

eclipse/intellij idea 远程调试hadoop 2.6.0
 eclipse及intellij 如何远程调试hadoop 2.6.0
eclipse及intellij 如何远程调试hadoop 2.6.0
很多hadoop初学者估计都我一样,由于没有足够的机器资源,只能在虚拟机里弄一个linux安装hadoop的伪分布,然后在host机上win7里使用eclipse或Intellj idea来写代码测试,那么问题来了,win7下的eclipse或intellij idea如何远程提交map/reduce任务到远程hadoop,并断点调试?
一、准备工作
1.1 在win7中,找一个目录,解压hadoop-2.6.0,本文中是D:\yangjm\Code\study\hadoop\hadoop-2.6.0 (以下用$HADOOP_HOME表示)
1.2 在win7中添加几个环境变量
HADOOP_HOME=D:\yangjm\Code\study\hadoop\hadoop-2.6.0
HADOOP_BIN_PATH=%HADOOP_HOME%\bin
HADOOP_PREFIX=D:\yangjm\Code\study\hadoop\hadoop-2.6.0
另外,PATH变量在最后追加;%HADOOP_HOME%\bin
二、eclipse远程调试
1.1 下载hadoop-eclipse-plugin插件
hadoop-eclipse-plugin是一个专门用于eclipse的hadoop插件,可以直接在IDE环境中查看hdfs的目录和文件内容。其源代码托管于github上,官网地址是 https://github.com/winghc/hadoop2x-eclipse-plugin
有兴趣的可以自己下载源码编译,百度一下N多文章,但如果只是使用 https://github.com/winghc/hadoop2x-eclipse-plugin/tree/master/release%20 这里已经提供了各种编译好的版本,直接用就行,将下载后的hadoop-eclipse-plugin-2.6.0.jar复制到eclipse/plugins目录下,然后重启eclipse就完事了
1.2 下载windows64位平台的hadoop2.6插件包(hadoop.dll,winutils.exe)
在hadoop2.6.0源码的hadoop-common-project\hadoop-common\src\main\winutils下,有一个vs.net工程,编译这个工程可以得到这一堆文件,输出的文件中,
hadoop.dll、winutils.exe 这二个最有用,将winutils.exe复制到$HADOOP_HOME\bin目录,将hadoop.dll复制到%windir%\system32目录 (主要是防止插件报各种莫名错误,比如空对象引用啥的)
注:如果不想编译,可直接下载编译好的文件 hadoop2.6(x64)V0.2.zip
1.3 配置hadoop-eclipse-plugin插件
启动eclipse,windows->show view->other
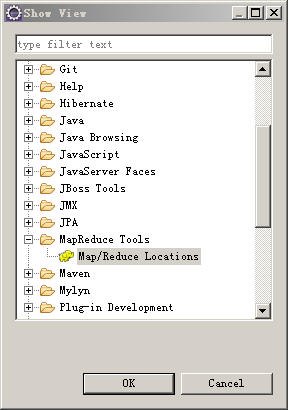
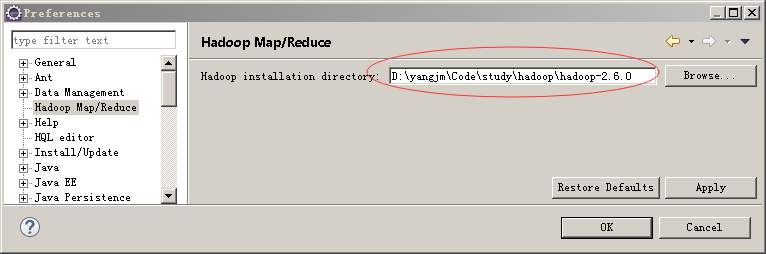
window->preferences->hadoop map/reduce 指定win7上的hadoop根目录(即:$HADOOP_HOME)
然后在Map/Reduce Locations 面板中,点击小象图标
