【文本分类-07】ELMo
目录
- 大纲概述
- 数据集合
- 数据处理
- 预训练word2vec模型
一、大纲概述
文本分类这个系列将会有8篇左右文章,从github直接下载代码,从百度云下载训练数据,在pycharm上导入即可使用,包括基于word2vec预训练的文本分类,与及基于近几年的预训练模型(ELMo,BERT等)的文本分类。总共有以下系列:
二、数据集合
数据集为IMDB 电影影评,总共有三个数据文件,在/data/rawData目录下,包括unlabeledTrainData.tsv,labeledTrainData.tsv,testData.tsv。在进行文本分类时需要有标签的数据(labeledTrainData),但是在训练word2vec词向量模型(无监督学习)时可以将无标签的数据一起用上。
训练数据地址:链接:https://pan.baidu.com/s/1-XEwx1ai8kkGsMagIFKX_g 提取码:rtz8
ELMo模型是利用BiLM(双向语言模型)来预训练词的向量表示,可以根据我们的训练集动态的生成词的向量表示。ELMo预训练模型来源于论文:Deep contextualized word representations。具体的ELMo模型的详细介绍见这篇文章。
在使用之前我们还需要去下载已经预训练好的模型参数权重,打开https://allennlp.org/elmo链接,在Pre-trained ELMo Models 这个版块下总共有四个不同版本的模型,可以自己选择,我们在这里选择Small这个规格的模型,总共有两个文件需要下载,一个"options"的json文件,保存了模型的配置参数,另一个是"weights"的hdf5文件,保存了模型的结构和权重值(可以用h5py读取看看)。
三、主要代码
3.1 配置训练参数:parameter_config.py
在这里我们需要将optionFile,vocabFile,weightsFile,tokenEmbeddingFile的路径配置上,还有一个需要注意的地方就是这里的embeddingSize的值要和ELMo的词向量的大小一致。我们需要导入bilm文件夹中的函数和类
# Author:yifan
# _*_ coding:utf-8 _*_
#需要的所有导入包,存放留用,转换到jupyter后直接使用
# 1 配置训练参数
class TrainingConfig(object):
epoches = 5
evaluateEvery = 100
checkpointEvery = 100
learningRate = 0.001
class ModelConfig(object):
embeddingSize = 256 # 这个值是和ELMo模型的output Size 对应的值
hiddenSizes = [128] # LSTM结构的神经元个数
dropoutKeepProb = 0.5
l2RegLambda = 0.0
class Config(object):
sequenceLength = 200 # 取了所有序列长度的均值
batchSize = 128
dataSource = "../data/preProcess/labeledTrain.csv"
stopWordSource = "../data/english"
optionFile = "../data/elmodata/elmo_options.json"
weightFile = "../data/elmodata/elmo_weights.hdf5"
vocabFile = "../data/elmodata/vocab.txt"
tokenEmbeddingFile = '../data/elmodata/elmo_token_embeddings.hdf5'
numClasses = 2
rate = 0.8 # 训练集的比例
training = TrainingConfig()
model = ModelConfig()
3.2 获取训练数据:get_train_data.py
1)将数据读取出来,
2)根据训练集生成vocabFile文件,
3)调用bilm文件夹中的dump_token_embeddings方法生成初始化的词向量表示,并保存为hdf5文件,文件中的键为"embedding",
4)固定输入数据的序列长度
5)分割成训练集和测试集
# _*_ coding:utf-8 _*_
# Author:yifan
import json
from collections import Counter
import gensim
import pandas as pd
import numpy as np
import parameter_config
# 2 数据预处理的类,生成训练集和测试集
# 数据预处理的类,生成训练集和测试集
class Dataset(object):
def __init__(self, config):
self._dataSource = config.dataSource
self._stopWordSource = config.stopWordSource
self._optionFile = config.optionFile
self._weightFile = config.weightFile
self._vocabFile = config.vocabFile
self._tokenEmbeddingFile = config.tokenEmbeddingFile
self._sequenceLength = config.sequenceLength # 每条输入的序列处理为定长
self._embeddingSize = config.model.embeddingSize
self._batchSize = config.batchSize
self._rate = config.rate
self.trainReviews = []
self.trainLabels = []
self.evalReviews = []
self.evalLabels = []
def _readData(self, filePath):
"""
从csv文件中读取数据集
"""
df = pd.read_csv(filePath)
labels = df["sentiment"].tolist()
review = df["review"].tolist()
reviews = [line.strip().split() for line in review]
return reviews, labels
def _genVocabFile(self, reviews):
"""
用我们的训练数据生成一个词汇文件,并加入三个特殊字符
"""
allWords = [word for review in reviews for word in review]
wordCount = Counter(allWords) # 统计词频
sortWordCount = sorted(wordCount.items(), key=lambda x: x[1], reverse=True)
