attention、self-attention、attention is all you need
1 一些概念
- Query, 当前元素
- Key,序列中的其他元素
- Value,求的加权结果和
2 Attention
$$\displaystyle{\displaylines{Attention(Q,K,V)=Softmax(\frac{QK}{\sqrt{d}})V}}$$
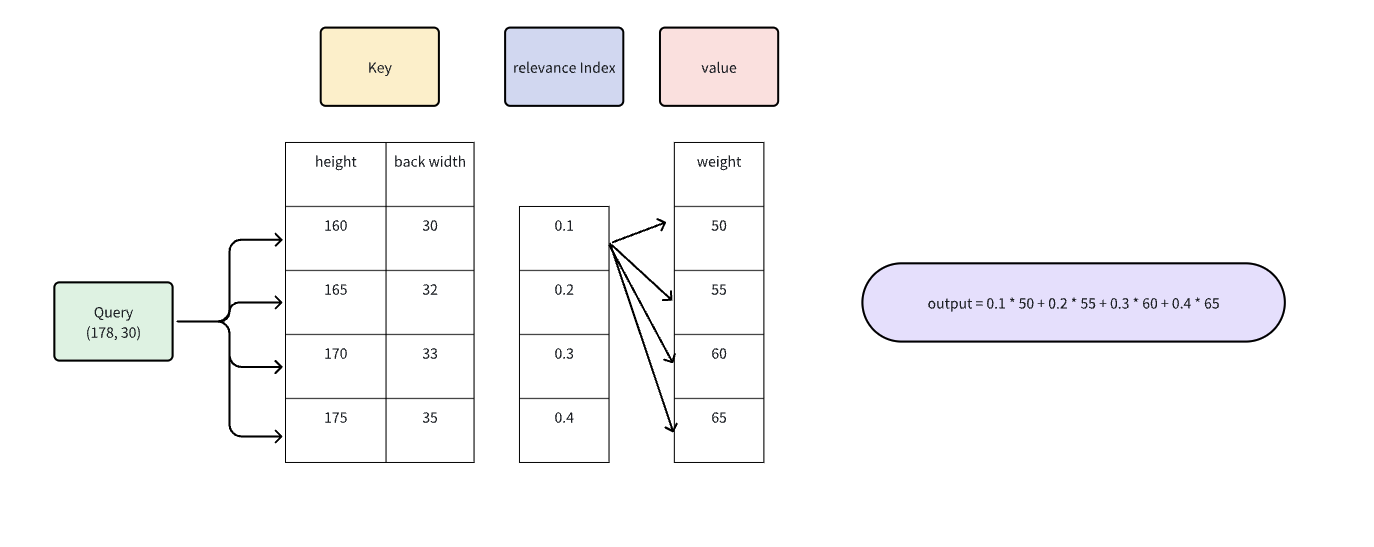
relevance index 其实就是 softmax的结果, attention weight, 代表每个dimention 应该关注其他key的程度。
3 Self-Attention
QKV都变成了自身,在这基础之上需要让QKV参与到最终结果优化的过程中,那么需要对QKV加入权重与全连接网络,让权重参与到计算与更新的过程中来。
