
排序(WritableComparable)
排序(WritableComparable)
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.排序概述
排序是MapReduce框架中最重要的操作之一。
MapTask和ReduceTask均会对数据按照key进行排序。该操作属于Hadoop默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。
默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。
对于MapTask而言,它会将处理的结果暂时放到环形缓冲区中,当环形缓冲区使用达到一定阈值后,再对缓冲区的数据进行一次快速排序,并将这些有序数据溢写到磁盘上,而当数据处理完毕后,它会对磁盘上所有文件进行归并排序。
对于ReduceTask而言,它从每个MapTask上远程拷贝相应的数据,如果文件大小超过一定阈值,则溢写到磁盘上,否则存储在内存中。换句话说,如果磁盘上文件数目达到一定阈值,则进行一次归并排序以生成一个更大文件;如果内存中文件大小或者数目超过一定阈值,则进行一次合并后将数据溢写到磁盘上。当所有数据拷贝完毕后,ReduceTask统一对内存和磁盘上的所有数据进行一次归并排序。
排序分类:
部分排序:
MapReduce根据输入记录的键对数据集排序。保证输出的每个文件内部有序。
全排序:
最终输出结果只有一个文件,且文件内部有序。实现方式是只设置一个ReduceTask。但该方法在处理大型文件时效率极低,因此一台机器处理所有文件,完全丧失了MapReduce所提供的并行架构。
辅助排序(GroupingComparator):
在Reduce端对kkey进行分组。应用于在接收的key为bean对象时,想让一个或几个字段相同(全部字段比较不相同)的key进入到同一个reduce方法时,可以采用分组排序。
二次排序:
在自定义排序过程中,如果compareTo的判断条件为两个即为二次排序。
二.WritableComparable排序案例
1>.获取输入数据
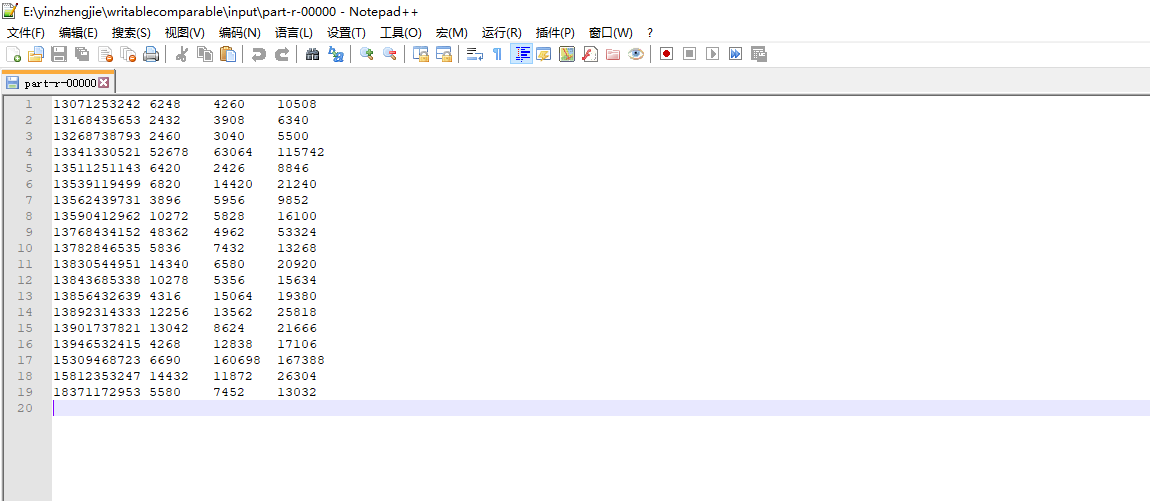
博主推荐阅读: https://www.cnblogs.com/yinzhengjie2020/p/12520516.html 经过上述笔记可以到一个未排序的结果,如下图所示。
2>.FlowBean.java代码
package cn.org.yinzhengjie.writablecomparable; import org.apache.hadoop.io.WritableComparable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; public class FlowBean implements WritableComparable<FlowBean> { private long upFlow; private long downFlow; private long sumFlow; //定义一个空参构造器,反射时会用到 public FlowBean() { } public void set(long upFlow,long downFlow){ this.upFlow = upFlow; this.downFlow = downFlow; this.sumFlow = upFlow + downFlow; } @Override public String toString() { return upFlow + "\t" + downFlow + "\t" + sumFlow; } public