words = [item[0] for item in sortWordCount.items()]
allTokens = ['<S>', '</S>', '<UNK>'] + words
with open(self._vocabFile, 'w',encoding='UTF-8') as fout:
fout.write('\n'.join(allTokens))
def _fixedSeq(self, reviews):
"""
将长度超过200的截断为200的长度
"""
return [review[:self._sequenceLength] for review in reviews]
def _genElmoEmbedding(self):
"""
调用ELMO源码中的dump_token_embeddings方法,基于字符的表示生成词的向量表示。并保存成hdf5文件,
文件中的"embedding"键对应的value就是
词汇表文件中各词汇的向量表示,这些词汇的向量表示之后会作为BiLM的初始化输入。
"""
dump_token_embeddings(
self._vocabFile, self._optionFile, self._weightFile, self._tokenEmbeddingFile)
def _genTrainEvalData(self, x, y, rate):
"""
生成训练集和验证集
"""
y = [[item] for item in y]
trainIndex = int(len(x) * rate)
trainReviews = x[:trainIndex]
trainLabels = y[:trainIndex]
evalReviews = x[trainIndex:]
evalLabels = y[trainIndex:]
return trainReviews, trainLabels, evalReviews, evalLabels
def dataGen(self):
"""
初始化训练集和验证集
"""
# 初始化数据集
reviews, labels = self._readData(self._dataSource)
# self._genVocabFile(reviews) # 生成vocabFile
# self._genElmoEmbedding() # 生成elmo_token_embedding
reviews = self._fixedSeq(reviews)
# 初始化训练集和测试集
trainReviews, trainLabels, evalReviews, evalLabels = self._genTrainEvalData(reviews, labels, self._rate)
self.trainReviews = trainReviews
self.trainLabels = trainLabels
self.evalReviews = evalReviews
self.evalLabels = evalLabels
3.3 模型构建:mode_structure.py
# Author:yifan
# _*_ coding:utf-8 _*_
import tensorflow as tf
import parameter_config
config = parameter_config.Config()
# 构建模型 3 ELMo模型
# 构建模型
class ELMo(object):
""""""
def __init__(self, config):
# 定义模型的输入
self.inputX = tf.placeholder(tf.float32, [None, config.sequenceLength, config.model.embeddingSize], name="inputX")
self.inputY = tf.placeholder(tf.float32, [None, 1], name="inputY")
self.dropoutKeepProb = tf.placeholder(tf.float32, name="dropoutKeepProb")
# 定义l2损失
l2Loss = tf.constant(0.0)
with tf.name_scope("embedding"):
embeddingW = tf.get_variable(
"embeddingW",
shape=[config.model.embeddingSize, config.model.embeddingSize],
initializer=tf.contrib.layers.xavier_initializer())
reshapeInputX = tf.reshape(self.inputX, shape=[-1, config.model.embeddingSize])
self.embeddedWords = tf.reshape(tf.matmul(reshapeInputX, embeddingW), shape=[-1, config.sequenceLength, config.model.embeddingSize])
self.embeddedWords = tf.nn.dropout(self.embeddedWords, self.dropoutKeepProb)
# 定义两层双向LSTM的模型结构
with tf.name_scope("Bi-LSTM"):
for idx, hiddenSize in enumerate(config.model.hiddenSizes):
with tf.name_scope("Bi-LSTM" + str(idx)):
# 定义前向LSTM结构
lstmFwCell = tf.nn.rnn_cell.DropoutWrapper(tf.nn.rnn_cell.LSTMCell(num_units=hiddenSize, state_is_tuple=True),
output_keep_prob=self.dropoutKeepProb)
# 定义反向LSTM结构
lstmBwCell = tf.nn.rnn_cell.DropoutWrapper(tf.nn.rnn_cell.LSTMCell(num_units=hiddenSize, state_is_tuple=True),
output_keep_prob=self.dropoutKeepProb)
# 采用动态rnn,可以动态的输入序列的长度,若没有输入,则取序列的全长
# outputs是一个元组(output_fw, output_bw),其中两个元素的维度都是[batch_size, max_time, hidden_size],fw和bw的hidden_size一样
# self.current_state 是最终的状态,二元组(state_fw, state_bw),state_fw=[batch_size, s],s是一个元祖(h, c)
outputs_, self.current_state = tf.nn.bidirectional_dynamic_rnn(lstmFwCell, lstmBwCell,
