Q-Learning,DQN
1 概念
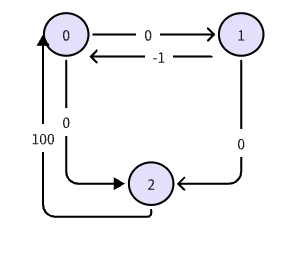 |
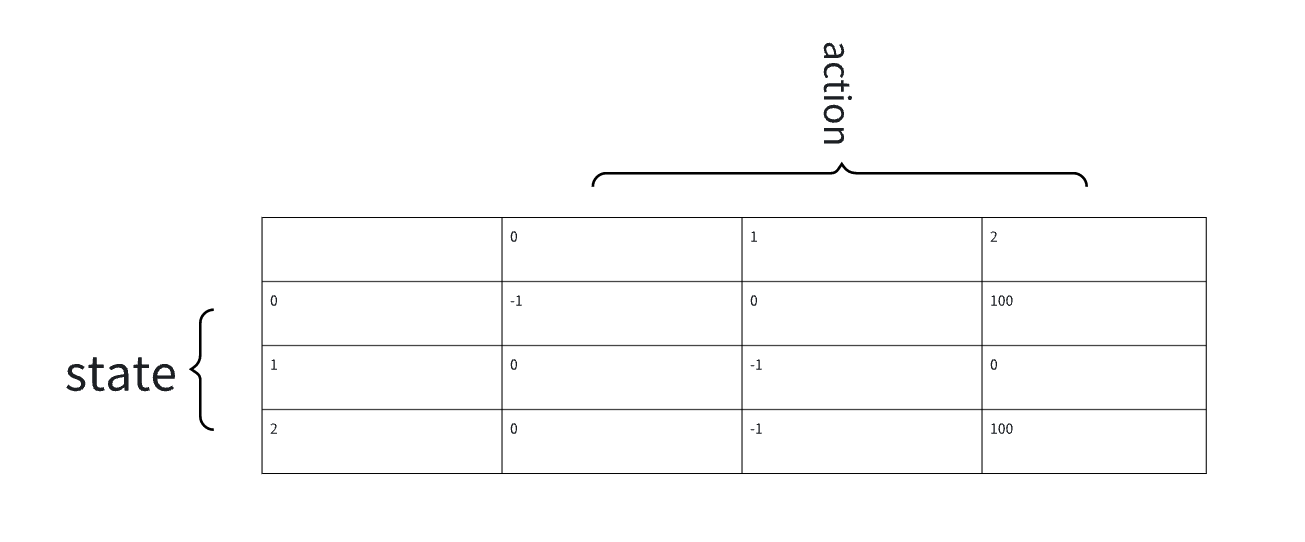 |
- state 状态
- action 行动
- reward function 奖励
- policy 策略
- discount rate 衡量当前奖励与未来奖励
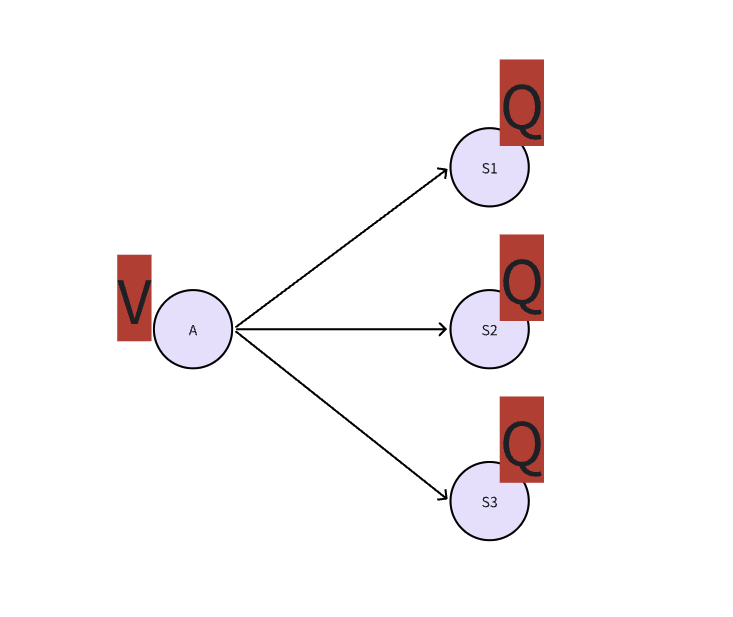
2、 Q 与 V
- 动作的价值 Q:代表智能体选择这个动作A后,一直到最终状态奖励总和的期望。告诉你在这个状态下执行某个具体动作有多好。Q,告诉你在S状态下,应该做什么动作
- 评估状态的值V,它代表了智能体在这个状态S下,一直到最终状态的奖励总和的期望。告诉你这个state好不好
一个状态的V值,就是这个状态下所有动作的Q值,在策略下的期望。
$$\displaystyle{\displaylines{V_{\pi}(S)=\sum_{A}^{}\pi(A|S)Q_{\pi}(S,A)}}$$
从V到Q当我们选择A并转移状态的时候会获得一个奖励Reward,因此要把这个R也算上。则公式如下:
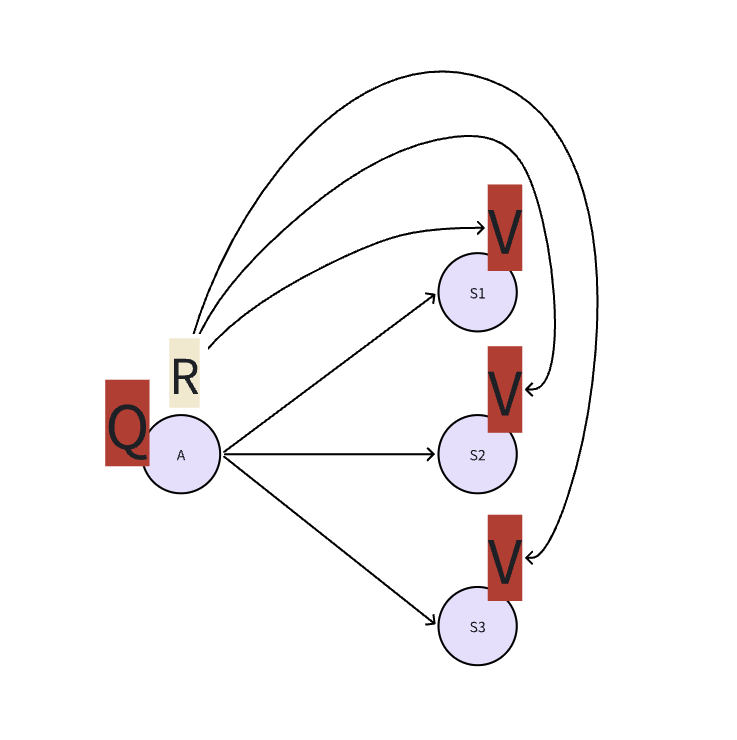
$$\displaystyle{\displaylines{Q_{\pi}(S,A)=R_{s}^{a}+\gamma\sum_{s}^{}P_{Ss}^{a}V_{\pi}(s)}}$$
3 Q值更新
Q(s,a) = Q(s,a) + α [R + γ·max_{a'} Q(s',a') - Q(s,a)]
- α 为学习率
- γ 折扣因子
- R 即时奖励
- s' 新状态max_{a'} Q(s',a'):下一个状态的最大Q值
这个公式就是用 ‘实际获得的奖励加上对未来奖励的估计’和‘当前的Q值’之间的差距,来更新Q值
伪代码
# Q-learning伪代码 初始化 Q-table(全零或随机小值) 设置参数 α, γ, ε for episode in range(num_episodes): s = 初始状态 while s不是终止状态: # 1. 选择动作(ε-greedy) if random() < ε: a = 随机动作 # 探索 else: a = argmax_a Q(s,a) # 利用 # 2. 