long getUpFlow() { return upFlow; } public void setUpFlow(long upFlow) { this.upFlow = upFlow; } public long getDownFlow() { return downFlow; } public void setDownFlow(long downFlow) { this.downFlow = downFlow; } public long getSumFlow() { return sumFlow; } public void setSumFlow(long sumFlow) { this.sumFlow = sumFlow; } /* 定义序列化方法 dataOutput: 框架给我们提供的数据出口,我们通过该对象进行数据序列化操作。 温馨提示: 注意输出时的数据类型顺序。我们写入的顺序为upFlow,downFlow,sumFlow. */ public void write(DataOutput dataOutput) throws IOException { dataOutput.writeLong(upFlow); dataOutput.writeLong(downFlow); dataOutput.writeLong(sumFlow); } /* 定义反序列化方法 dataInput: 框架给我们提供的数据来源,我们通过该对象进行数据反序列化操作。 温馨提示: 注意输入的数据类型顺序要和输出时的数据类型要一一对应,即upFlow,downFlow,sumFlow。如果你不对应可能会导致最终的结果不正确哟~ */ public void readFields(DataInput dataInput) throws IOException { upFlow = dataInput.readLong(); downFlow = dataInput.readLong(); sumFlow = dataInput.readLong(); } @Override public int compareTo(FlowBean obj) { return Long.compare(obj.sumFlow,this.sumFlow); } }
3>.SortMapper.java代码
package cn.org.yinzhengjie.writablecomparable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class SortMapper extends Mapper<LongWritable,Text,FlowBean,Text> { private FlowBean flow = new FlowBean(); private Text phone = new Text(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] fields = value.toString().split("\t"); phone.set(fields[0]); flow.setUpFlow(Long.parseLong(fields[1])); flow.setDownFlow(Long.parseLong(fields[2])); flow.setSumFlow(Long.parseLong(fields[3])); context.write(flow,phone); } }
4>.SortReducer.java代码