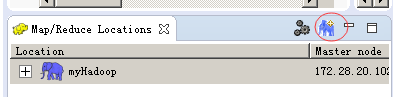
添加一个Location
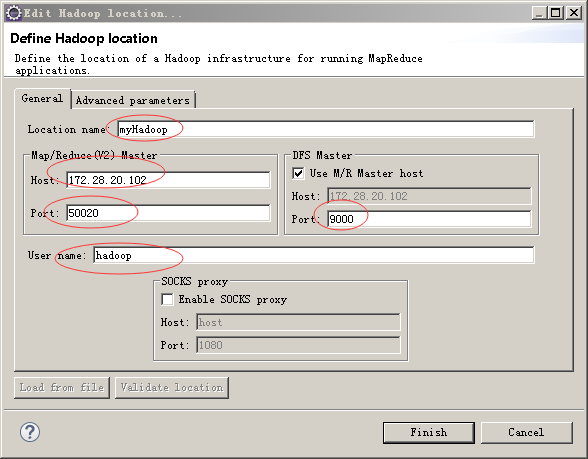
这个界面灰常重要,解释一下几个参数:
Location name 这里就是起个名字,随便起
Map/Reduce(V2) Master Host 这里就是虚拟机里hadoop master对应的IP地址,下面的端口对应 hdfs-site.xml里dfs.datanode.ipc.address属性所指定的端口
DFS Master Port: 这里的端口,对应core-site.xml里fs.defaultFS所指定的端口
最后的user name要跟虚拟机里运行hadoop的用户名一致,我是用hadoop身份安装运行hadoop 2.6.0的,所以这里填写hadoop,如果你是用root安装的,相应的改成root
这些参数指定好以后,点击Finish,eclipse就知道如何去连接hadoop了,一切顺利的话,在Project Explorer面板中,就能看到hdfs里的目录和文件了
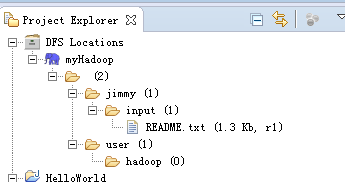
可以在文件上右击,选择删除试下,通常第一次是不成功的,会提示一堆东西,大意是权限不足之类,原因是当前的win7登录用户不是虚拟机里hadoop的运行用户,解决办法有很多,比如你可以在win7上新建一个hadoop的管理员用户,然后切换成hadoop登录win7,再使用eclipse开发,但是这样太烦,最简单的办法:
hdfs-site.xml里添加
1 <property> 2 <name>dfs.permissions</name> 3 <value>false</value> 4 </property>
然后在虚拟机里,运行hadoop dfsadmin -safemode leave
保险起见,再来一个 hadoop fs -chmod 777 /
总而言之,就是彻底把hadoop的安全检测关掉(学习阶段不需要这些,正式生产上时,不要这么干),最后重启hadoop,再到eclipse里,重复刚才的删除文件操作试下,应该可以了。
1.4 创建WoldCount示例项目
新建一个项目,选择Map/Reduce Project
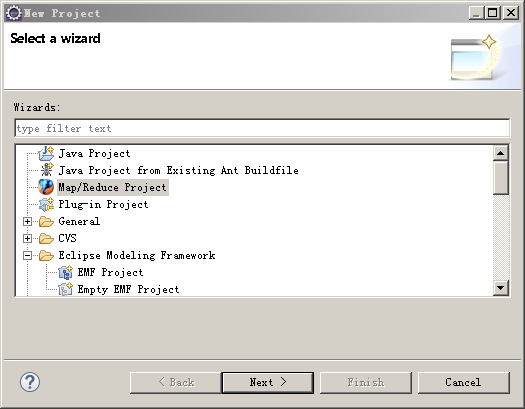
后面的Next就行了,然后放一上WodCount.java,代码如下:


1 package yjmyzz; 2 3 import java.io.IOException; 4 import java.util.StringTokenizer; 5 6 import org.apache.hadoop.conf.Configuration; 7 import org.apache.hadoop.fs.Path; 8 import org.apache.hadoop.io.IntWritable; 9 import org.apache.hadoop.io.Text; 10 import org.apache.hadoop.mapreduce.Job; 11 import org.apache.hadoop.mapreduce.Mapper; 12 import org.apache.hadoop.mapreduce.Reducer; 13 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 