执行动作,观察结果 执行动作a,获得奖励R和新状态s' # 3. Q值更新 TD_target = R + γ * max_{a'} Q(s',a') TD_error = TD_target - Q(s,a) Q(s,a) = Q(s,a) + α * TD_error # 4. 转移到新状态 s = s'
import numpy as np np.random.seed(42) Q = np.zeros(4) # 状态A,B,C,D的Q值(假设每个状态只有一个动作) alpha, gamma = 0.5, 0.9 reward_D = 10 # 到达D的奖励 print("=== 第一轮探索 ===") Q[2] = Q[2] + alpha * (reward_D + gamma * Q[3] - Q[2]) print(f"更新Q(C) = {Q[2]:.2f} (用Q(D)={Q[3]:.2f})") Q[1] = Q[1] + alpha * (-1 + gamma * Q[2] - Q[1]) print(f"更新Q(B) = {Q[1]:.2f} (用Q(C)={Q[2]:.2f})") Q[0] = Q[0] + alpha * (-1 + gamma * Q[1] - Q[0]) print(f"更新Q(A) = {Q[0]:.2f} (用Q(B)={Q[1]:.2f})") print(f"\n第一轮后: Q = {Q}") print("\n=== 第二轮探索 ===") old_Q_C = Q[2] Q[2] = Q[2] + alpha * (reward_D + gamma * Q[3] - Q[2]) print(f"更新Q(C): {old_Q_C:.2f} → {Q[2]:.2f}") old_Q_B = Q[1] Q[1] = Q[1] + alpha * (-1 + gamma * Q[2] - Q[1]) print(f"更新Q(B): {old_Q_B:.2f} → {Q[1]:.2f} (用更好的Q(C))") old_Q_A = Q[0] Q[0] = Q[0] + alpha * (-1 + gamma * Q[1] - Q[0]) print(f"更新Q(A): {old_Q_A:.2f} → {Q[0]:.2f} (用稍好的Q(B))")
输出
=== 第一轮探索 === 更新Q(C) = 5.00 (用Q(D)=0.00) 更新Q(B) = 1.75 (用Q(C)=5.00) 更新Q(A) = 0.29 (用Q(B)=1.75) 第一轮后: Q = [0.2875 1.75 5. 0. ] === 第二轮探索 === 更新Q(C): 5.00 → 7.50 更新Q(B): 1.75 → 3.75 (用更好的Q(C)) 更新Q(A): 0.29 → 1.33 (用稍好的Q(B))
