

一文彻底搞懂attention机制
一、什么是attention机制
Attention机制:又称为注意力机制,顾名思义,是一种能让模型对重要信息重点关注并充分学习吸收的技术.通俗的讲就是把注意力集中放在重要的点上,而忽略其他不重要的因素。其中重要程度的判断取决于应用场景,拿个现实生活中的例子,比如1000个人眼中有1000个哈姆雷特。根据应用场景的不同,Attention分为空间注意力和时间注意力,前者用于图像处理,后者用于自然语言处理.
二、为什么需要注意力机制
注意力机制最早用在seq2seq模型上,原始编解码模型的encode过程会生成一个中间向量C,用于保存原序列的语义信息。但是这个向量长度是固定的,当输入原序列的长度比较长时,向量C无法保存全部的语义信息,上下文语义信息受到了限制,这也限制了模型的理解能力。如下图:
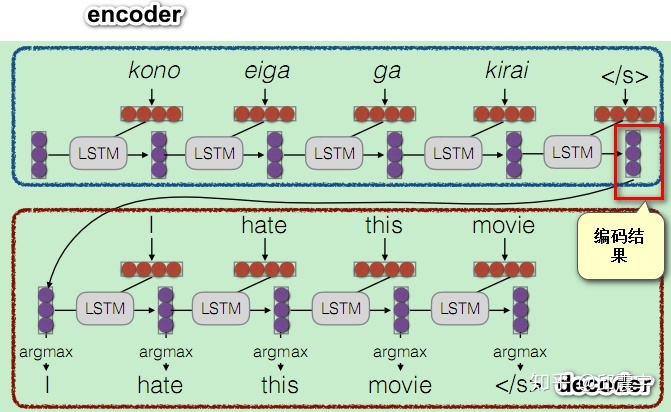
这种编码方法,无法体现对一个句子序列中不同语素的关注程度,在自然语言中,一个句子中的不同部分是有不同含义和重要性的,比如上面的例子中:I hate this movie.如果是做情感分析的应用场景,训练的时候明显应该对hate这个词语做更多的关注。
三、Attention的原理
基本流程描述,以seq2seq模型为例子,对于一个句子序列S,其由单词序列[w1,w2,w3,...,wn]构成:
1)将S的每个单词 编码为一个单独向量
,这里对应seq2seq模型,就是在encoder编码阶段,每个时间步单位(即每个单词)的输出隐状态。
2)在解码decoder阶段,待预测词的输入隐状态C(即上一个时间步的输出状态)与1中每个单词的隐状态相乘再做softmax归一化后得到权重分数,使用学习到的注意力权重 对1中得到的所有单词向量做加权线性组合Z=
.
3)利用输入状态C以及输入变量Z作为对待预测词的共同输入,来进行预测。
公式步骤:
1)首先利用RNN模型已经得到了序列的隐层状态(h1,h2,...,hn)
2)如果当前decoder阶段已经到了Si-1,要进行下一个Si的预测了,接下来计算每一个输入位置hj对当前位置i的影响