package cn.org.yinzhengjie.writablecomparable; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.io.Text; import java.io.IOException; public class SortReducer extends Reducer<FlowBean,Text,Text,FlowBean> { @Override protected void reduce(FlowBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException { for (Text value:values){ context.write(value,key); } } }
5>.SortDriver.java代码
package cn.org.yinzhengjie.writablecomparable; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class SortDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //获取Job实例 Job job = Job.getInstance(new Configuration()); //设置类路径 job.setJarByClass(SortDriver.class); //设置Mapper和Reducer job.setMapperClass(SortMapper.class); job.setReducerClass(SortReducer.class); //设置输入输出类型 job.setMapOutputKeyClass(FlowBean.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); //设置输入输出路径 FileInputFormat.setInputPaths(job,new Path(args[0])); FileOutputFormat.setOutputPath(job,new Path(args[1])); boolean result = job.waitForCompletion(true); //如果程序运行成功就打印"Task executed successfully!!!" if(result){ System.out.println("Task executed successfully!!!"); }else { System.out.println("Task execution failed..."); } //如果程序是正常运行就返回0,否则就返回1 System.exit(result ? 0 : 1); } }
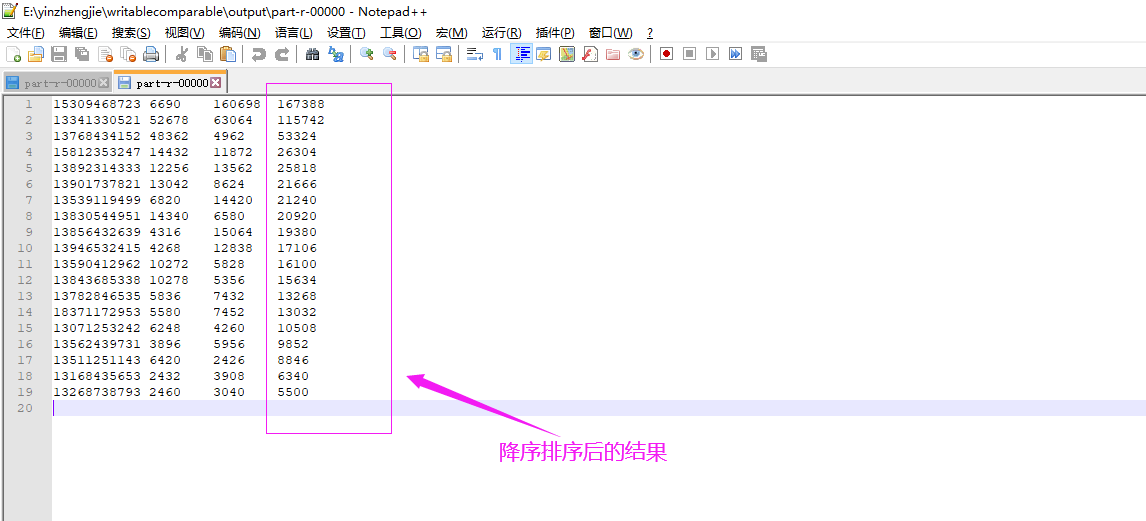
三.自定义分区并实现区内排序案例
1>.自定义分区概述
博主推荐阅读: https://www.cnblogs.com/yinzhengjie2020/p/12527426.html
2>. Mypartitioner.java文件内容
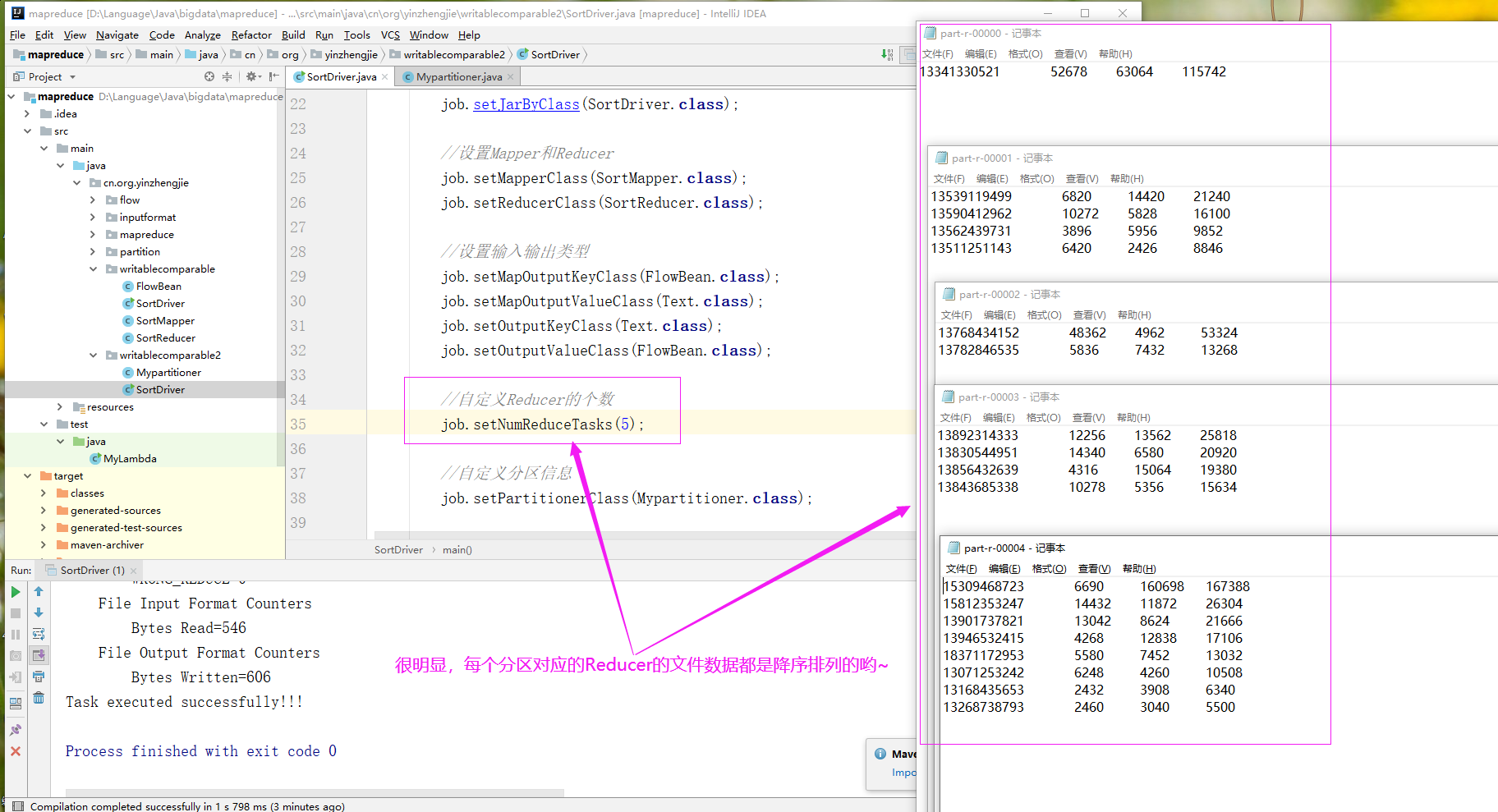
