
绘制板块层级图
实验名称
绘制板块层级图
实验目的
1.掌握数据文件读取
2.掌握数据处理的方法
3.实现板块层级图的绘制
实验原理
板块层级图(treemap)是一种基于面积的可视化方式,通过每一个板块(通常为矩形)的尺寸大小进行度量。外部矩形代表父类别,而内部矩形代表子类别。我们也可以通过板块层级图简单的呈现比例关系,不过它更擅于呈现树状结构的数据。读取绘图所用的数据,并对数据进行处理将数据处理成我们可以使用的形式,绘制板块层级图,设置标签和标题。
关键信息总结:
1. 板块层级图(Treemap)定义
- 基于面积的可视化方法,用矩形尺寸表示数据大小。
- 外部矩形 = 父类别,内部矩形 = 子类别。
- 擅长展示树状结构数据,也可呈现比例关系。
2. 绘图步骤
- 数据读取与处理:整理数据为适合绘图的格式(如分层结构)。
- 绘制图表:使用工具(如Python的`matplotlib`或`plotly`)生成Treemap。
- 设置标签与标题:标注父/子类别名称,添加图表标题。
3. 适用场景
- 展示层级关系(如文件目录、市场份额分类)。
- 直观比较不同类别的占比(通过矩形面积)。
实验环境
OS:Windows11
python:v3.12
实验步骤
一、安装pandas、matplotlib、seaborn、squarify#
1.输入命令:pip install pandas
2.输入命令:pip install matplotlib
3.输入命令:pip install seaborn
 4.输入命令:pip install squarify
4.输入命令:pip install squarify
二、读取数据
在这里我们使用pandas库中的read_csv函数来读取这3个数据文件。

1 import pandas as pd
2
3 # 读取CSV文件
4 products_df = pd.read_csv('C:/Users/Administrator/Downloads/products.csv')
5 aisles_df = pd.read_csv('C:/Users/Administrator/Downloads/aisles.csv')
6 departments_df = pd.read_csv('C:/Users/Administrator/Downloads/departments.csv')
7
8 # 打印每个DataFrame的前几行,以验证读取是否成功
9 print("Products DataFrame:")
10 #print(products_df.to_string(index=False))
11 print(products_df.head())
12
13 print("\nAisles DataFrame:")
14 #print(aisles_df.to_string(index=False))
15 print(aisles_df.head())
16
17 print("\nDepartments DataFrame:")
18 print(departments_df.to_string(index=False))
数据读取的结果:


三、数据处理
