
2023-2024-1 20211211《信息安全系统设计与实现》(上)第九章学习笔记
Linux系统设计
主要内容
- 本章讨论了I/O库函数,解释了I/O库函数的作用及其相对于系统调用的优势。详细介绍I/O库函数算法,包括fread、fwrite、fclose算法。
知识点归纳目录
- I/O库函数与系统调用
- I/O库函数算法
- (1)fread算法
- (2)fwrite算法
- (3)fclose算法
- 使用I/O库函数或系统调用
- I/O库模式
- 字符模式I/O
- 行模式I/O
- 格式化I/O
- 内存中的转换函数
- 其他I/O库函数
- 限制混合fread-fwrite
- 文件流缓冲
- 变参函数
1 I/O库函数
系统调用是文件操作的基础,但它们只支持数据块的读/写。用户程序希望以最适合应用程序的逻辑单元读/写文件,如行、字符、结构化记录等,而系统调用不支持这些逻辑单元。I/O库函数则能够满足用户这一要求。
2 I/O库函数与系统调用
在Unix/Linux中,I/O库函数建立在系统调用的基础上
- 系统调用函数:open() read() write() lseek() close()
- I/O库函数:fopen() fread() fwrite() fseek() fclose()
fopen()依赖于open(),fread()依赖于read(),等等
3 I/O库函数算法
(1)fread算法
在第一次调用fread()时,FILE结构体的缓冲区是空的,fread()使用保存的文件描述符fd发出一个
n=read(fa, fbuffer,BLKSIZE);
系统调用,用数据块填充内部的fbuf[]。然后,它会初始化 fbuf[]的指针、计数器和状态变量,以表明内部缓冲区中有一个数据块。接着,通过将数据复制到程序的缓冲区,尝试满足来自内部缓冲区的fread()调用。如果内部缓冲区没有足够的数据,则会再发出一个read()系统调用来填充内部缓冲区,将数据从内部缓冲区传输到程序缓冲区,直到满足所需的字节数(或者文件无更多数据)。将数据复制到程序的缓冲区之后,它会更新内部缓冲区的指针、计数器等,为下一个fread()请求做好准备。然后,它会返回实际读取的数据对象数量。
在随后的每次fread()调用中,它都尝试满足来自FILE结构体内部缓冲区的调用。当缓冲区变为空时,它就会发出read()系统调用来重新填充内部缓冲区。因此,fread()一方面接受来自用户程序的调用,另一方面向操作系统内核发出read()系统调用。
(2)fwrite算法
fwrite()算法与fread()算法相似,只是数据传输方向不同。最开始,FILE结构体的内部缓冲区是空的。在每次调用fwrite()时,它将数据写入内部缓冲区,并调整缓冲区的指针、计数器和状态变量,以跟踪缓冲区中的字节数。如果缓冲区已满,则发出write()系统调用,将整个缓冲区写入操作系统内核。
(3)fclose算法
若文件以写的方式被打开,fclose()会先关闭文件流的局部缓冲区。然后,它会发出一个close(fd)系统调用来关闭FILE结构体中的文件描述符。最后,它会释放FILE结构体,并将FILE指针重置为NULL。
4 使用I/O库函数或系统调用
对于以BLKSIZE为单位的读/写数据,使用系统调用比I/O库函数更高效。
5 I/O库模式
open()中的模式参数可以指定为:"r"、"w"、"a",分别代表读、写、追加。
每个模式字符串可包含一个+号,表示同时读写,或者在写入、追加情况下,如果文件不存在则创建文件。
- "r+":表示读/写,不会截断文件。
- "w+":表示读/写,但是会先截断文件;如果文件不存在,会创建文件。
- "a+":表示通过追加进行读/写;如果文件不存在,会创建文件。
6 字符模式I/O
(1)字符模式I/O
int fgetc(FILE *fp); //get a char from fp, cast to int
int ungetc(int c, FILE *fp); //push a previously char got by fgetc() back to stream