package cn.org.yinzhengjie.writablecomparable2; import cn.org.yinzhengjie.writablecomparable.FlowBean; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; public class Mypartitioner extends Partitioner<FlowBean,Text> { @Override public int getPartition(FlowBean flowBean, Text text, int numPartitions) { String phone = text.toString(); /* * 根据电话号码首字母进行不同的分区,最后根据分区编号不同个数据会进入到不同的ReduceTask哟~ */ switch (phone.substring(0,3)){ case "133": return 0; case "135": return 1; case "137": return 2; case "138" : return 3; default: return 4; } } }
3>.SortDriver.java文件内容
package cn.org.yinzhengjie.writablecomparable2; import cn.org.yinzhengjie.writablecomparable.FlowBean; import cn.org.yinzhengjie.writablecomparable.SortMapper; import cn.org.yinzhengjie.writablecomparable.SortReducer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class SortDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //获取Job实例 Job job = Job.getInstance(new Configuration()); //设置类路径 job.setJarByClass(SortDriver.class); //设置Mapper和Reducer job.setMapperClass(SortMapper.class); job.setReducerClass(SortReducer.class); //设置输入输出类型 job.setMapOutputKeyClass(FlowBean.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); //自定义Reducer的个数 job.setNumReduceTasks(5); //自定义分区信息 job.setPartitionerClass(Mypartitioner.class); //设置输入输出路径 FileInputFormat.setInputPaths(job,new Path(args[0])); FileOutputFormat.setOutputPath(job,new Path(args[1])); boolean result = job.waitForCompletion(true); //如果程序运行成功就打印"Task executed successfully!!!" if(result){ System.out.println("Task executed successfully!!!"); }else { System.out.println("Task execution failed..."); } //如果程序是正常运行就返回0,否则就返回1 System.exit(result ? 0 : 1); } }
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。 欢迎加入基础架构自动化运维:598432640,大数据SRE进阶之路:959042252,DevOps进阶之路:526991186

 浙公网安备 33010602011771号
浙公网安备 33010602011771号