

关于目标检测的anchor问题
关于目标检测其实我一直也在想下面的两个论断:
Receptive Field Is Natural Anchor
Receptive Field Is All You Need
只是一直没有实验。但是今天有人正式提出来了:
https://github.com/becauseofAI/MobileFace
https://arxiv.org/pdf/1904.10633.pdf
用在人脸上,可以达到实时。
作者根据直觉直接说了:
Based on above understandings, faces with different sizes need various RF strategies:
•for tiny/small faces, ERFs have to cover the faces aswell as sufficient context information;
•for medium faces, ERFs only have to contain the faceswith little context information;
•for large faces, only keeping them in RFs is enough.
翻译一下:基于以上的理解,图像中不同大小的脸需要不同的感受野策略:
小的:感受野不仅需要涵盖脸本身,还需要足够的背景信息
中的:感受野需要覆盖脸本身,只需要很少的背景信息
大的:只要脸本身在感受野就足够。
这与我的体会完全一样啊,只是作者没有用到通用目标检测集中。
网络是:
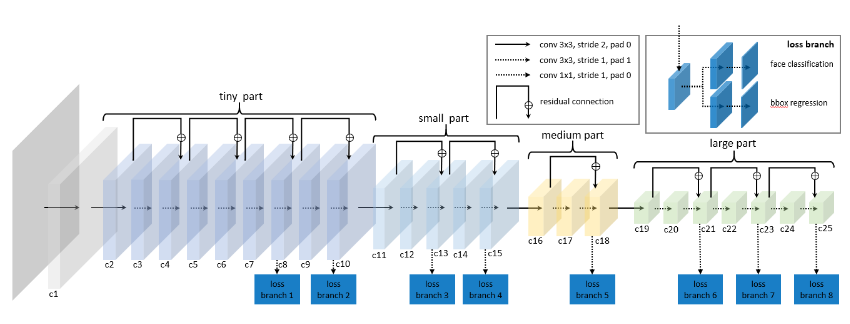
不算复杂,损失包含类别损失和边框损失。
记录一下。
是的,感受野本身就是区域内的特征信息,是没有必要再去寻找新的框,而且小目标和大目标 在图像的语义上就存在差别,小目标更多的靠形态,大目标靠内部的结构。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号