RNN,LSTM (pytorch)
在DNN中,当前输出层的值只和当前输入值有关系。如果当前输出值不仅依赖当前输入值,也依赖于前面时刻的输入值,那么DNN就不适用了。因此也就有了RNN。
一、RNN
1、RNN结构

此RNN结构一共有T个时间序列,每个时间序列的输入为x,输出为y,流向下一个循环神经细胞的隐藏层状态为a。
2、RNN CELL单元以及前向传播
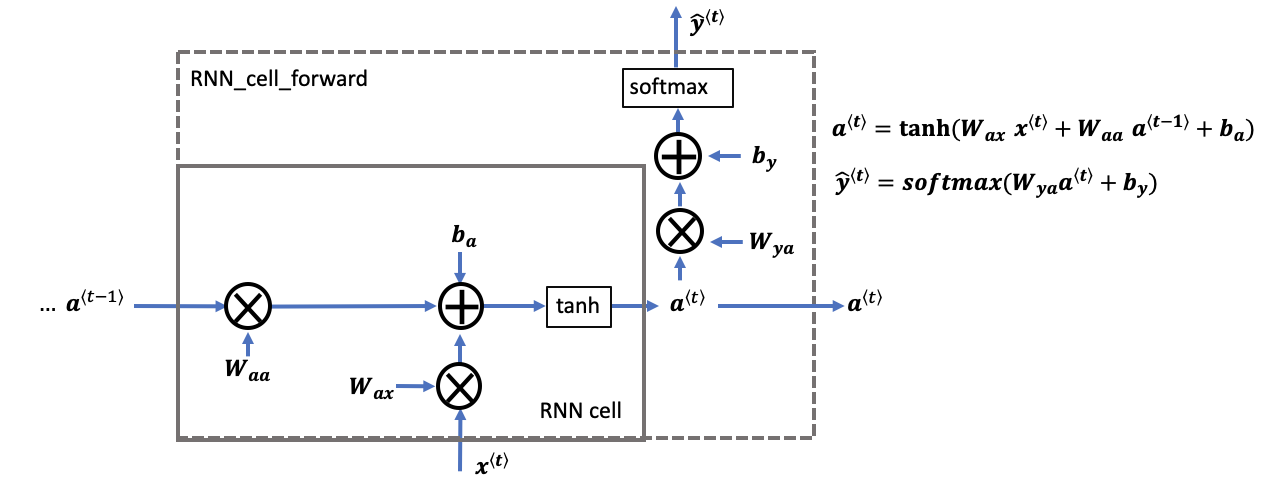
前向传播公式为上图右所示
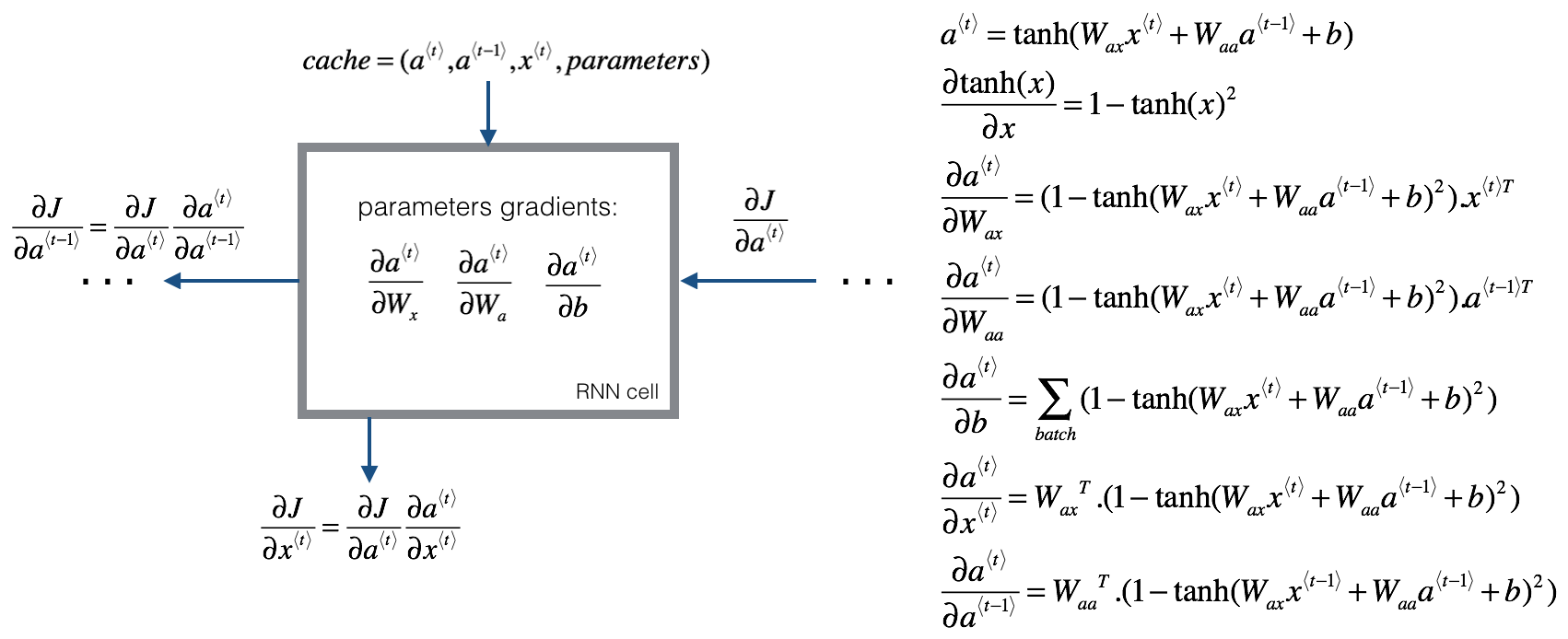
3、RNN反向传播
二、 LSTM
1、LSTM的结构

2、LSTM细胞单元

一共三个sigmoid激活函数,门控作用。两个tanh。
遗忘门(遗忘什么信息,因此使用sigmoid函数来控制,sigmoid的范围在0~1):
$$\mathbf{\Gamma}_f^{\langle t \rangle} = \sigma(\mathbf{W}_f[\mathbf{a}^{\langle t-1 \rangle}, \mathbf{x}^{\langle t \rangle}] + \mathbf{b}_f) $$
更新门(什么信息用来更新细胞状态):
$$\mathbf{\Gamma}_i^{\langle t \rangle} = \sigma(\mathbf{W}_i[a^{\langle t-1 \rangle}, \mathbf{x}^{\langle t \rangle}] + \mathbf{b}_i) $$
输出门(什么信息用来输出):
$$ \mathbf{\Gamma}_o^{\langle t \rangle}= \sigma(\mathbf{W}_o[\mathbf{a}^{\langle t-1 \rangle}, \mathbf{x}^{\langle t \rangle}] + \mathbf{b}_{o})$$
候选细胞状态
$$\mathbf{\tilde{c}}^{\langle t \rangle} = \tanh\left( \mathbf{W}_{c} [\mathbf{a}^{\langle t - 1 \rangle}, \mathbf{x}^{\langle t \rangle}] + \mathbf{b}_{c} \right) $$
最终细胞状态
$$ \mathbf{c}^{\langle t \rangle} = \mathbf{\Gamma}_f^{\langle t \rangle}* \mathbf{c}^{\langle t-1 \rangle} + \mathbf{\Gamma}_{i}^{\langle t \rangle} *\mathbf{\tilde{c}}^{\langle t \rangle} $$ (因此,根据遗忘门和更新门,不需要的信息当门控值为0或者很小时,求和的部分只取很小值,因为是求和操作,因此可以防止梯度消失)
隐藏细胞状态
$$ \mathbf{a}^{\langle t \rangle} = \mathbf{\Gamma}_o^{\langle t \rangle} * \tanh(\mathbf{c}^{\langle t \rangle})$$
输出
$$\mathbf{y}^{\langle t \rangle}_{pred} = \textrm{softmax}(\mathbf{W}_{y} \mathbf{a}^{\langle t \rangle} + \mathbf{b}_{y})$$
3、 Model
复制代码import torch import torch.nn as nn class SentimentRNN(nn.Module): def __init__(self, no_layers, vocab_size, hidden_dim, embedding_dim, output_dim, drop_prob=0.5, bidirectional=False): super(SentimentRNN, self).