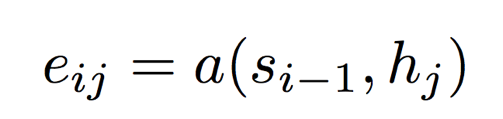
3)eij做归一化处理,得到attention的权重分布
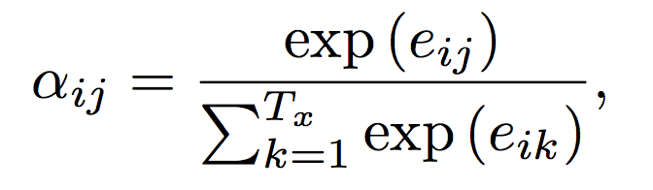
4)利用αij进行加权求和,得到相应的context vector。

5)计算预测最终的输出
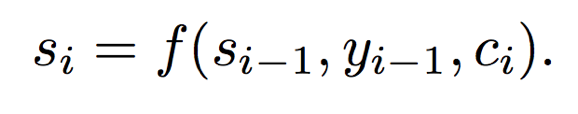
以例子进行更通俗详细的描述:
我们的最终目标是要能够帮助decoder在生成词语时,有一个不同词语的权重的参考。在训练时,对于decoder我们是有训练目标的,此时将decoder中的信息定义为一个Query。而encoder中包含了所有可能出现的词语,我们将其作为一个字典,该字典的key为所有encoder的序列信息,n个单词相当于当前字典中有n条记录,而字典的value通常也是所有encoder的序列信息,一般情况下,key和value是一样的。
上面对应于第一步,然后是第二部计算注意力权重,由于我们要让模型自己去学习该对哪些语素重点关注,因此要用我们的学习目标Query来参与这个过程,因此对于Query的每个向量,通过一个函数 ,这里的Qi就是上一个时间步的输出隐状态,计算预测i时刻词时,需要学习的注意力权重,由于包含n个单词,因此,
应当是一个n维的向量,为了后续计算方便,需要将该向量进行softmax归一化,让向量的每一维元素都是一个概率值。
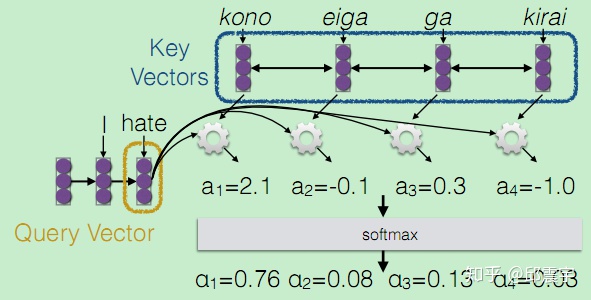
上图的黄色框圈的hate变量,就是由I单词之后的输出隐状态C,也可以称之为q,这里的q再与上面的Key Vector相乘再做softmax归一化得到一个权重分数。
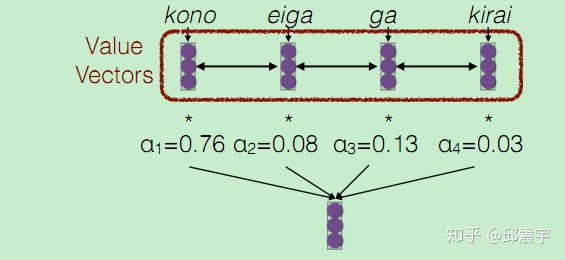
这个权重分数再与Value Vectors(这里的value与key一样)进行加权线性组合,得到一组新的带有注意力的变量,这个变量就是预测hate的输入值Z,最后由C和Z来共同输入预测hate。
四、Self-Attention
1)Self-Attention与 传统的Attention机制有什么不同呢?