int fput(int c, FILE *fp); //put a char to fp
注意,fgetc()返回的是整数,而不是字符。这是因为它必须在文件结束时返回文件结束符。文件结束符通常是一个整数-1,将它与文件流中的任何字符区分开。
对于fp=stdin或stdout,可能会使用c=getchar(); putchar(c);来代替。对于运行时效来说,getchar()和putchar()通常不是getc()和 putc()的缩小版本。相反,可以将它们实现为宏,以避免额外的函数调用。
(2)字符模式
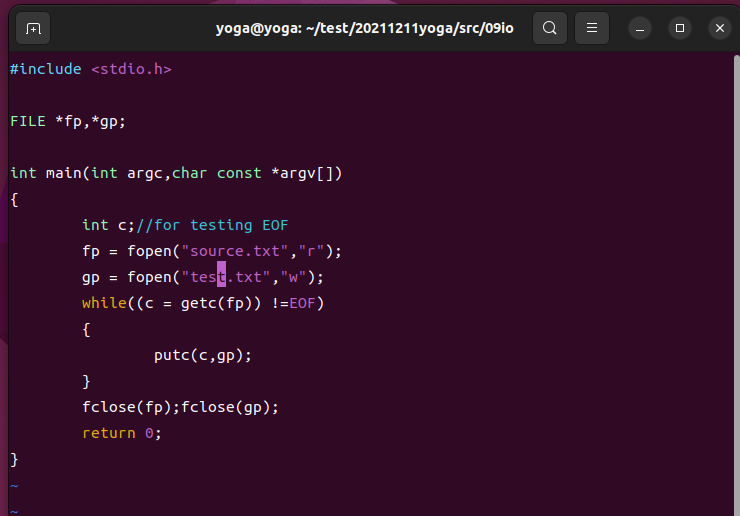
/* file copy using getc(), putc() */
#include <stdio.h>
FILE*fp,*gp;
int main(){
int c; /* for testing EoF */
fp=fopen("source.txt","r");
gp=fopen("target.txt","w");
while((c=getc(fp)) != EOF )
putc(c,gp);
fclose(fp);
fclose(gp);
}
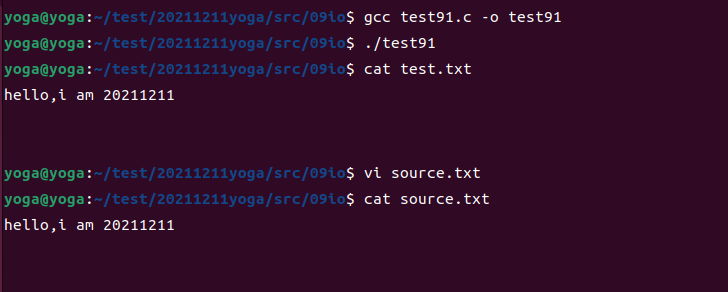
功能:读取source.txt内容,写入test.txt
(3)行模式
char *fgets(char buf, int size,FILEfp) :从fp中读取最多为一行(以\n结尾)的字符。
int fputs(char buf,FILEfp) :将buf中的一行写入fp中。
(4)格式化I/O
①格式化输入:(FMT=格式字符串)
scanf(char*FMT, &items); // from stdin
fscanf(fp,char *FMT, &items); // from file stream
7文件流缓冲
- 无缓冲
- 行缓冲
- 全缓冲
此外,还有其他的setbuf()函数,是setvbuf()的变体。对于行缓冲流或全缓冲流,可用fflush(stream)立即清除流的缓冲区。
8变参函数
目前,C语言和C++会强制执行类型检查,但这两种语言仍然允许参数数量可变的函数。这些函数必须至少使用一个参数进行声明,后跟3个点,如
int func(int m, int n ...) //n = last specified parameter
问题解决
什么是文件流缓冲
文件流缓冲是指在文件读写操作中使用的缓冲区。当我们打开一个文件时,系统会为该文件分配一个缓冲区,用于临时存储从文件读取的数据或写入到文件的数据。这个缓冲区可以提高文件读写的效率。
文件流缓冲有两种类型:全缓冲和行缓冲。全缓冲意味着数据会在缓冲区填满后才会进行实际的读写操作,而行缓冲则是在遇到换行符时进行读写操作。
缓冲区的使用可以减少实际的物理读写次数,从而提高文件的读写效率。但是,需要注意的是,如果我们需要立即将数据写入文件或者从文件读取数据,我们可以使用fflush函数来刷新缓冲区,确保数据被及时写入或读取。
苏格拉底挑战

个人收获
- 复习了vim、gcc、gdb等相关实践操作,对于linux系统的编程更为熟悉
- 重新安装了VMware,并通过增强功能和共享文件夹安装了cheat插件。
- 学习Ubuntu下git的安装使用,安装git,并实现了相关操作。
- git本地工作区域
工作区(用于编写代码)→→暂存区(临时存储)→→本地仓库(本地git仓库)
工作区→暂存区:git add . ;暂存区→本地仓库:git commit - git初始化
![]()
![]()
- 创建远程仓库
- 创建本地仓库
- 编辑本地仓库
1.git init
2.git clone - 把本地仓库推到远程仓库
![]()
![]()
- git本地工作区域



 浙公网安备 33010602011771号
浙公网安备 33010602011771号