__init__() self.hidden_dim = hidden_dim self.no_layers = no_layers self.bidirectional = bidirectional # embedding layer self.embedding = nn.Embedding(vocab_size, embedding_dim) # LSTM self.lstm = nn.LSTM( input_size=embedding_dim, hidden_size=hidden_dim, num_layers=no_layers, batch_first=True, dropout=drop_prob if no_layers > 1 else 0, bidirectional=bidirectional ) # 计算 LSTM 输出维度 lstm_output_dim = hidden_dim * 2 if bidirectional else hidden_dim # 注意力机制(可选) self.attention = nn.Sequential( nn.Linear(lstm_output_dim, lstm_output_dim), nn.Tanh(), nn.Linear(lstm_output_dim, 1) ) # dropout self.dropout = nn.Dropout(drop_prob) # 全连接层 self.fc = nn.Linear(lstm_output_dim, output_dim) self.sig = nn.Sigmoid() def forward(self, x, hidden=None): batch_size = x.size(0) if hidden is None: hidden = self.init_hidden(batch_size) # embeddings embeds = self.dropout(self.embedding(x)) # LSTM lstm_out, hidden = self.lstm(embeds, hidden) attention_weights = self.attention(lstm_out) # (batch_size, seq_len, 1) attention_weights = torch.softmax(attention_weights, dim=1) context = torch.sum(attention_weights * lstm_out, dim=1) # (batch_size, hidden_dim) # 分类 out = self.dropout(context) out = self.fc(out) sig_out = self.sig(out) return sig_out, hidden def init_hidden(self, batch_size): device = next(self.parameters()).device num_directions = 2 if self.bidirectional else 1 h0 = torch.zeros(self.no_layers * num_directions, batch_size, self.hidden_dim).to(device) c0 = torch.zeros(self.no_layers * num_directions, batch_size, self.hidden_dim).to(device) return h0, c0
train
复制代码 @staticmethod def train(model, train_loader, valid_loader, device, batch_size): lr = 0.001 criterion = nn.BCELoss() optimizer = torch.optim.Adam(model.parameters(), lr=lr) clip = 5 epochs = 5 valid_loss_min = np.inf # train for some number of epochs epoch_tr_loss, epoch_vl_loss = [], [] epoch_tr_acc, epoch_vl_acc = [], [] for epoch in range(epochs): train_losses = [] train_acc = 0.0 model.train() # initialize hidden state h = model.init_hidden(batch_size) for inputs, labels in train_loader: inputs, labels = inputs.to(device), labels.to(device) # Creating new variables for the hidden state, otherwise # we'd backprop through the entire training history h = tuple([each.data for each in h]) model.zero_grad() output, h = model(inputs, h) # calculate the loss and perform backprop loss = criterion(output.squeeze(), labels.float()) loss.backward() train_losses.append(loss.item()) # calculating accuracy accuracy = SATaskUtil.acc(output, labels) train_acc += accuracy # `clip_grad_norm` helps prevent the exploding gradient problem in RNNs / LSTMs. nn.utils.clip_grad_norm_(model.parameters(), clip) optimizer.step() val_h = model.init_hidden(batch_size) val_losses = [] val_acc = 0.0 model.eval() for inputs, labels in valid_loader: val_h = tuple([each.data for each in val_h]) inputs, labels = inputs.to(device), labels.to(device) output, val_h = model(inputs, val_h) val_loss = criterion(output.squeeze(), labels.float()) val_losses.append(val_loss.item()) accuracy = SATaskUtil.acc(output, labels) val_acc += accuracy epoch_train_loss = np.mean(train_losses) epoch_val_loss = np.mean(val_losses) epoch_train_acc = train_acc / len(train_loader.dataset) epoch_val_acc = val_acc / len(valid_loader.dataset) epoch_tr_loss.append(epoch_train_loss) epoch_vl_loss.append(epoch_val_loss) epoch_tr_acc.append(epoch_train_acc) epoch_vl_acc.append(epoch_val_acc) print(f'Epoch {epoch + 1}') print(f'train_loss : {epoch_train_loss} val_loss : {epoch_val_loss}') print(f'train_accuracy : {epoch_train_acc * 100} val_accuracy : {epoch_val_acc * 100}') if epoch_val_loss <= valid_loss_min: torch.save(model.state_dict(), '/Users/wunan/PycharmProjects/mlstudy/kaggle/sentimentanalysis/models/state_dict.pt') print('Validation loss decreased ({:.6f} --> {:.6f}). Saving model ...'.format(valid_loss_min, epoch_val_loss)) valid_loss_min = epoch_val_loss print(25 * '==')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号