图像语义分割的几种结构
FCN在之前做过介绍
下面是几种对称结构,基本上都是基于编码和解码的过程,主要使用了卷积和反卷积,池化,上采样的结构。
上采样的实现主要在于池化时记住输出值的位置,在上池化时再将这个值填回原来的位置,其他位置填0。
SegNet

DeconvNet
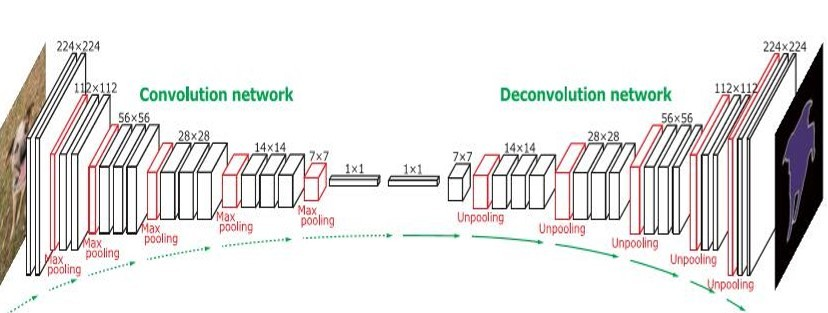
下面是一种稍微成熟的结构,称为带洞卷积结构。
DeepLab
带洞卷积实际上就是普通的卷积核中间插入了几个洞,如下图。
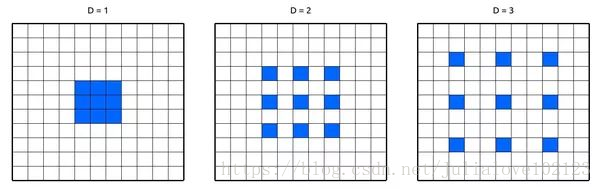
它的运算量跟普通卷积保持一样,好处是它的“视野更大了”,比如普通3x3卷积的结果的视野是3x3,插入一个洞之后的视野是5x5。视野变大的作用是,在特征图缩小到同样倍数的情况下可以掌握更多图像的全局信息,这在语义分割中很重要。
凤舞九天

 浙公网安备 33010602011771号
浙公网安备 33010602011771号