self.embeddedWords, dtype=tf.float32,
scope="bi-lstm" + str(idx))
# 对outputs中的fw和bw的结果拼接 [batch_size, time_step, hidden_size * 2], 传入到下一层Bi-LSTM中
self.embeddedWords = tf.concat(outputs_, 2)
# 将最后一层Bi-LSTM输出的结果分割成前向和后向的输出
outputs = tf.split(self.embeddedWords, 2, -1)
# 在Bi-LSTM+Attention的论文中,将前向和后向的输出相加
with tf.name_scope("Attention"):
H = outputs[0] + outputs[1]
# 得到Attention的输出
output = self._attention(H)
outputSize = config.model.hiddenSizes[-1]
# 全连接层的输出
with tf.name_scope("output"):
outputW = tf.get_variable(
"outputW",
shape=[outputSize, 1],
initializer=tf.contrib.layers.xavier_initializer())
outputB= tf.Variable(tf.constant(0.1, shape=[1]), name="outputB")
l2Loss += tf.nn.l2_loss(outputW)
l2Loss += tf.nn.l2_loss(outputB)
self.predictions = tf.nn.xw_plus_b(output, outputW, outputB, name="predictions")
self.binaryPreds = tf.cast(tf.greater_equal(self.predictions, 0.0), tf.float32, name="binaryPreds")
# 计算二元交叉熵损失
with tf.name_scope("loss"):
losses = tf.nn.sigmoid_cross_entropy_with_logits(logits=self.predictions, labels=self.inputY)
self.loss = tf.reduce_mean(losses) + config.model.l2RegLambda * l2Loss
def _attention(self, H):
"""
利用Attention机制得到句子的向量表示
"""
# 获得最后一层LSTM的神经元数量
hiddenSize = config.model.hiddenSizes[-1]
# 初始化一个权重向量,是可训练的参数
W = tf.Variable(tf.random_normal([hiddenSize], stddev=0.1))
# 对Bi-LSTM的输出用激活函数做非线性转换
M = tf.tanh(H)
# 对W和M做矩阵运算,W=[batch_size, time_step, hidden_size],计算前做维度转换成[batch_size * time_step, hidden_size]
# newM = [batch_size, time_step, 1],每一个时间步的输出由向量转换成一个数字
newM = tf.matmul(tf.reshape(M, [-1, hiddenSize]), tf.reshape(W, [-1, 1]))
# 对newM做维度转换成[batch_size, time_step]
restoreM = tf.reshape(newM, [-1, config.sequenceLength])
# 用softmax做归一化处理[batch_size, time_step]
self.alpha = tf.nn.softmax(restoreM)
# 利用求得的alpha的值对H进行加权求和,用矩阵运算直接操作
r = tf.matmul(tf.transpose(H, [0, 2, 1]), tf.reshape(self.alpha, [-1, config.sequenceLength, 1]))
# 将三维压缩成二维sequeezeR=[batch_size, hidden_size]
sequeezeR = tf.squeeze(r)
sentenceRepren = tf.tanh(sequeezeR)
# 对Attention的输出可以做dropout处理
output = tf.nn.dropout(sentenceRepren, self.dropoutKeepProb)
return output
3.4 模型训练:mode_trainning.py
# Author:yifan
# _*_ coding:utf-8 _*_
import os
import datetime
import numpy as np
import tensorflow as tf
import parameter_config
import get_train_data
import mode_structure
from sklearn.metrics import roc_auc_score, accuracy_score, precision_score, recall_score
from data import TokenBatcher #不能从bilm直接导入TokenBatcher,因为需要修改内部的open为with open(filename, encoding="utf8") as f:
from bilm import BidirectionalLanguageModel, weight_layers, dump_token_embeddings, Batcher
#获取前些模块的数据
config =parameter_config.Config()
data = get_train_data.Dataset(config)
data.dataGen()
#4生成batch数据集
def nextBatch(x, y, batchSize):
# 生成batch数据集,用生成器的方式输出
# perm = np.arange(len(x)) #返回[0 1 2 ... len(x)]的数组
# np.random.shuffle(perm) #乱序
# # x = x[perm]
# # y = y[perm]
# x = np.array(x)[perm]
# y = np.array(y)[perm]
# print(x)
# # np.random.shuffle(x) #不能用这种,会导致x和y不一致
# # np.random.shuffle(y)
midVal = list(zip(x, y))
np.random.shuffle(midVal)
x, y = zip(*midVal)
x = list(x)
y = list(y)
print(x)