我们需要根据源表对目标表进行匹配查询,使用merge函数进行操作。
1 order_products_prior_df = pd.merge(products_df, aisles_df, on='aisle_id', how='left')
2 order_products_prior_df = pd.merge(order_products_prior_df, departments_df, on='department_id', how='left')
3 order_products_prior_df.head()
4 temp = order_products_prior_df[['product_name', 'aisle', 'department']]
5 temp = pd.concat([
6 order_products_prior_df.groupby('department')['product_name'].nunique().rename('products_department'),
7 order_products_prior_df.groupby('department')['aisle'].nunique().rename('aisle_department')
8 ], axis=1).reset_index()
9
10 temp = temp.set_index('department')
11 temp2 = temp.sort_values(by="aisle_department", ascending=False)
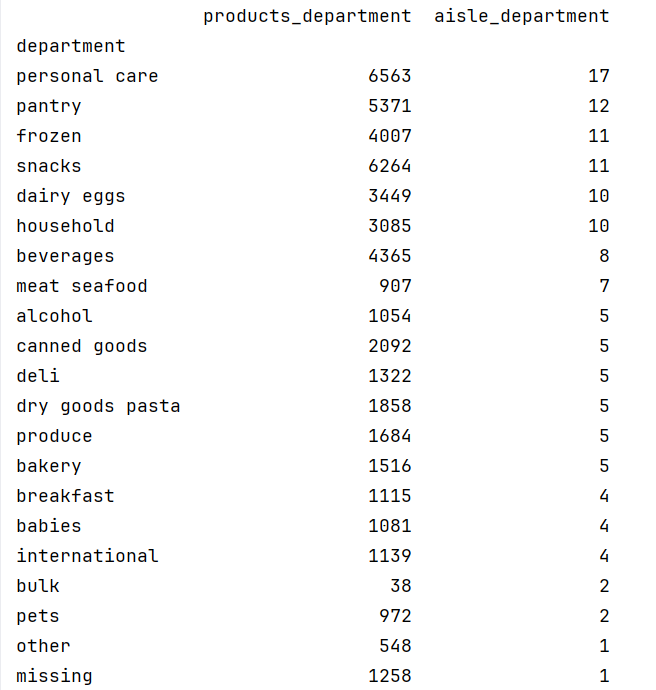
这段代码通过Pandas对多个数据表(产品、通道、部门)进行关联和聚合,最终生成一个按部门分组的统计表(`temp2`),其中包含每个部门的唯一商品数量和唯一通道数量。代码首先使用`pd.merge`将产品、通道和部门表按`aisle_id`和`department_id`左连接,确保数据完整性;随后提取关键字段(`product_name`、`aisle`、`department`),并按部门分组统计唯一值数量,生成两列指标(`products_department`和`aisle_department`)。最后,将部门设为索引并按通道数降序排序,为后续绘制板块层级图(Treemap)提供结构化数据,其中部门作为父类别,商品和通道数量分别决定矩形面积和颜色映射,直观展示层级与比例关系。
将进行匹配操作后的数据进行输出:
四、绘制板块层级图
绘制初始的板块层级图
cmap = matplotlib.cm.viridis
mini,maxi = temp2.products_department.min(),temp2.products_department.max()
norm = matplotlib.colors.Normalize(vmin=mini,vmax=maxi)
colors = [cmap(norm(value)) for value in temp2.products_department]
colors[1] = "#FBFCFE"
labels = ["%s\n%d aisle num\n%d products num"% (label) for label in
