

flink 1.11.2 学习笔记(4)-状态示例
接上节继续,今天学习Flink中状态的使用。数据处理的过程中,对当前数据的处理,有时候要依赖前一条数据的值,这种被称为“有状态”的计算。
举个例子:有这么一个公司,喜欢用内部沟通软件(类似企业微信)来做员工考勤,假设这个软件会定时上报每个员工的在线状态,如果在线(online),认为员工在上班,如果离线(offline),认为没在工作。
上报的数据结构类似:
{
"event_datetime": "2020-12-20 20:17:04.291",
"employee": "mike",
"event_timestamp": "1608466624291",
"status": "online"
}
或
{
"event_datetime": "2020-12-20 20:17:14.294",
"employee": "jerry",
"event_timestamp": "1608466634294",
"status": "offline"
}
需求:根据上报的数据,实时统计每个员工online状态与offline状态的累加时长。(注:不用太计较这个例子的合理性,只是为了说明flink中状态的用法)。
列个表格分析一下:
| 序号 | 员工 | 上报时间 | 上报状态 | 状态累加时长(ms) |
| 1 | jerry | 2020-12-20 15:31:48 | offline | offline:0 (第1条数据的时长初始值) |
| 2 | jerry | 2020-12-20 15:31:49 | offline | offline: 1000 |
| 3 | jerry | 2020-12-20 15:31:50 | online | offline:2000,online:0 (首次遇到online的时长初始值) |
| 4 | jerry | 2020-12-20 15:31:51 | online | offline: 2000,online:1000 |
假设员工jerry,连续上报了4条数据,第2条数据上报过来时,发现与第1条数据相比,状态没变,还是offline状态,所以offline的累加时长为1000ms(即:1秒),第3条数据上报过来时,变成了online,即:offline状态结束了,累加时长再加1秒,变成 2000ms,第4条数据上报过来时,相比前1条状态没变,还是online状态,认为是online状态的延续,online时长为1000ms,一直这样处理下去...。
很容易想到,每次数据处理的时候,至少需要3个辅助“变量”:
1、 记录上一条数据的状态 (用于判断本条状态是否发生了变化)
2、 记录上一条数据的上报时间 (用于计算本条数据与上条数据之间的时间差,另外也可用于判断数据是否乱序-即:先发后到)
3、 记录每种状态当前的累加时间。
这种辅助变量,在flink中就是状态, 1、2对应的是ValueState,3对应的是 MapState。
铺垫了这么多,上代码:
package com.cnblogs.yjmyzz.flink.demo;
import com.google.gson.Gson;
import com.google.gson.reflect.TypeToken;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.serialization.SerializationSchema;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.state.MapState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer010;
import org.apache.flink.util.Collector;
import org.apache.flink.util.StringUtils;
import java.text.SimpleDateFormat;
import java.util.Map;
import java.util.Properties;
/**
* @author 菩提树下的杨过(http : / / yjmyzz.cnblogs.com /)
*/
public class KafkaKeyedStateSample {
private final static Gson gson = new Gson();
private final static String SOURCE_TOPIC = "test5";
private final static String SINK_TOPIC = "test6";
private final static SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm");
public static void main(String[] args) throws Exception {
// 1 设置环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 定义数据
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("zookeeper.connect", "localhost:2181");
props.put("group.id", "test-read-group-4");
props.put("deserializer.encoding", "GB2312");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "latest");
DataStreamSource<String> text = env.addSource(new FlinkKafkaConsumer011<>(
SOURCE_TOPIC,
new SimpleStringSchema(),
props));
// 3. 处理逻辑
DataStream<Tuple2<String, Long>> counts = text.flatMap(new FlatMapFunction<String, Tuple2<String, Map<String, String>>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Map<String, String>>> out) throws Exception {
if (StringUtils.isNullOrWhitespaceOnly(value)) {
return;
}
//解析message中的json
Map<String, String> map = gson.fromJson(value, new TypeToken<Map<String, String>>() {
}.getType());
String employee = map.getOrDefault("employee", "");
out.collect(new Tuple2<>(employee, map));
}
})
.keyBy(value -> value.f0)
.flatMap(new RichFlatMapFunction<Tuple2<String, Map<String, String>>, Tuple2<String, Long>>() {
//保存最后1次上报状态的时间戳
ValueState<Long> lastTimestamp = null;
//保存最后1次的状态
ValueState<String> lastStatus = null;
//记录每个状态的持续时长累加值
