的相比,QKV的向量,变成了QKV矩阵,那么score维度由原来的n x n变成了m x n x n,其中m是指head的数目。最后所有的头的结果拼接后,经过线性层映射为输出。
transformer
位置编码(Positional Encoding)
Transformer 的 Self-Attention 机制是对“序列中所有词做一视同仁的加权平均”,它的核心是这些矩阵计算:
attention_score = softmax(Q @ K.T)
output = attention_score @ V
因此,这一过程根本不会用到token的位置。它只看词之间的相似程度,和它是第几个没关系。为了让模型有位置意识,位置编码(Positional Encoding)就是把每个 token 的位置信息编码成向量,然后加到原始的词向量上,最终的输入 = token 的词向量 + 它的位置向量(positional encoding)。
BERT 之后常用Learnable position embedding,把位置也当作一个词,直接用embedding表示,跟token embedding一样参与训练。
transformer的结构
transformer的结构如下图:
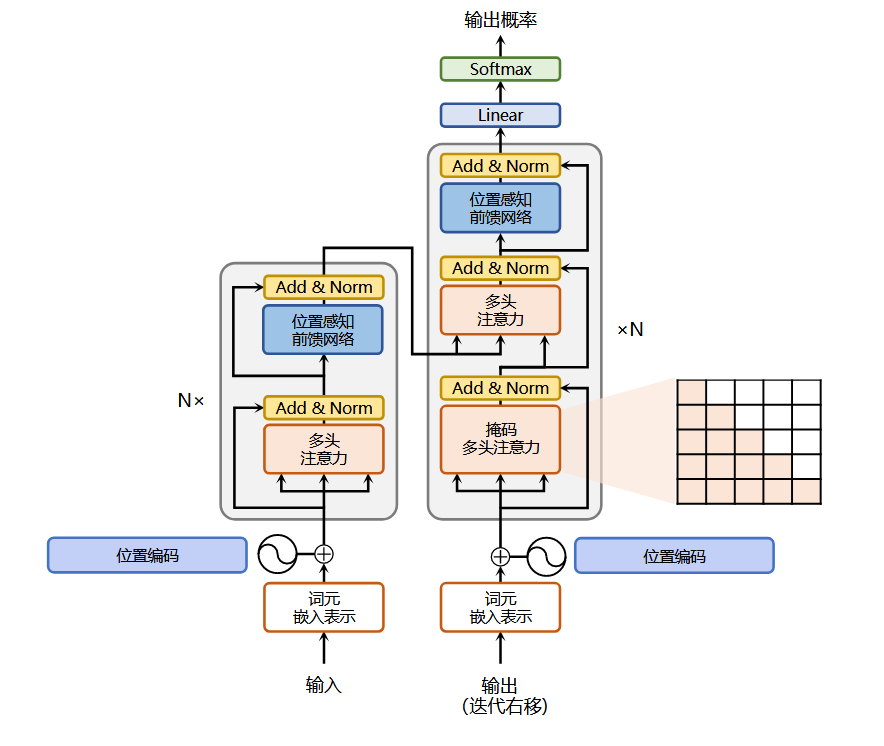
transformer仍然采用Encoder和Decoder结构,其中:
-
Encoder:多头自注意力(Self-Attention)+ 前馈网络(Feed Forward)。
-
多头自注意力:允许模型在同一层中,通过不同的头并行地捕捉各个位置之间的依赖关系,从不同角度来聚合上下文信息,为后续的特征提取提供更丰富的输入表示。
-
前馈网络:一般由两个线性层和一个激活函数构成。对每个 token 进行更细致的特征提取和非线性变换,增加模型的复杂表达能力?(不明白)教材中提到:
实验结果表明,增大前馈子层隐状态的维度有利于提 高最终翻译结果的质量,因此,前馈子层隐状态的维度一般比自注意力子层要大。
-
残差与归一化层:残差避免过程中出现的梯度消失,归一化缓解收敛速度慢等问题。
-
Q:为什么transformer 里的前馈网络叫位置感知前馈网络?它不是只是两层全连接吗?哪里体现了位置感知?