Self- Attention与传统的Attention机制非常的不同:传统的Attention是基于source端和target端的隐变量(hidden state)计算Attention的,得到的结果是源端(source端)的每个词与目标端(target端)每个词之间的依赖关系。
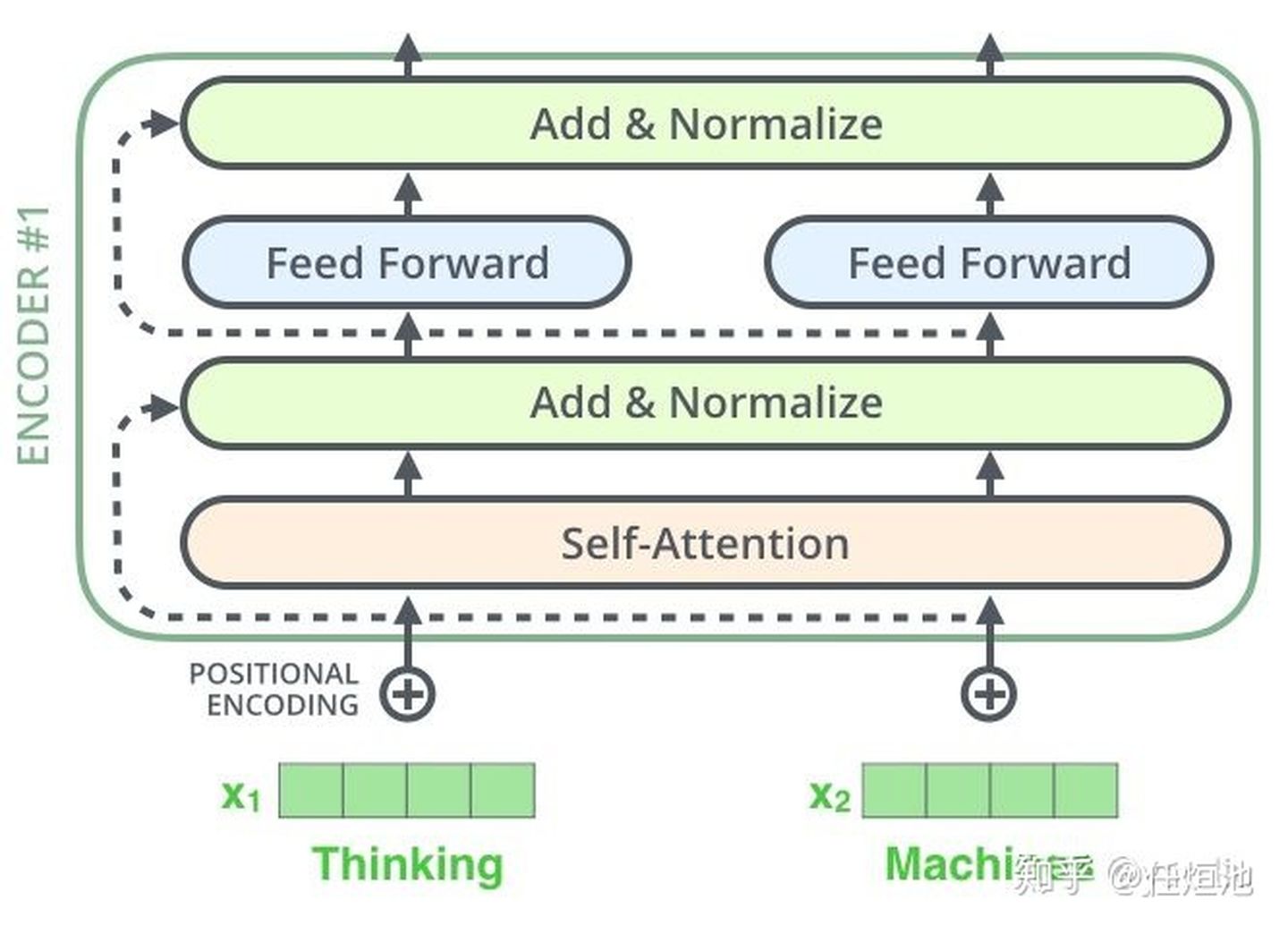
但Self -Attention不同,它首先分别在source端和target端进行自身的attention,仅与source input或者target input自身相关的Self -Attention,以捕捉source端或target端自身的词与词之间的依赖关系;然后再把source端的得到的self -Attention加入到target端得到的Attention中,称作为Cross-Attention,以捕捉source端和target端词与词之间的依赖关系。如下图的架构:
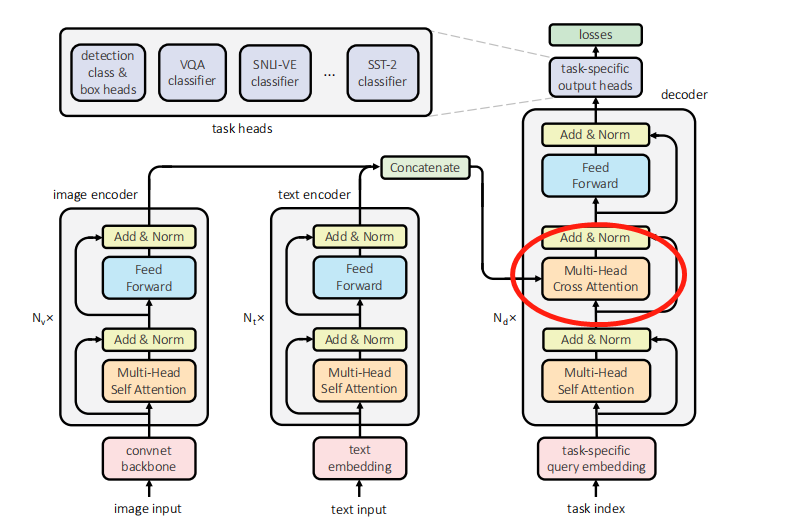
