

Learning from synthetic data: addressing domain shift for semantic segmation阅读笔记
Learning from synthetic data: addressing domain shift for semantic segmation阅读笔记
作者说之前的方法使用一种简单的对抗或者superpixel information的方式来解决domain shift。作者说ta提出了一种基于GAN的方式,来让embedding 在learned feature space更加接近。
作者给出了一张图来说明这个过程

作者的方法
让\(X \in \mathbb{R}^{M \times N \times C}\)为任意的输入图像,有\(C\)个channel,\(Y \in \mathbb{R}^{M \times N}\)是图像对应的label,给定输入\(X\),网络的输出为\(\hat{Y} \in \mathbb{R}^{M \times N \times N_{c}}\)。 其中\(N_c\)为类别,在像素位置\((i,j)\)的向量\(\hat{Y}(i, j) \in \mathbb{R}^{N_{c}}\),代表类别的概率分布。source和target用上标的\(X^s\)和\(X^t\)来表示
对于网络的描述
作者先对网络的结构进行了描述,主要包含以下几个部分
- base network,比如vgg16,可以分为两个部分,一个是embedding \(F\) 和pixel-wise classifier,用\(C\)表示,\(C\) 的输出和输入的size是一样的
- 生成网络\(G\)输入学习到的embedding,然后重建RGB图像
- 判别网络\(D\),对于一个给定的输入有两个作用,第一个作用是用一种domain consistent manner分类输入为real或者fake;第二个作用是类似于\(C\),有逐pixel分类的作用,逐pixel分类的这种效果只在source data上有用,因为target上的数据没有label
对于source和target data的对待
给定source data 和label作为输入\(\left\{X^{s}, Y^{s}\right\}\), 首先用\(F\)网络进行特征提取,然后classifier \(C\)输入embedding \(F(X^s)\)输出一个label \(\hat{Y}^{s}\). generator也会重建\(X^s\)。这个时候判别器有两个作用,第一个作用是判别real source image和generated source image,即为 soruce-real/source-fake;第二个作用就是producing pixel-wise label map of the generated source image.
不一样的是,给定一个target input \(X^t\),生成器\(G\)输入embedding (F产生),判别器来判别target-real/target-fake.
迭代优化

上图显示了作者使用的loss,表格里面显示的只有adversarial loss,除了adversarial loss之外,作者还使用了额外的两种loss
- \(\mathcal{L}_{seg}\)和\(\mathcal{L}_{aux}\),这两种loss为标准分割网络的pixel-wise交叉熵loss
- \(\mathcal{L}_{rec}\)和\(L_1\)loss,计算输入和重建图之间的距离
优化的步骤由下图表示
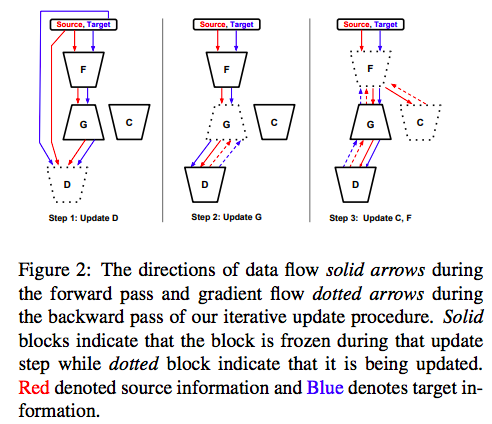
在每一次迭代的时候,都会随机的选取三元组\(\left(X^{s}, Y^{s}, X^{t}\right)\),大概是一个batch的三个元素。如上图所示,分为是哪个步骤进行更新
-
更新D:
给定source input,用within domain adversarial loss \(\mathcal{L}_{a d v, D}^{s}\),和auxiliary classification loss \(\mathcal{L}_{a u x}^{s}\)。对于target输入,只使用adversarial loss \(\mathcal{L}_{a d v, D}^{t}\)来更新,对于判别器而言,总共的loss有 \(\mathcal{L}_{D}=\mathcal{L}_{a d v, D}^{s}+\mathcal{L}_{a d v, D}^{t}+\mathcal{L}_{a u x}^{s}\)
-
更新G
在这个步骤中,G更新的主要目的是使用adversarial loss 来fool discriminator \(\mathcal{L}_{a d v, G}^{s}+\mathcal{L}_{a d v, G}^{t}\),除此之外,还有一个reconstruction loss,为\(\mathcal{L}_{r e c}\).对于G更新的adversarial loss能够使得generator生成的图片更加真实;L1 loss的存在能够对于生成前后的内容进行保真,对于generator而言,total 的loss为 \(\mathcal{L}_{G}=\mathcal{L}_{a d v, G}^{s}+\mathcal{L}_{a d v, G}^{t}+\mathcal{L}_{r e c}^{s}+\mathcal{L}_{r e c}^{t}\).
-
更新F
对F的更新是作者框架中最重要的部分,因为domain shift就在F中体现。作者用了如下loss进行更新\(\mathcal{L}_{F}=\mathcal{L}_{s e g}+\alpha \mathcal{L}_{a u x}^{s}+\beta\left(\mathcal{L}_{a d v, F}^{s}+\mathcal{L}_{a d v, F}^{t}\right)\). 这个minimax game的体现的地方是在F和G-D网络之间,原话是这么说的:
To update F, we use the gradients from D that lead to a reversal in domain classification, i.e. for source em- beddings, we use gradients from D corresponding to clas- sifying those embeddings as from target domain \(\left(\mathcal{L}_{a d v, F}^{s}\right)\) and for target embeddings, we use gradients from D cor- responding to classifying those embeddings as from source domain \(\left(\mathcal{L}_{a d v, F}^{t}\right)\).
即通过判别生成的图像来自于source domain还是target domain而不仅仅是判别其是real或者是fake。
作者总的框架如下图所示

posted on 2021-06-02 14:24 YongjieShi 阅读(238) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号