numBatches = len(x) // batchSize
for i in range(numBatches):
start = i * batchSize
end = start + batchSize
batchX = np.array(x[start: end])
batchY = np.array(y[start: end])
yield batchX, batchY
# 5 定义计算metrics的函数
"""
定义各类性能指标
"""
def mean(item):
return sum(item) / len(item)
def genMetrics(trueY, predY, binaryPredY):
"""
生成acc和auc值
"""
auc = roc_auc_score(trueY, predY)
accuracy = accuracy_score(trueY, binaryPredY)
precision = precision_score(trueY, binaryPredY)
recall = recall_score(trueY, binaryPredY)
return round(accuracy, 4), round(auc, 4), round(precision, 4), round(recall, 4)
# 6 训练模型
# 生成训练集和验证集
trainReviews = data.trainReviews
trainLabels = data.trainLabels
evalReviews = data.evalReviews
evalLabels = data.evalLabels
# 定义计算图
with tf.Graph().as_default():
session_conf = tf.ConfigProto(allow_soft_placement=True, log_device_placement=False)
session_conf.gpu_options.allow_growth=True
session_conf.gpu_options.per_process_gpu_memory_fraction = 0.9 # 配置gpu占用率
sess = tf.Session(config=session_conf)
# 定义会话
with sess.as_default():
elmoMode = mode_structure.ELMo(config)
# 实例化BiLM对象,这个必须放置在全局下,不能在elmo函数中定义,否则会出现重复生成tensorflow节点。
with tf.variable_scope("bilm", reuse=True):
bilm = BidirectionalLanguageModel(
config.optionFile,
config.weightFile,
use_character_inputs=False,
embedding_weight_file=config.tokenEmbeddingFile
)
inputData = tf.placeholder('int32', shape=(None, None))
# 调用bilm中的__call__方法生成op对象
inputEmbeddingsOp = bilm(inputData)
# 计算ELMo向量表示
elmoInput = weight_layers('input', inputEmbeddingsOp, l2_coef=0.0)
globalStep = tf.Variable(0, name="globalStep", trainable=False)
# 定义优化函数,传入学习速率参数
optimizer = tf.train.AdamOptimizer(config.training.learningRate)
# 计算梯度,得到梯度和变量
gradsAndVars = optimizer.compute_gradients(elmoMode.loss)
# 将梯度应用到变量下,生成训练器
trainOp = optimizer.apply_gradients(gradsAndVars, global_step=globalStep)
# 用summary绘制tensorBoard
gradSummaries = []
for g, v in gradsAndVars:
if g is not None:
tf.summary.histogram("{}/grad/hist".format(v.name), g)
tf.summary.scalar("{}/grad/sparsity".format(v.name), tf.nn.zero_fraction(g))
outDir = os.path.abspath(os.path.join(os.path.curdir, "summarys"))
print("Writing to {}\n".format(outDir))
lossSummary = tf.summary.scalar("loss", elmoMode.loss)
summaryOp = tf.summary.merge_all()
trainSummaryDir = os.path.join(outDir, "train")
trainSummaryWriter = tf.summary.FileWriter(trainSummaryDir, sess.graph)
evalSummaryDir = os.path.join(outDir, "eval")
evalSummaryWriter = tf.summary.FileWriter(evalSummaryDir, sess.graph)
# 初始化所有变量
saver = tf.train.Saver(tf.global_variables(), max_to_keep=5)
savedModelPath ="../model/ELMo/savedModel"
if os.path.exists(savedModelPath):
os.rmdir(savedModelPath)
# 保存模型的一种方式,保存为pb文件
builder = tf.saved_model.builder.SavedModelBuilder(savedModelPath)
sess.run(tf.global_variables_initializer())
def elmo(reviews):
"""
对每一个输入的batch都动态的生成词向量表示
"""
# tf.reset_default_graph()
# TokenBatcher是生成词表示的batch类
# print("________")
batcher = TokenBatcher(config.vocabFile)
# 生成batch数据
inputDataIndex = batcher.batch_sentences(reviews)
# 计算ELMo的向量表示
elmoInputVec = sess.run(
[elmoInput['weighted_op']],