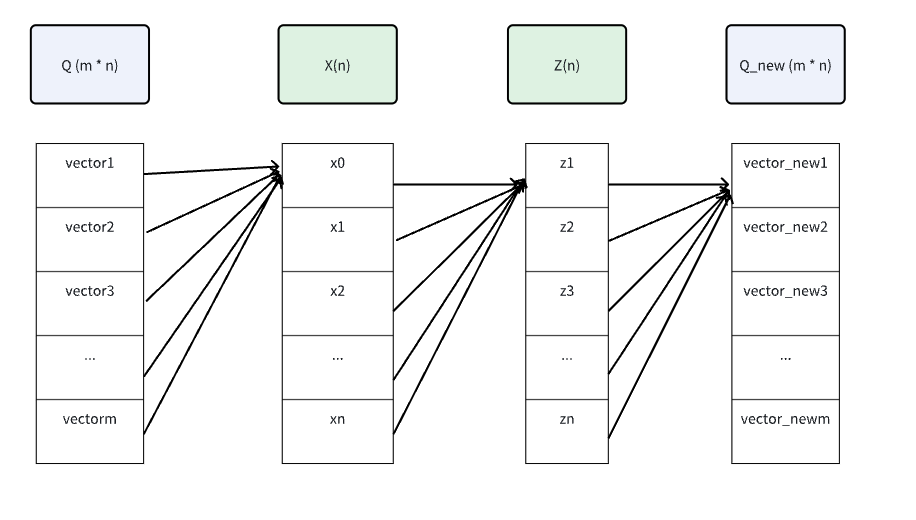
X、Z完成某种现行变换,强化需要强化的,弱化需要弱化的,对K、V进行同样的操作。
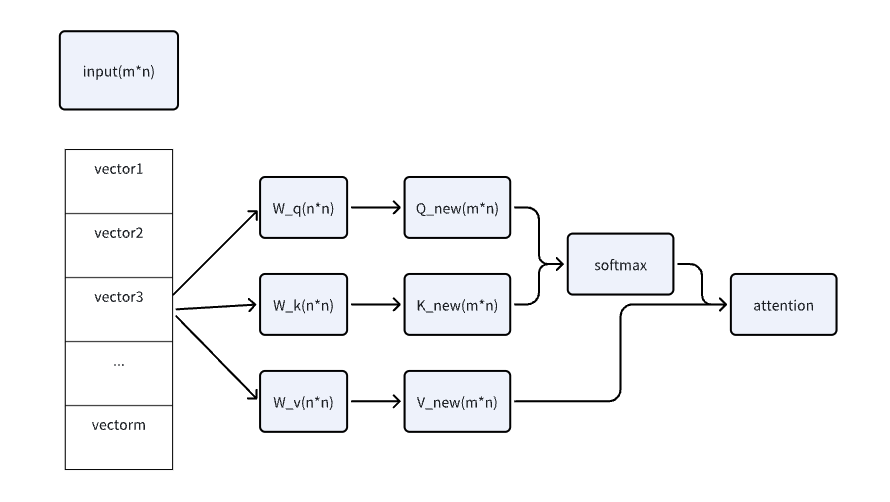
attention 也能进行叠加,相互提取信息
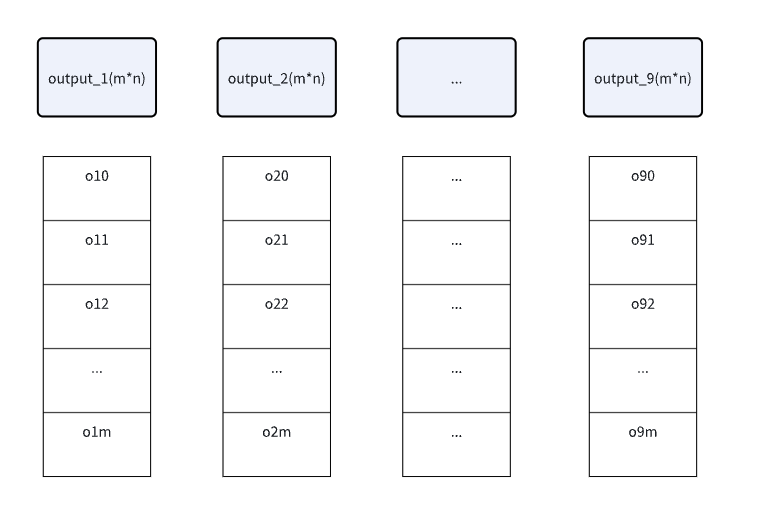
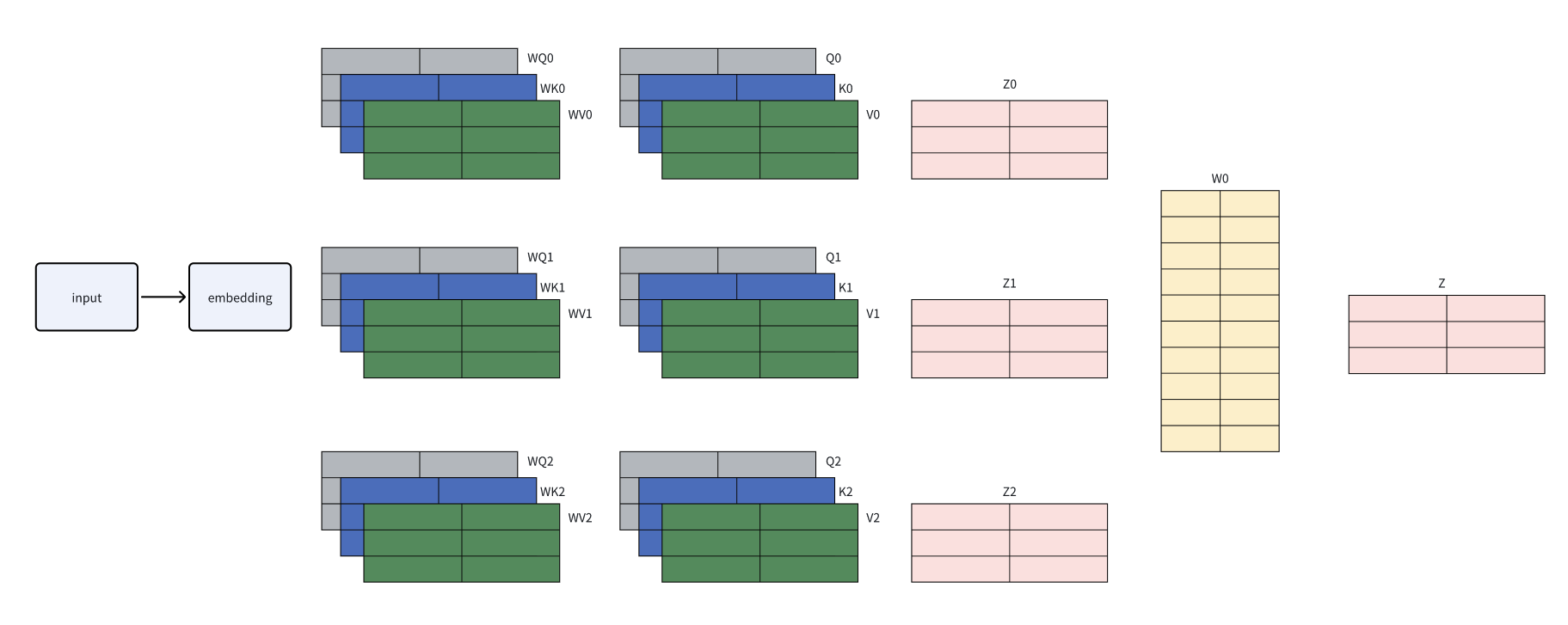
3 multi-head attention
用尽一切办法聚合任何可能的语意信息. 对于self attention, 线性变换曾的权重不变,每次不同的输入,得到的结果会侧重同样的位置权重。输入序列会被划分为若干个“头”,每个头有自己独立的 query, key, value。最后所有的头 concatenate 在一起
谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号