异策略:主要目的是从非最优行为中学习最优策略,探索只是其行为策略的一部分特性。
4、DQN
如果状态空间和动作空间比较小,我们可以用Q表来存储,但是如果状态空间很大,用表格存储状体就不现实了。DQN引入了深度神经网络来近似Q值。输入是状态s,输出是每个动作对应的Q值。
4.1 经验回放机制
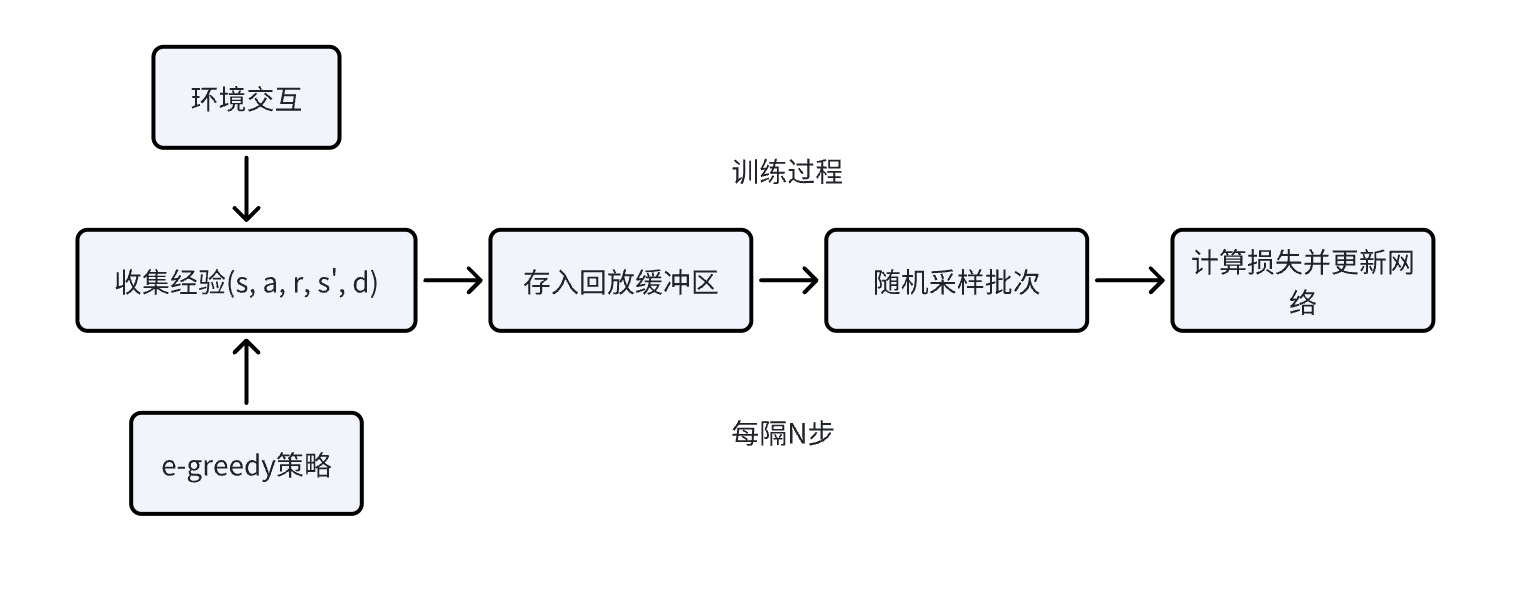
在训练过程中,智能体与环境交互产生很多的经验,这些经验可以表示为四元组 (s, a, r, s'),分别是状态、动作、奖励和下一个状态。传统的Q学习是直接用每次获得的经验来更新Q值,但这样会存在一些问题,比如前后经验可能存在很强的相关性,导致学习不稳定。而经验回放是把这些经验存储到一个经验回放池中,然后在训练神经网络的时候,从经验回放池中随机采取一批来更新网络参数。这么做的优点
- 打破了经验之间的相关性
- 同样的经验可以被多次使用
- 早起训练 e 很高,大力探索,收集多样的经验,然后随时间衰减到一个比较小的值
代码
class ReplayBuffer: def __init__(self, capacity): self.buffer = collections.deque(maxlen=capacity) # 固定大小的队列 def add(self, experience): # 添加新经验,如果缓冲区已满,自动移除最旧的经验 self.buffer.append(experience) def sample(self, batch_size): # 随机采样一批经验 indices = np.random.choice(len(self.buffer), batch_size, replace=False) batch = [self.buffer[i] for i in indices] # 将批次数据转换为适合训练的格式 states, actions, rewards, next_states, dones = zip(*batch) return np.array(states), np.array(actions), np.array(rewards), np.array(next_states), np.array(dones)
经验回放与e-greedy采样的关系:
- 观察当前状态s