feed_dict={inputData: inputDataIndex}
)
return elmoInputVec
def trainStep(batchX, batchY):
"""
训练函数
"""
feed_dict = {
elmoMode.inputX: elmo(batchX)[0], # inputX直接用动态生成的ELMo向量表示代入
elmoMode.inputY: np.array(batchY, dtype="float32"),
elmoMode.dropoutKeepProb: config.model.dropoutKeepProb
}
_, summary, step, loss, predictions, binaryPreds = sess.run(
[trainOp, summaryOp, globalStep, elmoMode.loss, elmoMode.predictions, elmoMode.binaryPreds],
feed_dict)
timeStr = datetime.datetime.now().isoformat()
acc, auc, precision, recall = genMetrics(batchY, predictions, binaryPreds)
print("{}, step: {}, loss: {}, acc: {}, auc: {}, precision: {}, recall: {}".format(timeStr, step, loss, acc, auc, precision, recall))
trainSummaryWriter.add_summary(summary, step)
def devStep(batchX, batchY):
"""
验证函数
"""
feed_dict = {
elmoMode.inputX: elmo(batchX)[0],
elmoMode.inputY: np.array(batchY, dtype="float32"),
elmoMode.dropoutKeepProb: 1.0
}
summary, step, loss, predictions, binaryPreds = sess.run(
[summaryOp, globalStep, elmoMode.loss, elmoMode.predictions, elmoMode.binaryPreds],
feed_dict)
acc, auc, precision, recall = genMetrics(batchY, predictions, binaryPreds)
evalSummaryWriter.add_summary(summary, step)
return loss, acc, auc, precision, recall
for i in range(config.training.epoches):
# 训练模型
print("start training model")
for batchTrain in nextBatch(trainReviews, trainLabels, config.batchSize):
trainStep(batchTrain[0], batchTrain[1])
currentStep = tf.train.global_step(sess, globalStep)
if currentStep % config.training.evaluateEvery == 0:
print("\nEvaluation:")
losses = []
accs = []
aucs = []
precisions = []
recalls = []
for batchEval in nextBatch(evalReviews, evalLabels, config.batchSize):
loss, acc, auc, precision, recall = devStep(batchEval[0], batchEval[1])
losses.append(loss)
accs.append(acc)
aucs.append(auc)
precisions.append(precision)
recalls.append(recall)
time_str = datetime.datetime.now().isoformat()
print("{}, step: {}, loss: {}, acc: {}, auc: {}, precision: {}, recall: {}".format(time_str, currentStep, mean(losses),
mean(accs), mean(aucs), mean(precisions),
mean(recalls)))
if currentStep % config.training.checkpointEvery == 0:
# 保存模型的另一种方法,保存checkpoint文件
path = saver.save(sess, "../model/ELMo/model/my-model", global_step=currentStep)
print("Saved model checkpoint to {}\n".format(path))
inputs = {"inputX": tf.saved_model.utils.build_tensor_info(elmoMode.inputX),
"keepProb": tf.saved_model.utils.build_tensor_info(elmoMode.dropoutKeepProb)}
outputs = {"binaryPreds": tf.saved_model.utils.build_tensor_info(elmoMode.binaryPreds)}
prediction_signature = tf.saved_model.signature_def_utils.build_signature_def(inputs=inputs, outputs=outputs,
method_name=tf.saved_model.signature_constants.PREDICT_METHOD_NAME)
legacy_init_op = tf.group(tf.tables_initializer(), name="legacy_init_op")
builder.add_meta_graph_and_variables(sess, [tf.saved_model.tag_constants.SERVING],
signature_def_map={"predict": prediction_signature}, legacy_init_op=legacy_init_op)
builder.save()
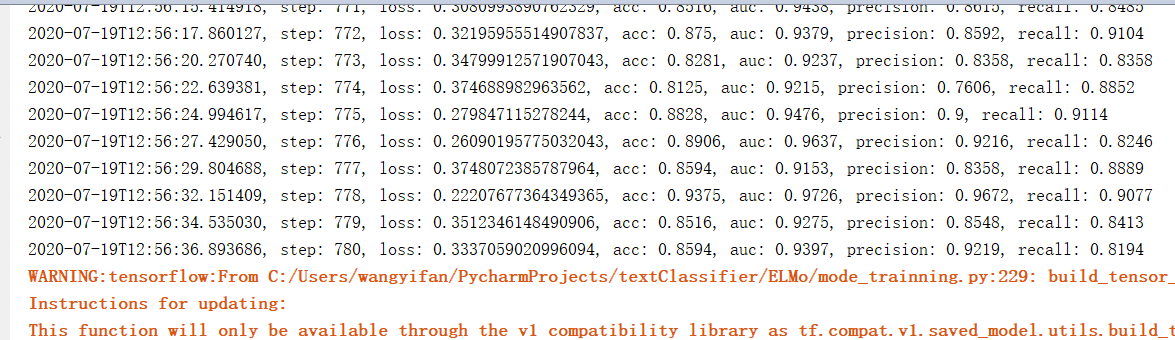
训练结果
相关代码可见:https://github.com/yifanhunter/NLP_textClassifier

 浙公网安备 33010602011771号
浙公网安备 33010602011771号