因此,self -Attention比传统的Attention mechanism效果要好,主要原因之一是,传统的Attention机制忽略了源端或目标端句子中词与词之间的依赖关系,相对比,self Attention可以不仅可以得到源端与目标端词与词之间的依赖关系,同时还可以有效获取源端或目标端自身词与词之间的依赖关系。
2)Self-Attention的计算
参考论文《Attention is all you need》的计算方式
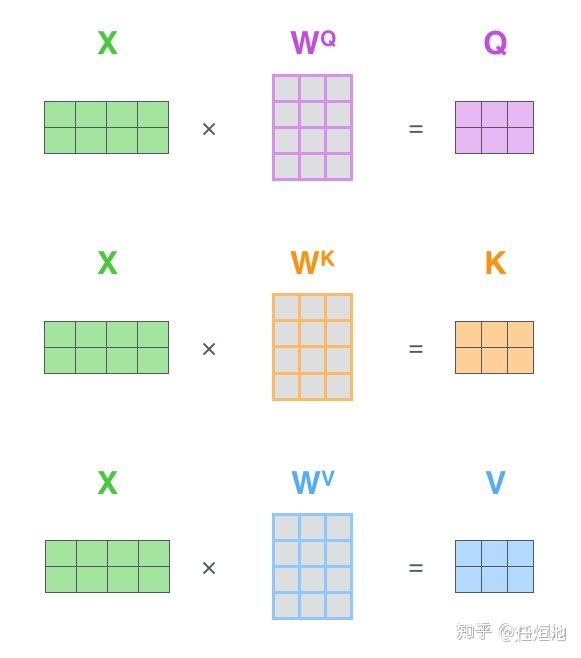
- 将输入单词转化成嵌入向量X;
- 根据嵌入向量X与权重参数相乘,分别得到
,
,
三个向量;
- 为每个向量计算一个score:
;
- 为了梯度的稳定,Transformer使用了score归一化,即除以
;
- 对score施以softmax激活函数;
- softmax点乘Value值
,得到加权的每个输入向量的评分
;
- 相加之后得到最终的输出结果
:
。
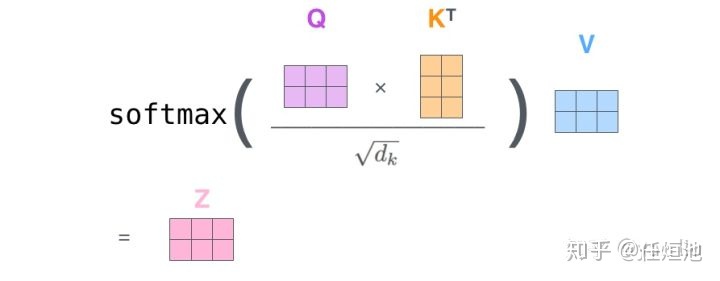
3)self-attention为什么会有效?