14 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 15 import org.apache.hadoop.util.GenericOptionsParser; 16 17 public class WordCount { 18 19 public static class TokenizerMapper 20 extends Mapper<Object, Text, Text, IntWritable> { 21 22 private final static IntWritable one = new IntWritable(1); 23 private Text word = new Text(); 24 25 public void map(Object key, Text value, Context context) throws IOException, InterruptedException { 26 StringTokenizer itr = new StringTokenizer(value.toString()); 27 while (itr.hasMoreTokens()) { 28 word.set(itr.nextToken()); 29 context.write(word, one); 30 } 31 } 32 } 33 34 public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { 35 private IntWritable result = new IntWritable(); 36 37 public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { 38 int sum = 0; 39 for (IntWritable val : values) { 40 sum += val.get(); 41 } 42 result.set(sum); 43 context.write(key, result); 44 } 45 } 46 47 public static void main(String[] args) throws Exception { 48 Configuration conf = new Configuration(); 49 String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); 50 if (otherArgs.length < 2) { 51 System.err.println("Usage: wordcount <in> [<in>...] <out>"); 52 System.exit(2); 53 } 54 Job job = Job.getInstance(conf, "word count"); 55 job.setJarByClass(WordCount.class); 56 job.setMapperClass(TokenizerMapper.class); 57 job.setCombinerClass(IntSumReducer.class); 58 job.setReducerClass(IntSumReducer.class); 59 job.setOutputKeyClass(Text.class); 60 job.setOutputValueClass(IntWritable.class); 