虽然前馈网络FFN是对每个位置独立处理的,但由于 transformer 中每个 token 有位置信息(Position Encoding),所以这个 FFN 间接地感知了位置,因此称它为位置感知前馈网络。(尴尬笑)
-
Decoder:Masked多头自注意力(用于生成当前词时只能看到前面的词)+ 编码器-解码器注意力(Encoder-Decoder Attention)+ 前馈网络。
-
Transformer的Decoder结构稍微比Encoder复杂一点,因为它需要在生成新词时既考虑已有的生成历史,又能从Encoder的输出中获取上下文信息。
-
Masked Multi-head Self-Attention:输入是目标序列(标签)经过嵌入之后的表示,让Decoder在生成第 t 个词时,只能“看到”前 t−1 个词,防止模型提前“看到”未来词(泄露信息),代码中,score的下三角全部是负无穷。
-
Encoder-Decoder Attention:Decoder 查询 Encoder 的输出,决定当前要生成哪个词。Q 来自 Decoder 的前一个子层(即 Masked Attention 的输出),代表当前要“写”的意图。K, V 来自 Encoder 的输出,代表输入语句的整体信息。
-
Feed Forward Network:对每个位置的向量单独进行非线性转换,增强表示能力,类似于在每个时间步上加一个 MLP。
-
这里歪一个问题:个人感觉transformer的编码器和解码器是有点反直觉的,人类想知道一个问题的答案,会用问题作为Q,关注答案也就是K和V到底是什么,做出检索,但是transformer的encoder对问题做了自注意力,后面经过位置感知前馈网络,在decoder中做了KV。
GPT对此给出的答案是:
Transformer 中的 Attention 机制逻辑是:Query是我正在思考的东西,Key和Value是我能参考的信息。所以Decoder在生成每一个token的时候,它才是主动思考者,Query自然来Decoder,它看Encoder 的输出,去从中找有用信息,这就是K和V。
Encoder张量大小梳理
为了防止,对过程理解的误区,这里放了整个encoder的过程中,张量大小的变化。
| 模块 | 输入 Shape | 输出 Shape |
|---|---|---|
| 输入嵌入 + 位置编码 | [B, L] → [B, L, D] |
[B, L, D] |
| Q/K/V 投影 | [B, L, D] |
[B, H, L, D_head] |
| 注意力score | [B, H, L, D_head] |
[B, H, L, L] |
| score应用到V | [B, H, L, L] |
[B, H, L, D_head] |
| 多头合并输出 | [B, L, D] |
[B, L, D] |
| 前馈网络 | [B, L, D] → [B, L, D_ff] → [B, L, D] |
[B, L, D] |
| 最终输出 | [B, L, D] |
[B, L, D] |
Q/K/V 投影:D_head * H = D,每一个头的Q/K/V是embedding维度平分的,保证后续经过attention后合并,维度还是[B, L, D]。
| 项目 | 值 |
|---|---|
batch_size |
B |
seq_len(序列长度) |
L |
embedding_dim / d_model(嵌入维度) |
D(如 512) |
num_heads(注意力头数) |
H(如 8) |
d_ff(前馈网络中间维度) |
D_ff(如 2048) |
Attention+RNN 与 transformer
与Attention + RNN的机构相比,transformer不需要循环处理,也就是没有时间步这样的概念,而是采用位置编码,编码时间序列信息,然后一次处理。transformer的处理过程如下:
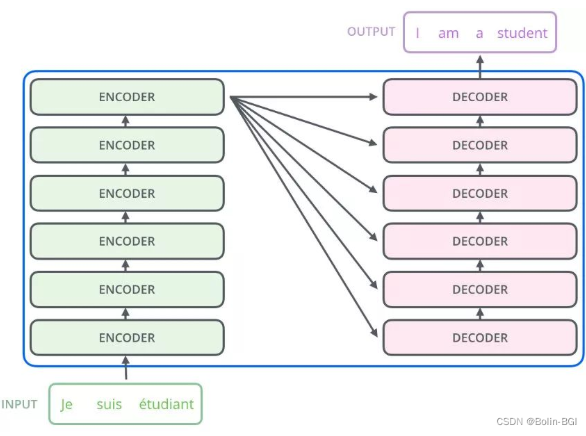
这里可以看到,encoder和decoder都循环了很多次,但是这种循环与RNN不同,RNN的循环是为了生成下一个输出,而它的循环是为了更好的理解语义。Encoder是为了更好的理解问题,变换出更优秀的词向量(K、V)!而Decoder则是为了更好的回答问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号