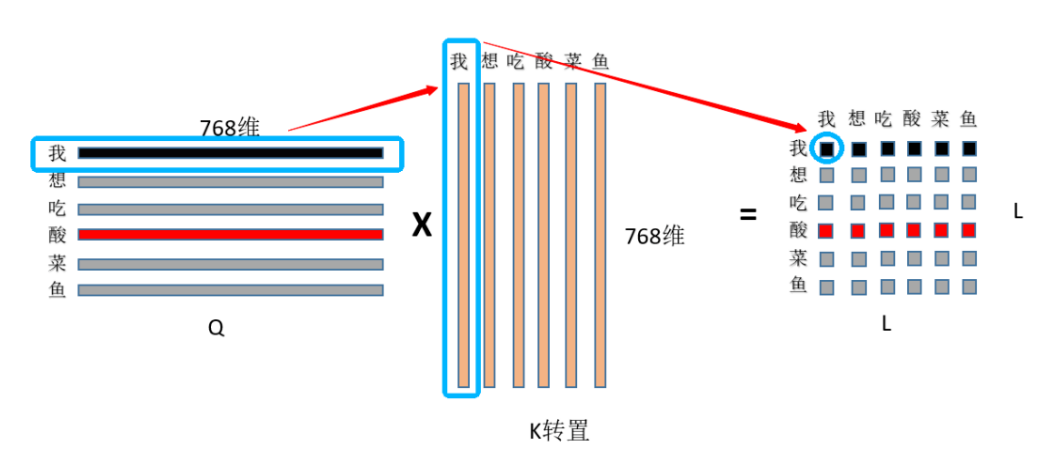
self-attention通过Q*K得到的词与词之间的相关性矩阵,然后根据此相关性与V进行加强求和,这样最终输出的向量主要就是由与之相似的词的向量融合构成的,与之不相似的向量对其贡献度可以忽略不计,如下图:

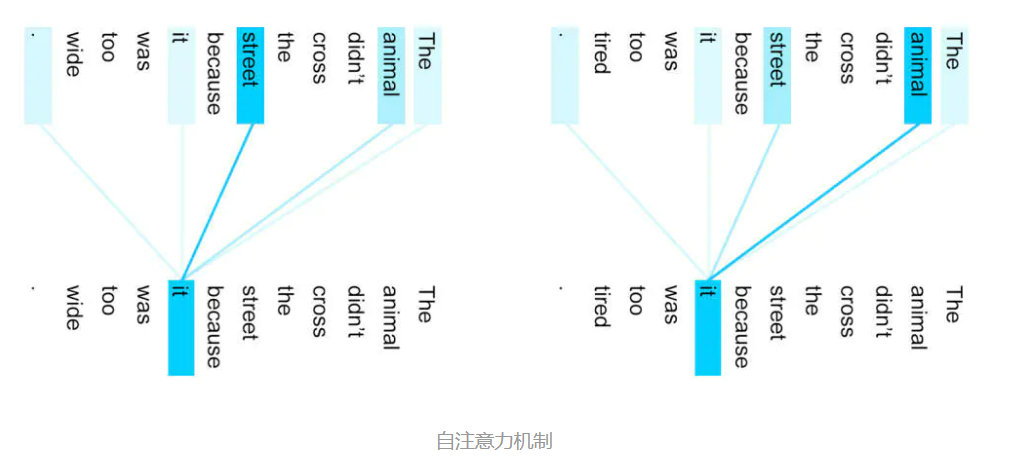
这样最终计算出来的向量就会变成,如果两个词很相似,那么其向量的相似度也很近,就起到了语义层面的意义,这样词与词之间就因其语义的不同而自动区分开来了,所以就很有效。
参考:https://zhuanlan.zhihu.com/p/46313756
https://zhuanlan.zhihu.com/p/79115586

 浙公网安备 33010602011771号
浙公网安备 33010602011771号