- 使用e-greedy策略选择动作a执行动作a,获得(r, s', done)
- 将经验(s, a, r, s', done)存入回放缓冲区
- 从缓冲区随机采样一个批次
- 用采样的批次更新神经网络
- 定期更新目标网络
- s'->s,进入下一个时间步,继续循环
代码:
# 在一个训练循环中 for episode in range(num_episodes): state = env.reset() done = False while not done: # ========== ε-greedy 部分 ========== # 选择动作(总是使用ε-greedy) if np.random.rand() <= epsilon: action = env.action_space.sample() # 探索 else: action = np.argmax(dqn.predict(state)) # 利用 # 执行动作 next_state, reward, done, _ = env.step(action) # ========== 经验回放 部分 ========== # 1. 存储经验 replay_buffer.add(state, action, reward, next_state, done) # 2. 采样训练(如果缓冲区足够) if len(replay_buffer) > batch_size: batch = replay_buffer.sample(batch_size) dqn.train(batch) # 训练网络 # 3. 衰减ε epsilon = max(epsilon_min, epsilon * epsilon_decay) state = next_state
4.2 目标网络
目标网络是DQN算法中第二个关键创新点(第一个是经验回放),它解决了深度强化学习中的“移动目标问题”。在标准的 Q 学习更新中,我们同时使用同一个网络来计算当前 Q(s,a)值,计算目标 Q(s',a'|θ): r + γ * max_a' Q(s', a'; θ)。在一个时间步(t0->t1->t2....tn)里面,目标值在学习过程中不断变化。example,
$$\displaystyle{\displaylines{L(\theta)=\frac{1}{2}(target-Q(s,a))^{2}}}$$
谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号