paddlepaddle训练网络的基本流程二(进阶Paddle-detection框架)
包含项目结构、整体训练流程、训练调用细节
目的仅为梳理paddle在目标检测方面的训练流程以及调用细节,详见官方文档及代码
Paddle-detection框架
首先,观察整个项目的目录结构: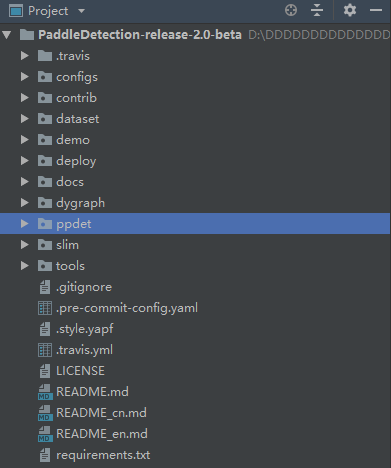
静态图选择配置模型在configs中,支持数据类型在dataset中,所有模型具体代码在ppdet中,数据加载处理部分在ppdet/data中,slim是模型蒸馏压缩,tools是常用的训练文件(包含train.py,eval.py,infer.py等),
dygraph即动态图部分,配置比上述静态图简单的多,与pytorch类似不做过多介绍。
pdpd配置文件:
Paddle-detection里面采用比较灵活的config设置,要记住非常多的设置都是在config里调整的,一套config设置联系了训练文件、模型、模型的结构、数据集、评估等系统。
从自动化和静态分析的原则出发,PaddleDetection采用了一种用户友好、 易于维护和扩展的配置设计。利用Python的反射机制,
PaddleDection的配置系统从Python类的构造函数抽取多种信息 - 如参数名、初始值、参数注释、数据类型(如果给出type hint)- 来作为配置规则。 这种设计便于设计的模块化,提升可测试性及扩展性。

简单地说就是类上方有装饰器函数,类内有__inject__等定义具体的配置参数。
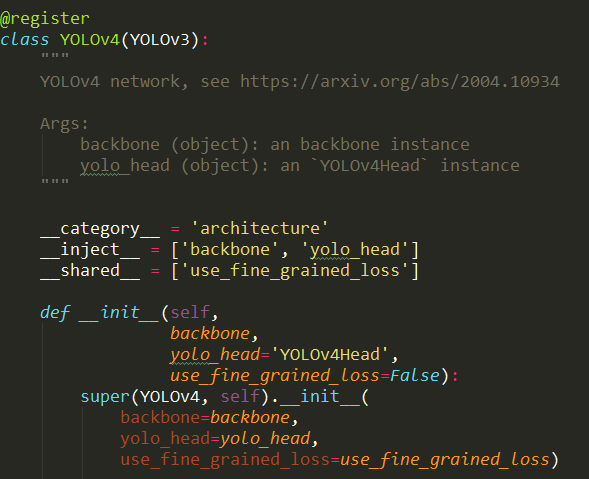
目标检测的完整流程:
1.准备数据
2.模型选择(选择、修改config文件)
3.训练
4.评估和推理
5.模型压缩以及部署
1.数据相关
数据配置部分都在config目录中每个模型的配置文件中reader项,包括(TrainReader,EvalReader,TestReader)
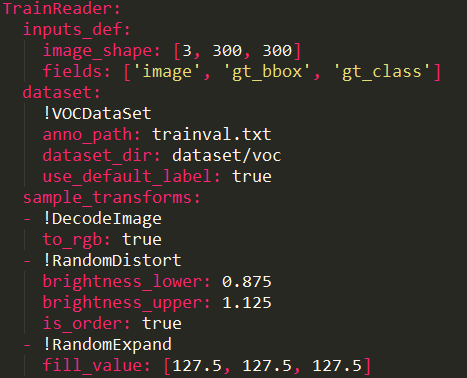
具体如何准备训练数据参照官方文档:(支持coco\voc\自定义)
2.模型选择(选择、修改config文件)
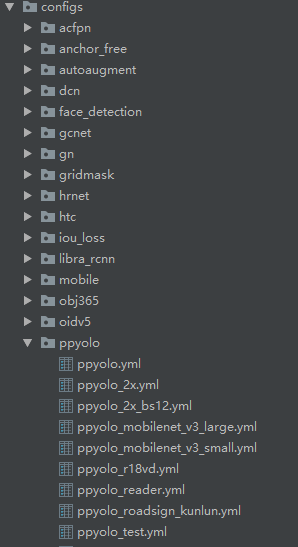
一级文件夹代表可用模型,二级代表不同配置(例如backbone不同)
参照模型库中每个模型的具体参数(推理时间、准确率等),选择合适的模型
常改的参数包括:max_iters、num_classes、LearningRate、dataset路径、batch-size
3.开始训练
python tools/train.py -c configs/yolov3_mobilenet_v1_roadsign.yml -o use_gpu=true --eval利用tools/train.py启动训练,参数带上configs文件等
多卡使用tools/train_multi_machine.py训练
python -m paddle.distributed.launch \
--selected_gpus 0,1,2,3,4,5,6,7 \
tools/train_multi_machine.py \
-c configs/yolov3_mobilenet_v1_roadsign.yml4.评估推理
利用tools/eval.py以及infer.py进行评估以及推理
5.模型压缩以及部署
压缩部分在slim文件夹里,包含剪枝、蒸馏、量化等操作,加速模型推理。
部署部分参考PaddleDetection预测部署文档,支持服务端、移动端、嵌入式多种方式,支持python\c++部署
使用tools/export_serving_model.py导出模型时,即可使用PaddleServing部署方式直接部署。
训练时调用细节(以ppyolo模型为例)
首先从训练文件train.py找起