61 for (int i = 0; i < otherArgs.length - 1; ++i) { 62 FileInputFormat.addInputPath(job, new Path(otherArgs[i])); 63 } 64 FileOutputFormat.setOutputPath(job, 65 new Path(otherArgs[otherArgs.length - 1])); 66 System.exit(job.waitForCompletion(true) ? 0 : 1); 67 } 68 }
然后再放一个log4j.properties,内容如下:(为了方便运行起来后,查看各种输出)
1 log4j.rootLogger=INFO, stdout 2 3 #log4j.logger.org.springframework=INFO 4 #log4j.logger.org.apache.activemq=INFO 5 #log4j.logger.org.apache.activemq.spring=WARN 6 #log4j.logger.org.apache.activemq.store.journal=INFO 7 #log4j.logger.org.activeio.journal=INFO 8 9 log4j.appender.stdout=org.apache.log4j.ConsoleAppender 10 log4j.appender.stdout.layout=org.apache.log4j.PatternLayout 11 log4j.appender.stdout.layout.ConversionPattern=%d{ABSOLUTE} | %-5.5p | %-16.16t | %-32.32c{1} | %-32.32C %4L | %m%n
最终的目录结构如下:
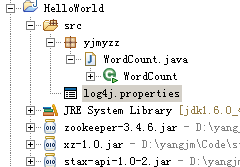
然后可以Run了,当然是不会成功的,因为没给WordCount输入参数,参考下图:
1.5 设置运行参数
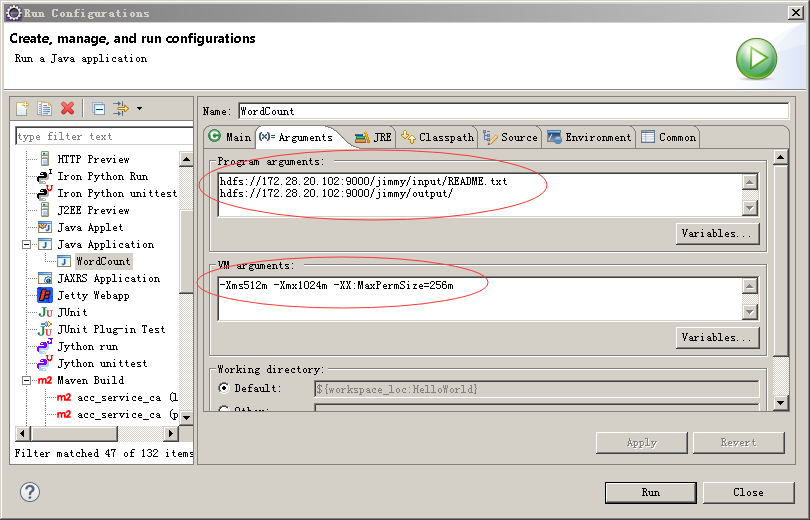
因为WordCount是输入一个文件用于统计单词字,然后输出到另一个文件夹下,所以给二个参数,参考上图,在Program arguments里,输入
hdfs://172.28.20.xxx:9000/jimmy/input/README.txt
hdfs://172.28.20.xxx:9000/jimmy/output/
大家参考这个改一下(主要是把IP换成自己虚拟机里的IP),注意的是,如果input/READM.txt文件没有,请先手动上传,然后/output/ 必须是不存在的,否则程序运行到最后,发现目标目录存在,也会报错,这个弄完后,可以在适当的位置打个断点,终于可以调试了:
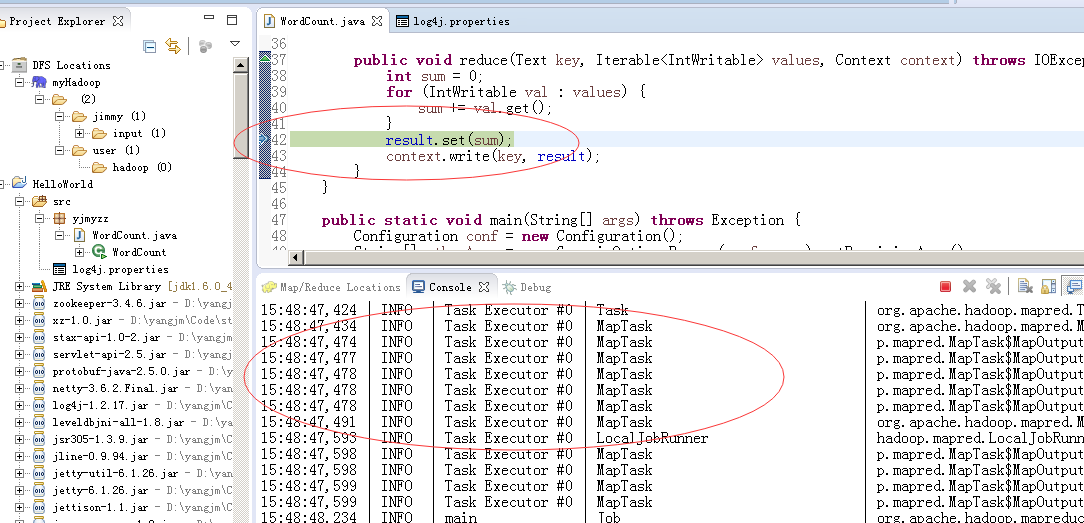
三、intellij idea 远程调试hadoop
3.1 创建一个maven的WordCount项目
pom文件如下:
1 <?xml version="1.0" encoding="UTF-8"?> 2 <project xmlns="http://maven.apache.org/POM/4.0.0" 3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 4 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> 5 <modelVersion>4.0.0</modelVersion> 6 7 <groupId>yjmyzz</groupId> 8 <artifactId>mapreduce-helloworld</artifactId> 9 <version>1.0-SNAPSHOT</version> 10 11 <dependencies> 12 <dependency> 13 <groupId>org.apache.hadoop</groupId> 14 <artifactId>hadoop-common</artifactId> 15 <version>2.6.0</version> 16 </dependency> 17 <dependency> 18 <groupId>org.apache.hadoop</groupId> 19 <artifactId>hadoop-mapreduce-client-jobclient</artifactId> 20 <version>2.6.0</version> 21 </dependency> 22 <dependency> 23 <groupId>commons-cli</groupId> 24 <artifactId>commons-cli</artifactId> 25 <version>1.2</version> 26 </dependency> 27 </dependencies> 28 29 <build> 30 <finalName>${project.artifactId}</finalName> 31 </build> 32 33 </project>
项目结构如下:
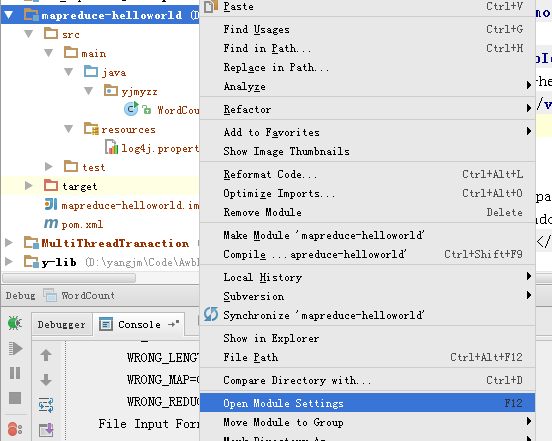
项目上右击-》Open Module Settings 或按F12,打开模块属性
添加依赖的Libary引用
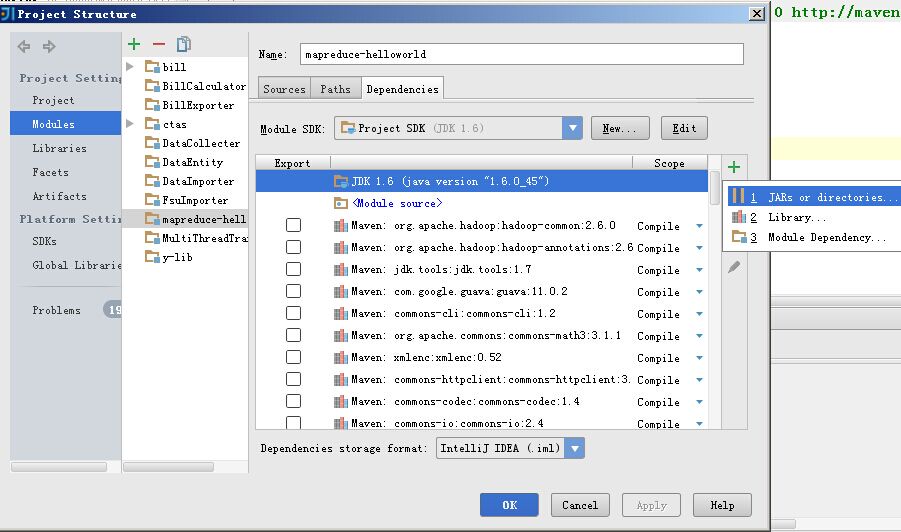
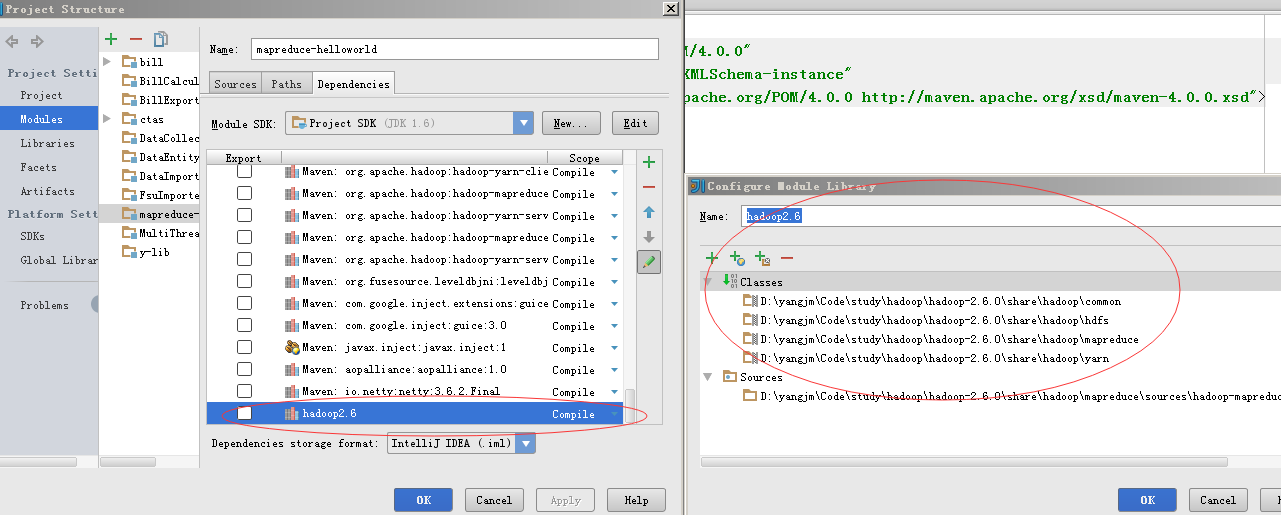
然后把$HADOOP_HOME下的对应包全导进来

导入的libary可以起个名称,比如hadoop2.6
3.2 设置运行参数
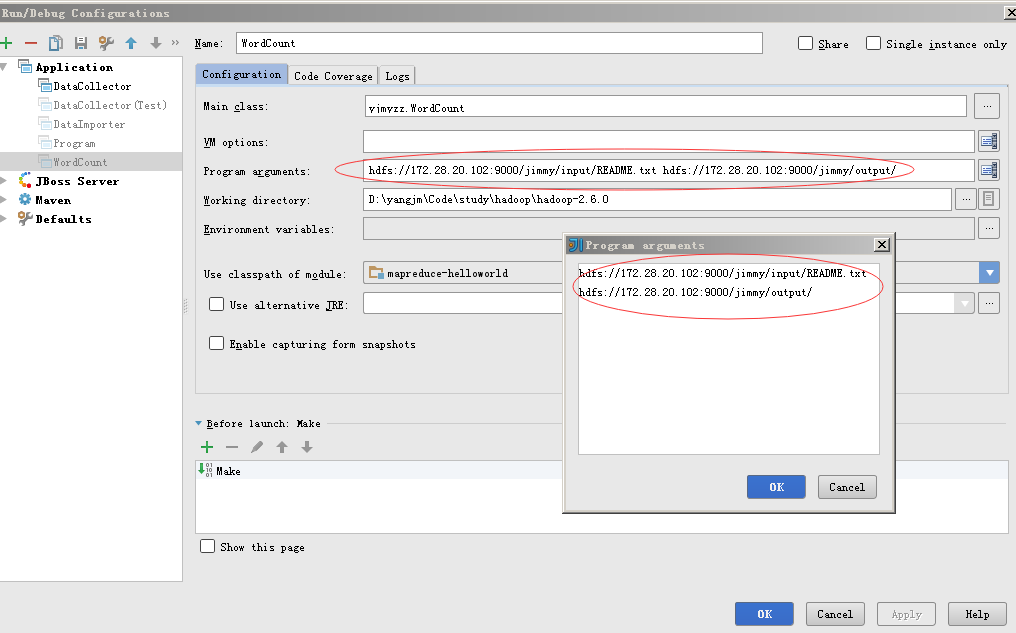
注意二个地方:
1是Program aguments,这里跟eclipes类似的做法,指定输入文件和输出文件夹
2是Working Directory,即工作目录,指定为$HADOOP_HOME所在目录
然后就可以调试了
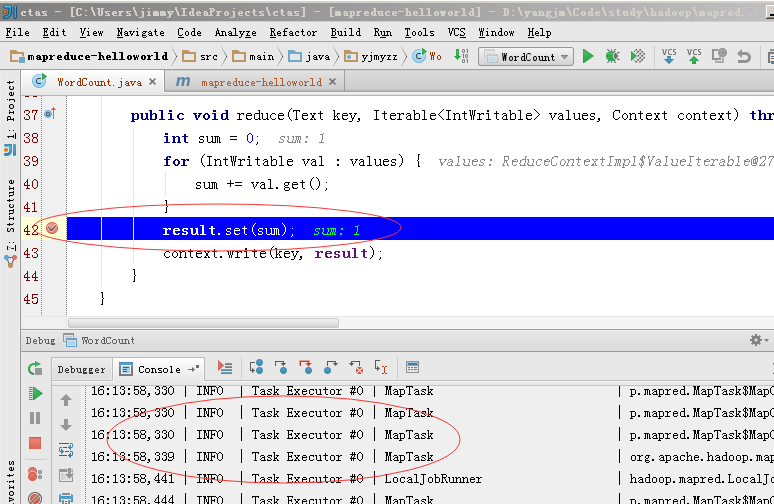
intellij下唯一不爽的,由于没有类似eclipse的hadoop插件,每次运行完wordcount,下次再要运行时,只能手动命令行删除output目录,再行调试。为了解决这个问题,可以将WordCount代码改进一下,在运行前先删除output目录,见下面的代码:
1 package yjmyzz; 2 3 import java.io.IOException; 4 import java.util.StringTokenizer; 5 6 import org.apache.hadoop.conf.Configuration; 7 import org.apache.hadoop.fs.FileSystem; 8 import org.apache.hadoop.fs.Path; 9 import org.apache.hadoop.io.IntWritable; 10 import org.apache.hadoop.io.Text; 11 import org.apache.hadoop.mapreduce.Job; 12 import org.apache.hadoop.mapreduce.Mapper; 13 import org.apache.hadoop.mapreduce.Reducer; 14 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 15 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 16 import org.apache.hadoop.util.GenericOptionsParser; 17 18 public class WordCount { 19 20 public static class TokenizerMapper 21 extends Mapper<Object, Text, Text, IntWritable> { 22 23 private final static IntWritable one = new IntWritable(1); 24 private Text word = new Text(); 25 26 public void map(Object key, Text value, Context context) throws IOException, InterruptedException { 27 StringTokenizer itr = new StringTokenizer(value.toString()); 28 while (itr.hasMoreTokens()) { 29 word.set(itr.nextToken()); 30 context.write(word, one); 31 } 32 } 33 } 34 35 public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { 36 private IntWritable result = new IntWritable(); 37 38 public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { 39 int sum = 0; 40 for (IntWritable val : values) { 41 sum += val.get(); 42 } 43 result.set(sum); 44 context.write(key, result); 45 } 46 } 47 48 49 /** 50 * 删除指定目录 51 * 52 * @param conf 53 * @param dirPath 54 * @throws IOException 55 */ 56 private static void deleteDir(Configuration conf, String dirPath) throws IOException { 57 FileSystem fs = FileSystem.get(conf); 58 Path targetPath = new Path(dirPath); 59 if (fs.exists(targetPath)) { 60 boolean delResult = fs.delete(targetPath, true); 61 if (delResult) { 62 System.out.println(targetPath + " has been deleted sucessfullly."); 63 } else { 64 System.out.println(targetPath + " deletion failed."); 65 } 66 } 67 68 } 69 70 public static void main(String[] args) throws Exception { 71 Configuration conf = new Configuration(); 72 String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); 73 if (otherArgs.length < 2) { 74 System.err.println("Usage: wordcount <in> [<in>...] <out>"); 75 System.exit(2); 76 } 77 78 //先删除output目录 79 deleteDir(conf, otherArgs[otherArgs.length - 1]); 80 81 Job job = Job.getInstance(conf, "word count"); 82 job.setJarByClass(WordCount.class); 83 job.setMapperClass(TokenizerMapper.class); 84 job.setCombinerClass(IntSumReducer.class); 85 job.setReducerClass(IntSumReducer.class); 86 job.setOutputKeyClass(Text.class); 87 job.setOutputValueClass(IntWritable.class); 88 for (int i = 0; i < otherArgs.length - 1; ++i) { 89 FileInputFormat.addInputPath(job, new Path(otherArgs[i])); 90 } 91 FileOutputFormat.setOutputPath(job, 92 new Path(otherArgs[otherArgs.length - 1])); 93 System.exit(job.waitForCompletion(true) ? 0 : 1); 94 } 95 }
但是光这样还不够,在IDE环境中运行时,IDE需要知道去连哪一个hdfs实例(就好象在db开发中,需要在配置xml中指定DataSource一样的道理),将$HADOOP_HOME\etc\hadoop下的core-site.xml,复制到resouces目录下,类似下面这样: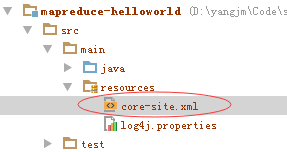
里面的内容如下:
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://172.28.20.***:9000</value> </property> </configuration>
上面的IP换成虚拟机里的IP即可
出处:http://yjmyzz.cnblogs.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号