
结巴分词实现词频统计
结巴分词实现词频统计
前言
再简单了解了结巴分词以后下面开始,使用结巴分词辅助大数据分析任务实现词频统计
环境搭建
创建虚拟环境,安装 panda 和jieba 两个依赖
conda create -n BigDigital python=3.10 -y
conda activate BigDigital
pip install jieba pandas
读取文件词频统计
import pandas as pd
import jieba
# 读取 Hive 导出的 TSV/CSV
df = pd.read_csv("jd.csv", sep="\t", header=None,
names=["username", "brand", "model", "rating", "date", "comment"])
df["comment"] = df["comment"].astype(str)
# 创建词频 dict
word_freq = {}
for text in df["comment"]:
words = jieba.lcut(text)
for w in words:
w = w.strip()
if len(w) <= 1: # 去掉单字、符号
continue
word_freq[w] = word_freq.get(w, 0) + 1
# 转换为 DataFrame
wf = pd.DataFrame(list(word_freq.items()), columns=["word", "freq"])
# 按词频排序
wf = wf.sort_values(by="freq", ascending=False)
# 保存为 Hive 能读的 TSV
wf.to_csv("word_freq.tsv", sep="\t", index=False, header=False)
print("分词+词频统计完成 → word_freq.tsv 已生成!")
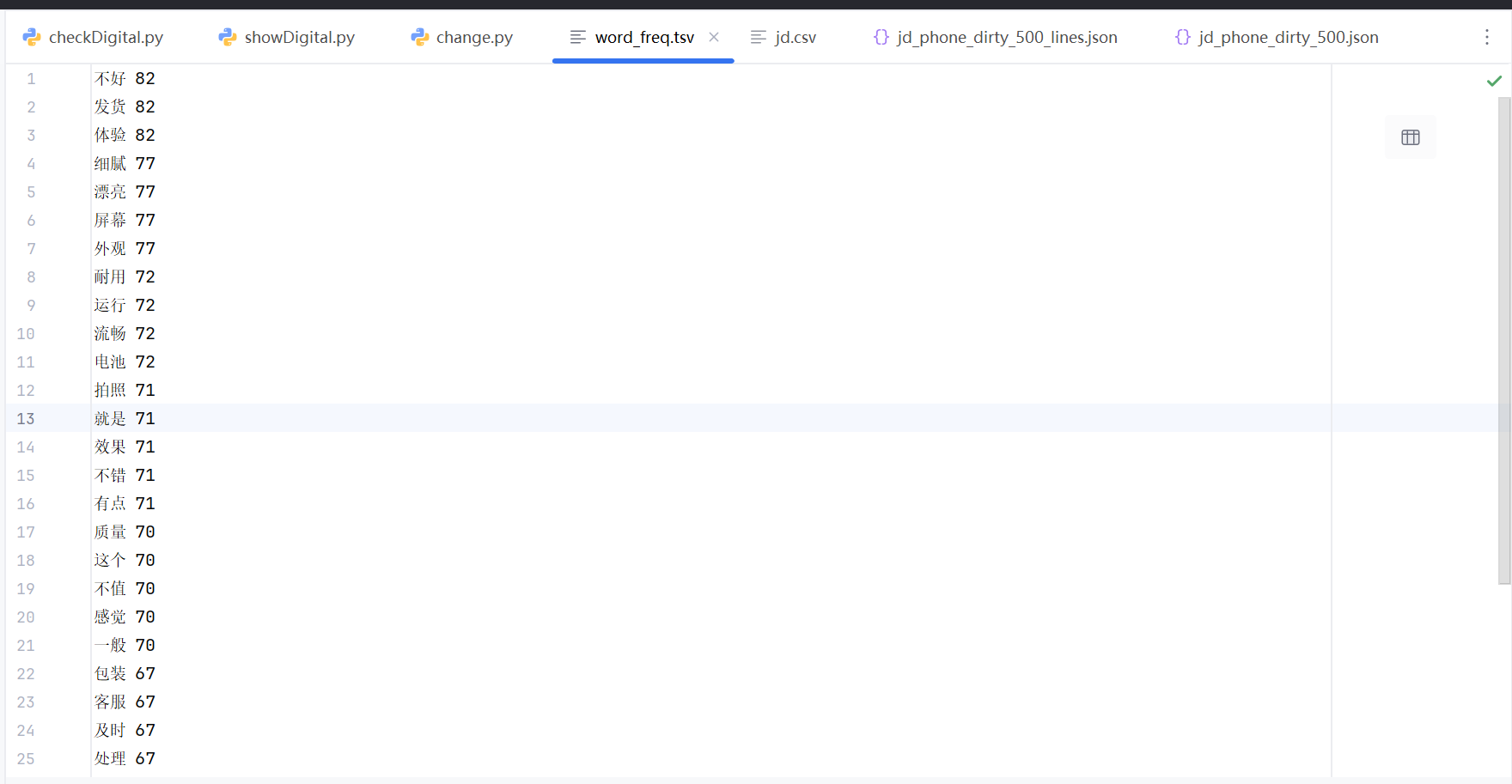
结果展示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号