加载全局配置文件,解析传入的ppyolo.yml,配置各种运行环境。
构建program,获取模型结构,损失函数、优化器等
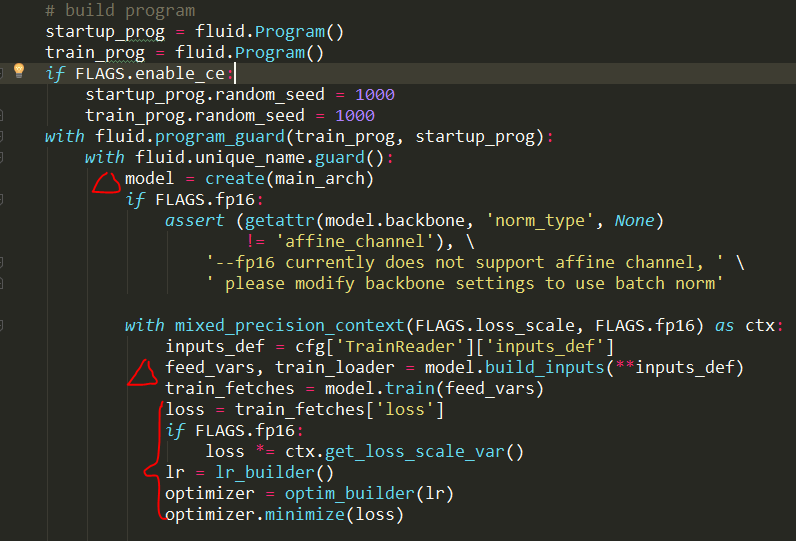
初始化以及编译program

创建reader

执行训练
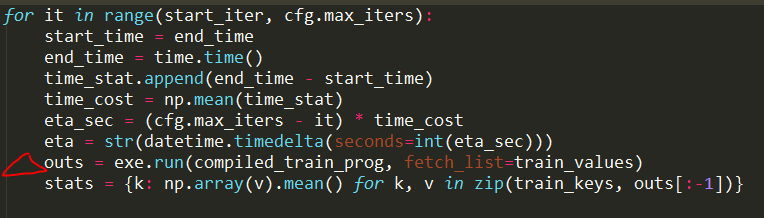
再从模型文件yolo.py找起
位于ppdet\modeling\architectures\yolo.py
定义了yolov3的结构,主要分为backbone、yolo_head、yolo_loss几部分,可参考ppyolo的结构图:

每个模型中包含build、build_inputs函数,在训练时主要调用这两个函数。
build_inputs是定义模型输入的函数,在这里可以认为是feed_var
build函数主要是定义如何从inputs获得outputs的过程,中间经历了什么算子。一般是inputs通过backbone、neck、head得到loss,backbone定义在ppdet/modeling/backbones中,
neck即类fpn操作也是在ppdet/modeling/backbones中,head存在ppdt/modeling/anchor_heads中。整个modeling的目录定义了非常全的结构:

再从数据配置找起:
在train.py中定义的train_reader,调用了ppdet/data/reader中的create_reader函数
此函数中实例化一个reader对象,reader类中包含了各种对于数据的处理(获取参数、数据增强、预加载、返回batch等等)。
config文件中对于数据集的数据增强
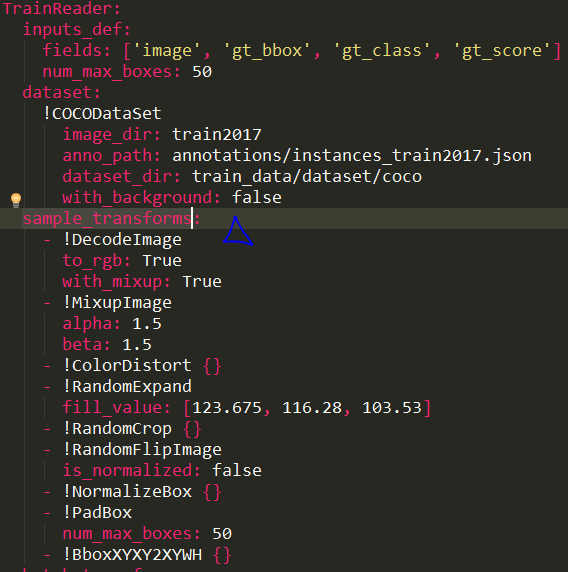
对照reader类中transforms属性,

最后调用_reader函数返回训练数据。
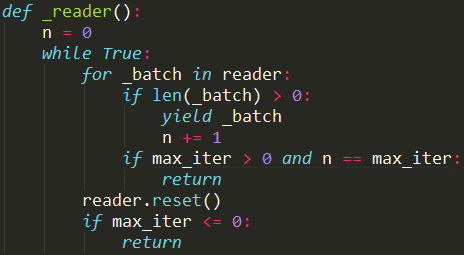
训练时互相调用的关系、位置大概就是这样,先有大致印象,具体参照完整代码理解更佳。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号