

用PyPDF2对多个pdf文件合并
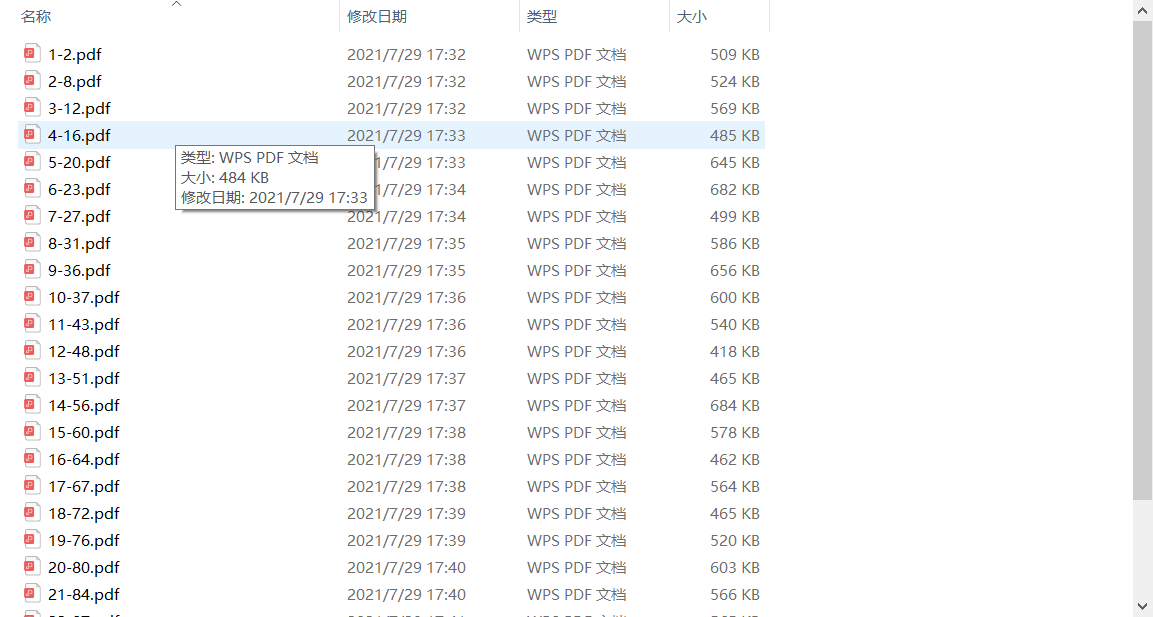
很多情况下,可能遇到下图的情况,需要合并多个pdf文件为一个。这时候就可以利用pypdf2很方便的完成。
代码非常的简单:
import glob import PyPDF2 fns=glob.glob('*.pdf') pdfWriter = PyPDF2.PdfFileWriter() totolnum=0 for fn in fns: pdfFile = open(fn,'rb') pdfReader = PyPDF2.PdfFileReader(pdfFile) pagenum=pdfReader.numPages totolnum+=pagenum for i in range(pagenum): pg=pdfReader.getPage(i) pdfWriter.addPage(pg) print('total num page is {}'.format(totolnum)) newFile = open('mergeed.PDFa','wb') #输出的文件路径和文件名,注意要把后缀的a去掉即可打开,或者保存路径与扫描路径不同 pdfWriter.write(newFile) newFile.close()