zip(temp2.index,temp2.aisle_department,temp2.products_department)]
fig = plt.figure(figsize=(20,16))
ax = fig.add_subplot(111,aspect="equal")
ax = squarify.plot(temp2.aisle_department, color=colors, label=labels, ax=ax, alpha=.7)
绘制结果如下:
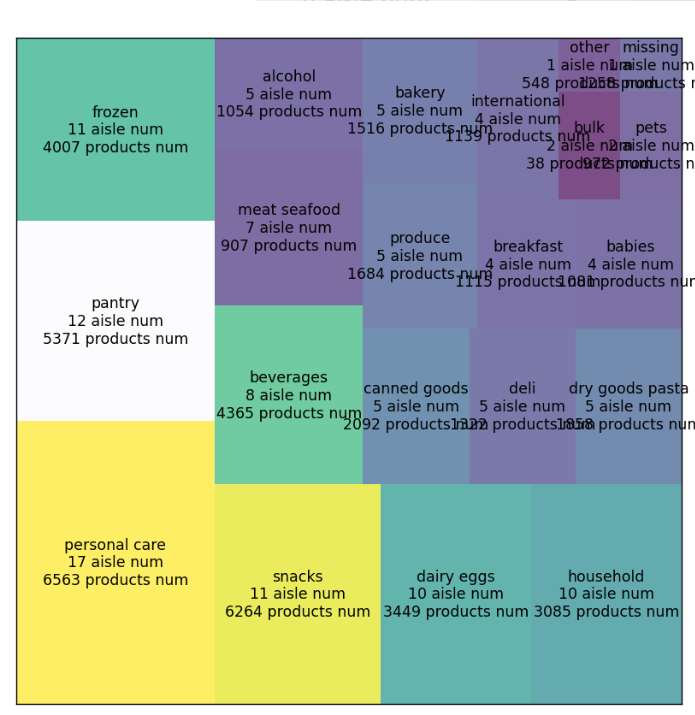
设置x,y轴的属性:
1 ax.set_xticks([]) 2 ax.set_yticks([])
添加图表标签:
1 fig.suptitle("How are aisles organized within departments",fontsize=20)
添加数据标签:
1 img = plt.imshow([temp.products_department],camp=camp) 2 img.set_visible(False) 3 fig.colorbar(img,orientation="vertical",shrink=.96) 4 fig.text(.76,.9,"numbers of products",fontsize=14)
板块层级图效果如下:
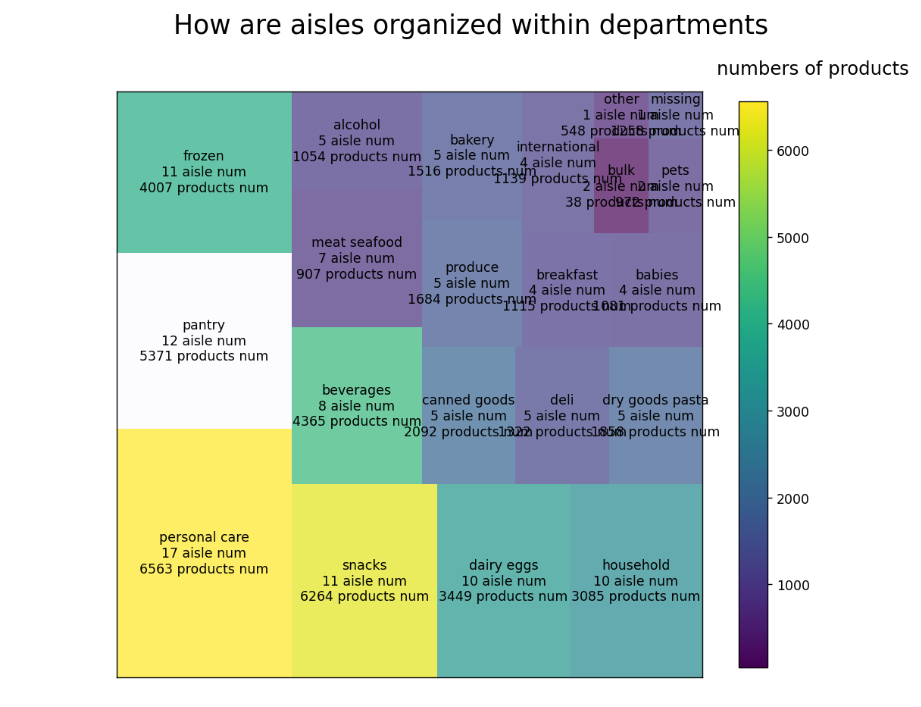
实验总结
本次"绘制板块层级图"实验让我收获颇丰,不仅掌握了数据可视化的关键技术,更深刻理解了数据分析和呈现的重要性。通过实验,我系统性地完成了从数据读取、处理到可视化呈现的完整流程,实现了商品-通道-部门层级结构的直观展示。
在实验过程中,我首先使用Pandas库成功读取并合并了三个数据表(products、aisles、departments),通过merge操作确保数据的完整性和一致性。数据处理阶段,我运用groupby和nunique方法进行分组统计,计算出每个部门的商品数量和通道数量,为后续可视化奠定了数据基础。
实验中最具挑战性的是Treemap的绘制环节。我通过squarify库实现了基于面积的层级可视化,其中:
1)矩形大小代表商品数量
2)颜色深浅反映通道多样性
3)标签清晰展示部门名称及关键指标
遇到的问题及解决方案:
1. 数据合并时出现空值:通过检查外键匹配情况,确保数据完整性
2. 颜色映射不均衡:使用matplotlib.colors.Normalize动态调整颜色范围
3. 标签重叠问题:优化标签内容和布局,提高可读性
主要收获:
1. 掌握了Pandas数据处理的核心方法(merge、groupby等)
2. 熟练使用Matplotlib和Squarify进行高级可视化
3. 理解了层级数据可视化的设计原则
4. 培养了数据分析和问题解决能力
改进方向:
1. 尝试交互式可视化工具(如Plotly)
2. 扩展更复杂的多级Treemap
3. 优化颜色方案和标签布局
4. 增加动态数据更新功能

 浙公网安备 33010602011771号
浙公网安备 33010602011771号