cluster模式问题以及解决
1.1 分布式和集群
分布式一定是集群,但是集群不一定是分布式。
单体应用:所有服务写在一个机器上。(用户、支付、物流、商品)。
分布式:各个子系统是一个服务。(拆分系统)
集群:多个实例一起工作。
分布式一定是集群,集群不一定是分布式
1.2 一致性Hash算法
HD5(加密)
普通hash算法存在的问题
- 浪费空间
- 相同内容,存不了同样的数据
改进:
1,6,7,8 对5 取余数
1)可以对数区模运算
2)开放寻址法。
如果空闲,可以向前、先后找空闲
3)拉链法
横向放不下,纵向放置链表
4)除留余数法
H = H*a + x%b
1.3 Hash算法负载均衡算法应用
应用场景
1)负载均衡(Nginx)
ip或者sessionid跟机器数区模运算,可以实现会话粘滞
分布式存书(redis)
hash(key)%3=index
1.4 一致性hash算法
1)1~2**32-1 组成一个闭合环。
2)集群ip地址求hash值hash(ip),
3)顺时针算 hash(user)最近的 hash(ip)
1.6 扩容,缩容
1)普通hash算法如果扩容,缩容 % 服务器数目的话,所有节点都要重新算,重新分配
2)一致性hash算法只影响从 服务器hash(ip1) ~ hash(ip2)之前的逆时针用户
1.7 一致性Hash虚拟节点
如果够成的Hash环分布不均匀容易有数据倾斜问题。可以用虚拟节点解决。
虚拟节点:对现有ip计算多个hash值。(好像这个hash环增加了ip一样)
2.1 时钟不同步问题
可以从前向后带时间
可以设置为处理的服务器时间
可以选一个服务器用来记录时间
数据混乱。
3.1 为什么需要分布式ID
可能导致数据重复
3.2 分布式ID生成方案 UUID
直接用java带的接口。缺点:太长,没规律
3.3 分布式ID生成方案数据库方式
去找一个数据库。有一张表,需要的时候就插入一个记录,生成一个唯一id
3.3 分布式ID生成方案雪花算法
时间戳+机器码+随机数
4.1 分布式调度问题
场景:
- 取消订单,支付退款
- 订单审核、出库
- 定时备份数据
- 离线作业
4.2 分布式调度
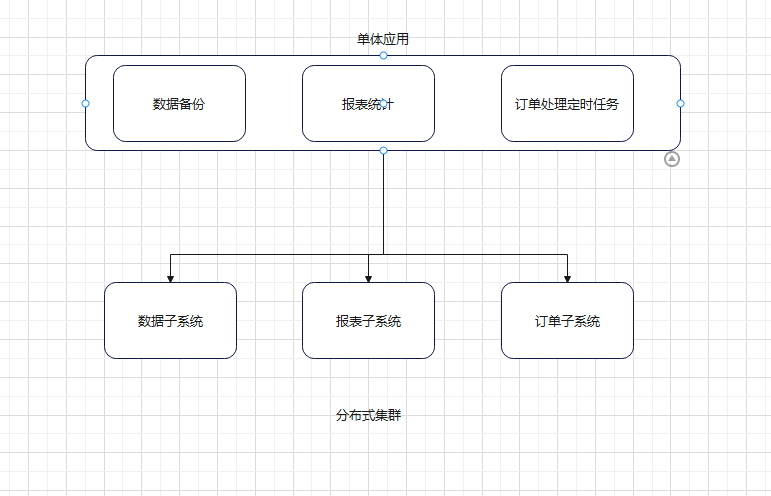
每个子系统可能有两份。同一时刻只能有一个子系统定时任务在跑。多个实例一起运行,同一个实例只能有一个,当一个实例挂了,其他实例接上来。比如(尝试,就是多个重复实例存在,单只有一个在跑)
4.3 定时任务和MQ区别
共同点
- 异步处理
- 应用解耦
- 流量消峰 (队列处理消息,一点一点。定时任务:放在数据表,定时任务扫描处理)
本质不同
- 定时任务是时间驱动、MQ是事件驱动
- 定时任务倾向于批处理,MQ倾向于逐条处理
4.4 定时任务实现方式
早期用多线程,定时执行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号