以上的代码运行,会出错,百度后发现这个错误是由于pypdf2本身所具有的,需要进行相关文的修改,从出错提示信息里可以看到有个generic.py的文件报错,打开在488行进行修改:
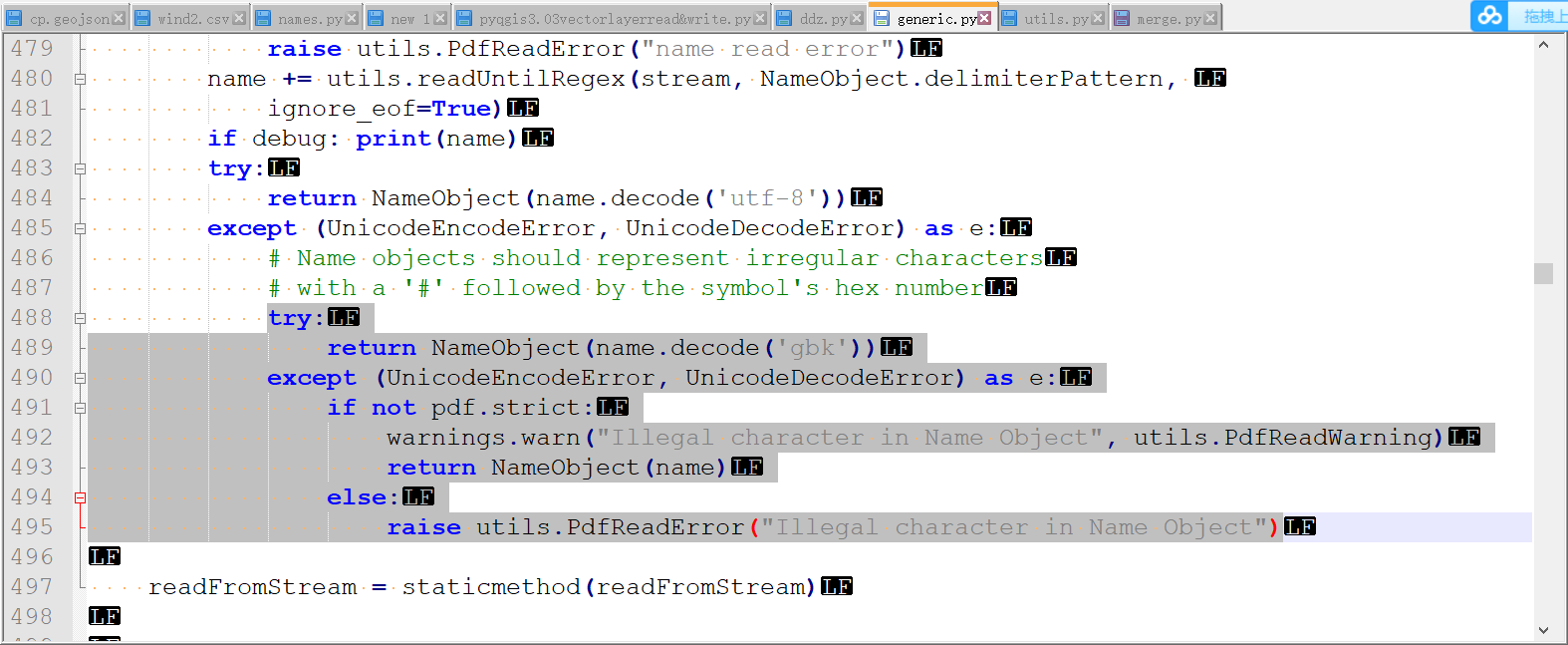
即
try: return NameObject(name.decode('gbk')) except (UnicodeEncodeError, UnicodeDecodeError) as e: if not pdf.strict: warnings.warn("Illegal character in Name Object", utils.PdfReadWarning) return NameObject(name) else: raise utils.PdfReadError("Illegal character in Name Object")
此后还需要修改utils.py的238行:
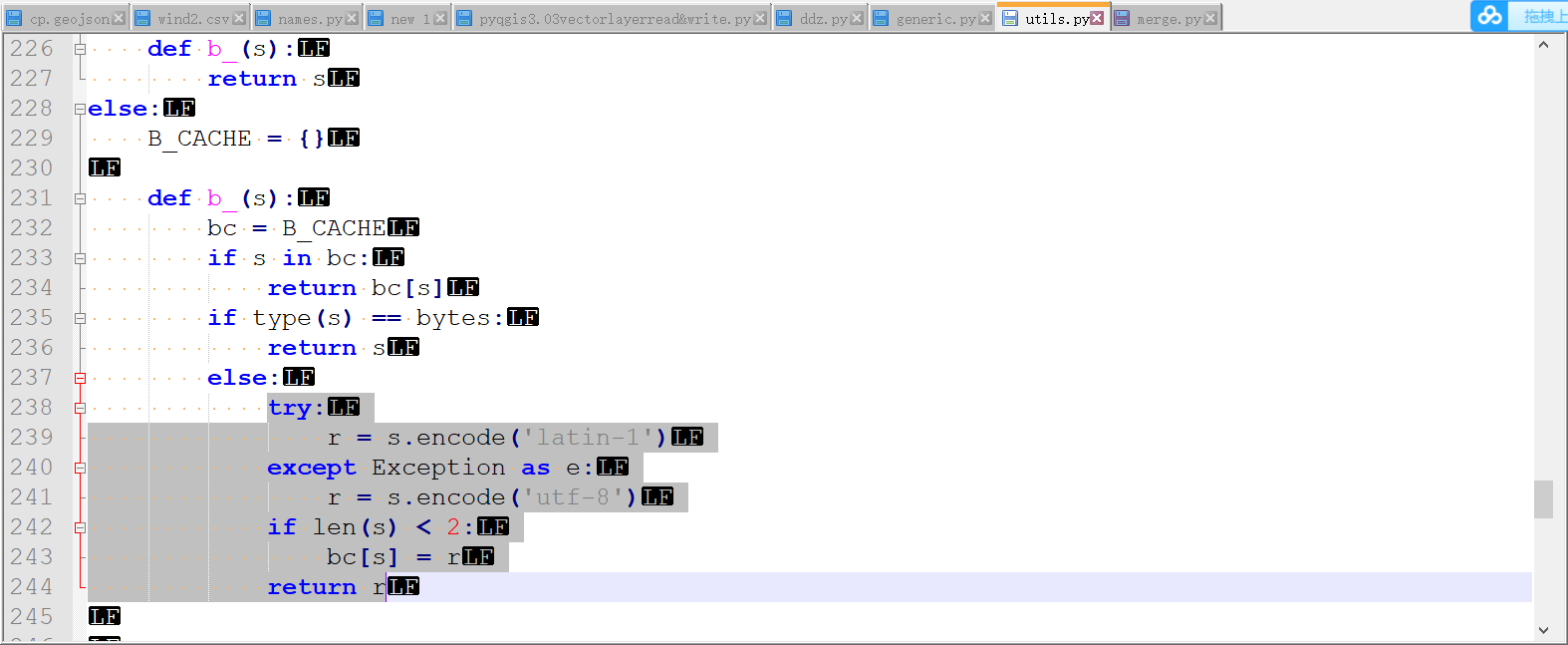
即
try: r = s.encode('latin-1') except Exception as e: r = s.encode('utf-8') if len(s) < 2: bc[s] = r return r
随后就可以正常运行了。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号