MapState<String, Long> statusDuration = null;
@Override
public void open(Configuration parameters) throws Exception {
ValueStateDescriptor<Long> lastTimestampDescriptor = new ValueStateDescriptor<>("lastTimestamp", Long.class);
lastTimestamp = getRuntimeContext().getState(lastTimestampDescriptor);
ValueStateDescriptor<String> lastStatusDescriptor = new ValueStateDescriptor<>("lastStatus", String.class);
lastStatus = getRuntimeContext().getState(lastStatusDescriptor);
MapStateDescriptor<String, Long> statusDurationDescriptor = new MapStateDescriptor<>("statusDuration", String.class, Long.class);
statusDuration = getRuntimeContext().getMapState(statusDurationDescriptor);
}
@Override
public void flatMap(Tuple2<String, Map<String, String>> in, Collector<Tuple2<String, Long>> out) throws Exception {
long timestamp = Long.parseLong(in.f1.get("event_timestamp"));
String employee = in.f1.get("employee");
String empStatus = in.f1.get("status");
String collectEmpStatus = empStatus;
long duration = 0;
if (lastTimestamp == null || lastTimestamp.value() == null) {
//第1条数据
duration = 0;
} else if (timestamp > lastTimestamp.value()) { //不接受乱序数据
if (empStatus.equalsIgnoreCase(lastStatus.value())) {
//状态没变,时长累加
duration = statusDuration.get(collectEmpStatus) + (timestamp - lastTimestamp.value());
} else {
//状态变了,上次的状态时长累加
collectEmpStatus = lastStatus.value();
duration = statusDuration.get(collectEmpStatus) + (timestamp - lastTimestamp.value());
}
} else {
return;
}
lastTimestamp.update(timestamp);
lastStatus.update(empStatus);
statusDuration.put(collectEmpStatus, duration);
if (!collectEmpStatus.equalsIgnoreCase(empStatus) && !statusDuration.contains(empStatus)) {
statusDuration.put(empStatus, 0L);
}
out.collect(new Tuple2<>(employee + ":" + collectEmpStatus, duration));
}
})
.keyBy(v -> v.f0);
// 4. 打印结果
counts.addSink(new FlinkKafkaProducer010<>("localhost:9092", SINK_TOPIC,
(SerializationSchema<Tuple2<String, Long>>) element -> ("(" + element.f0 + "," + element.f1 + ")").getBytes()));
counts.print();
// execute program
env.execute("Kafka Streaming KeyedState sample");
}
}
代码看似很长,挺吓人,但是结构其实与之前几节讲的wordCount类似,头尾不用看,都是常规套路,开头从数据源拿数据,最后把计算结果输出。关键看60-126这一段处理逻辑,分为几个步骤:
1、 62-74行,解析kafka消息中的json体,考虑到会有多个员工上报状态,所以按员工名称做一个分组,方便下一步每位员工分别统计时长
2、 75行,这里注意一下,要使用状态,必须使用RichFlapMapFunction,它的第1个参数,为上一步按员工号分组后的信息;第2个参数,为处理后的输出结果。
3、 76-81行,这时定义了3个状态(即:前面提到的辅助变量)
4、 84-93行,上面定义的3个状态都没有初始化,必须在open函数里进行初始化。
5、 96-123行,就是业务处理过程(也就是实现业务需求的核心处理),注意每次处理完后,记得更新状态的值,这样下一条数据进来时,才能记住前1条数据的"状态"。另外out.collect(...) 相当于向下游输出计算结果。
测试方法:
1、 先准备4条数据:
{"event_datetime":"2020-12-20 15:31:48","employee":"jerry","event_timestamp":"1608449508304","status":"offline"}
{"event_datetime":"2020-12-20 15:31:49","employee":"jerry","event_timestamp":"1608449509304","status":"offline"}
{"event_datetime":"2020-12-20 15:31:50","employee":"jerry","event_timestamp":"1608449510304","status":"online"}
{"event_datetime":"2020-12-20 15:31:51","employee":"jerry","event_timestamp":"1608449511304","status":"online"}
{"event_datetime":"2020-12-20 15:31:52","employee":"jerry","event_timestamp":"1608449512304","status":"offline"}
2、 启动kafka,打开自带的producer控制台
./kafka-console-producer.sh --broker-list localhost:9092 --topic test5
3、 把示例代码跑起来后,在producer控制台,依次输入上面4条数据 ,观察flink的输出:
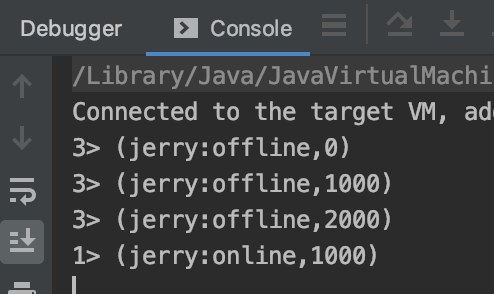
出处:http://yjmyzz.cnblogs.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号