

绘制板块层级图
实验名称
绘制板块层级图
实验目的
1.掌握数据文件读取
2.掌握数据处理的方法
3.实现板块层级图的绘制
实验原理
1. 核心概念
树形图是一种用于展示层次结构数据的可视化工具。它通过嵌套矩形来表示数据的层级关系,每个矩形的大小与其对应的数值成比例。外部矩形代表父类别,而内部矩形代表子类别。我们也可以通过板块层级图简单的呈现比例关系,不过它更擅于呈现树状结构的数据。
树形图的主要特点包括: 层级结构:数据被组织成多个层级,每个层级的元素可以进一步细分为子素。矩形大小:每个矩形的面积与其对应的数值成正比,直观地展示了数据的大小关系。 颜色编码:颜色通常用于表示额外的维度,例如类别、数值范围或其他属性。读取绘图所用的数据,并对数据进行处理将数据处理成我们可以使用的形式绘制板块层级图,设置标签和标题。
2. 算法原理
树形图的绘制基于递归分割算法,常见的算法有: Squarified Treemap:这是最常用的算法,目标是使矩形尽可能接近正方形,以提高视觉效果。它通过递归地将矩形分割成子矩形,确保每个子矩形的长宽比尽可能接近1。 Strip Treemap:将矩形水平或垂直分割,适用于某些特定的布局需求。
实验环境
OS:Windows11
python:v3.12
实验步骤
一、安装pandas、matplotlib、seaborn、squarify
1.输入命令:pip install pandas
2.输入命令:pip install matplotlib
3.输入命令:pip install seaborn

4.输入命令:pip install squarify
二、读取数据
在这里我们使用pandas库中的read_csv函数来读取这3个数据文件。
1 import pandas as pd 2 3 # 读取CSV文件 4 products_df = pd.read_csv('C:/Users/Administrator/Downloads/products.csv') 5 aisles_df = pd.read_csv('C:/Users/Administrator/Downloads/aisles.csv') 6 departments_df = pd.read_csv('C:/Users/Administrator/Downloads/departments.csv') 7 8 # 打印每个DataFrame的前几行,以验证读取是否成功 9 print("Products DataFrame:") 10 #print(products_df.to_string(index=False)) 11 print(products_df.head()) 12 13 print("\nAisles DataFrame:") 14 #print(aisles_df.to_string(index=False)) 15 print(aisles_df.head()) 16 17 print("\nDepartments DataFrame:") 18 print(departments_df.to_string(index=False))
数据读取的结果:


三、数据处理
我们需要根据源表对目标表进行匹配查询,使用merge函数进行操作。
1 order_products_prior_df = pd.merge(products_df, aisles_df, on='aisle_id', how='left') 2 order_products_prior_df = pd.merge(order_products_prior_df, departments_df, on='department_id', how='left') 3 order_products_prior_df.head() 4 temp = order_products_prior_df[['product_name', 'aisle', 'department']] 5 temp = pd.concat([ 6 order_products_prior_df.groupby('department')['product_name'].nunique().rename('products_department'), 7 order_products_prior_df.groupby('department')['aisle'].nunique().rename('aisle_department') 8 ], axis=1).reset_index() 9 10 temp = temp.set_index('department') 11 temp2 = temp.sort_values(by="aisle_department", ascending=False)
使用pd.merge函数将products_df、aisles_df和departments_df三个数据表进行合并。 第一次合并:将products_df和aisles_df通过aisle_id进行左连接(how='left'),确保products_df中的所有记录都被保留,即使某些产品没有对应的aisle_id。 第二次合并:将上一步得到的结果order_products_prior_df与departments_df通过department_id进行左连接,确保order_products_prior_df中的所有记录都被保留,即使某些产品没有对应的department_id。order_products_prior_df包含了每个产品的名称、所属通道(aisle)和所属部门(department)。 如果某些产品没有对应的aisle_id或department_id,这些字段将被填充为NaN。
从合并后的数据框order_products_prior_df中提取product_name、aisle和department这三列。temp是一个新的数据框,只包含产品名称、通道和部门这三列信息。
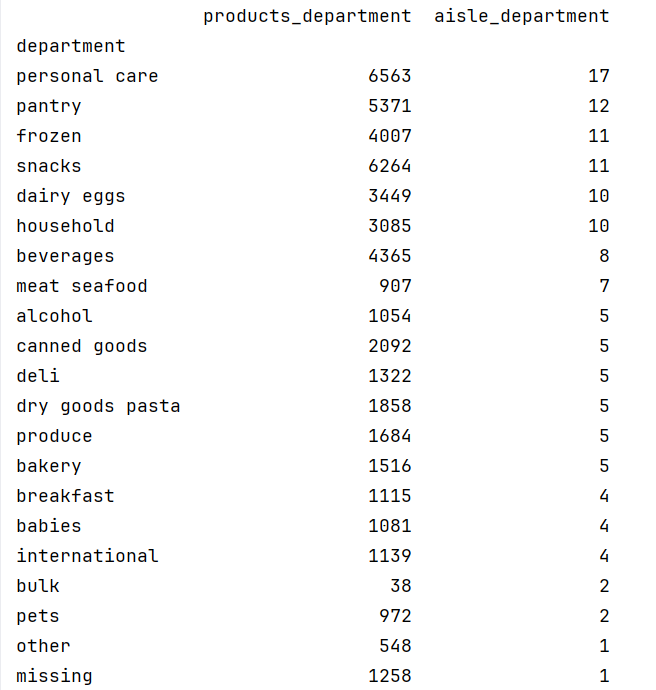
对order_products_prior_df进行分组聚合操作:按department分组,计算每个部门中独特的产品数量(product_name),并将其命名为products_department。按department分组,计算每个部门中独特的通道数量(aisle),并将其命名为aisle_department。使用pd.concat将上述两个聚合结果在列方向上合并(axis=1)。调用reset_index将分组键department从索引转换为普通列。temp是一个新的数据框,包含每个部门的产品数量(products_department)和通道数量(aisle_department)。接着,将department设置为索引。按aisle_department(通道数量)降序排序,确保通道数量最多的部门排在最前面。
将进行匹配操作后的数据进行输出:
四、绘制板块层级图
绘制初始的板块层级图
cmap = matplotlib.cm.viridis mini,maxi = temp2.products_department.min(),temp2.products_department.max() norm = matplotlib.colors.Normalize(vmin=mini,vmax=maxi) colors = [cmap(norm(value)) for value in temp2.products_department] colors[1] = "#FBFCFE" labels = ["%s\n%d aisle num\n%d products num"% (label) for label in zip(temp2.index,temp2.aisle_department,temp2.products_department)] fig = plt.figure(figsize=(20,16)) ax = fig.add_subplot(111,aspect="equal") ax = squarify.plot(temp2.aisle_department, color=colors, label=labels, ax=ax, alpha=.7)
绘制结果如下:
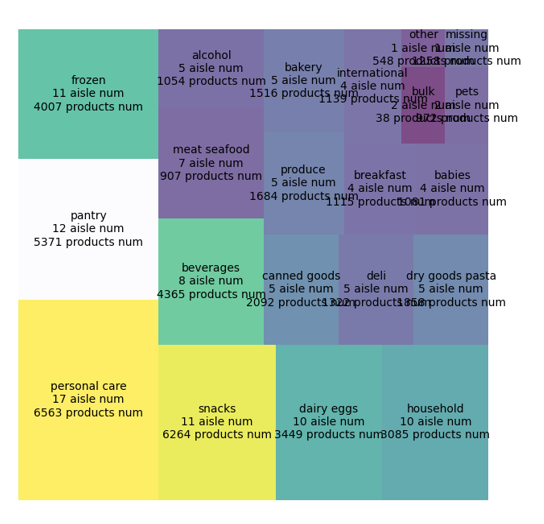
设置x,y轴的属性:
1 ax.set_xticks([]) 2 ax.set_yticks([])
添加图表标签:
1 fig.suptitle("How are aisles organized within departments",fontsize=20)
添加数据标签:
1 img = plt.imshow([temp.products_department],camp=camp) 2 img.set_visible(False) 3 fig.colorbar(img,orientation="vertical",shrink=.96) 4 fig.text(.76,.9,"numbers of products",fontsize=14)
板块层级图效果如下:
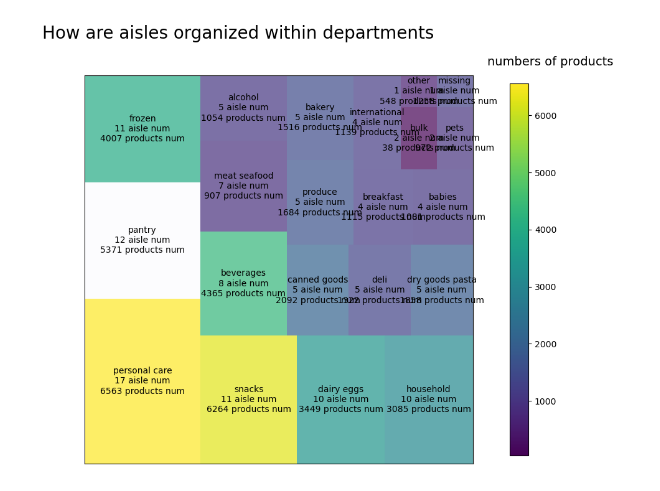
实验总结
通过本次实验,我们成功实现了从数据读取、处理到板块层级图绘制的完整流程。实验过程中,我们不仅掌握了如何使用`pandas`进行数据的读取和处理,还通过`matplotlib`和`squarify`库实现了树形图的可视化。在数据处理阶段,我们通过`pd.merge`函数完成了多个数据表的合并,并利用分组聚合操作提取了每个部门的产品数量和通道数量。这些处理步骤为后续的可视化提供了清晰的数据结构。在可视化阶段,我们使用了`viridis`颜色映射来表示产品数量,并通过树形图直观地展示了不同部门的通道和产品分布情况。通过调整颜色和标签,我们使图表更加清晰易读,能够直观地反映数据的层级关系和比例差异。
本次实验加深了我们对数据处理和可视化的理解,特别是在展示层次结构数据方面,树形图作为一种有效的可视化工具,能够清晰地呈现数据的层级关系和数值差异。通过实践,我们掌握了如何将数据转化为直观的图形信息,为后续的数据分析和决策提供了有力的支持。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号