【文本分类-04】BiLSTM
目录
- 大纲概述
- 数据集合
- 数据处理
- 预训练word2vec模型
一、大纲概述
文本分类这个系列将会有8篇左右文章,从github直接下载代码,从百度云下载训练数据,在pycharm上导入即可使用,包括基于word2vec预训练的文本分类,与及基于近几年的预训练模型(ELMo,BERT等)的文本分类。总共有以下系列:
二、数据集合
数据集为IMDB 电影影评,总共有三个数据文件,在/data/rawData目录下,包括unlabeledTrainData.tsv,labeledTrainData.tsv,testData.tsv。在进行文本分类时需要有标签的数据(labeledTrainData),但是在训练word2vec词向量模型(无监督学习)时可以将无标签的数据一起用上。
训练数据地址:链接:https://pan.baidu.com/s/1-XEwx1ai8kkGsMagIFKX_g 提取码:rtz8
三、主要代码
3.1 配置训练参数:parameter_config.py
1 # 配置参数
2 class TrainingConfig(object):
3 epoches = 10
4 evaluateEvery = 100
5 checkpointEvery = 100
6 learningRate = 0.001
7
8 class ModelConfig(object):
9 embeddingSize = 200
10 hiddenSizes = [256, 256] # 单层LSTM结构的神经元个数
11 dropoutKeepProb = 0.5
12 l2RegLambda = 0.0
13
14 class Config(object):
15 sequenceLength = 200 # 取了所有序列长度的均值
16 batchSize = 128
17 dataSource = "../data/preProcess/labeledTrain.csv"
18 stopWordSource = "../data/english"
19 numClasses = 1 # 二分类设置为1,多分类设置为类别的数目
20 rate = 0.8 # 训练集的比例
21 training = TrainingConfig()
22 model = ModelConfig()
23
24 # 实例化配置参数对象
25 # config = Config()
3.2 获取训练数据:get_train_data.py
1 # Author:yifan
2 import json
3 from collections import Counter
4 import gensim
5 import pandas as pd
6 import numpy as np
7 import parameter_config
8
9 # 2 数据预处理的类,生成训练集和测试集
10 # 1)将数据加载进来,将句子分割成词表示,并去除低频词和停用词。
11 # 2)将词映射成索引表示,构建词汇-索引映射表,并保存成json的数据格式,
12 # 之后做inference时可以用到。(注意,有的词可能不在word2vec的预训练词向量中,这种词直接用UNK表示)
13 # 3)从预训练的词向量模型中读取出词向量,作为初始化值输入到模型中。
14 # 4)将数据集分割成训练集和测试集
15
16 class Dataset(object):
17 def __init__(self, config):
18 self.config = config
19 self._dataSource = config.dataSource
20 self._stopWordSource = config.stopWordSource
21 self._sequenceLength = config.sequenceLength # 每条输入的序列处理为定长
22 self._embeddingSize = config.model.embeddingSize
23 self._batchSize = config.batchSize
24 self._rate = config.rate
25 self._stopWordDict = {}
26 self.trainReviews = []
27 self.trainLabels = []
28 self.evalReviews = []
29 self.evalLabels = []
30 self.wordEmbedding = None
31 self.labelList = []
32
33 def _readData(self, filePath):
34 """
35 从csv文件中读取数据集
36 """
37 df = pd.read_csv(filePath)
38 if self.config.numClasses == 1:
39 labels = df["sentiment"].tolist()
40 elif self.config.numClasses > 1:
41 labels = df["rate"].tolist()
42 review = df["review"].tolist()
43 reviews = [line.strip().split() for line in review]
44 return reviews, labels
45
46 def _labelToIndex(self, labels, label2idx):
47 """
48 将标签转换成索引表示
49 """
50 labelIds = [label2idx[label] for label in labels]
51 return labelIds
52
53 def _wordToIndex(self, reviews, word2idx):
54 """
55 将词转换成索引
56 """
57 reviewIds = [[word2idx.get(item, word2idx["UNK"]) for item in review] for review in reviews]
58 return reviewIds
59
60 def _genTrainEvalData(self, x, y, word2idx, rate):
61 """
62 生成训练集和验证集
63 """
64 reviews = []
65 for review in x:
66 if len(review) >= self._sequenceLength:
67 reviews.append(review[:self._sequenceLength])
68 else:
69 reviews.append(review + [word2idx["PAD"]] * (self._sequenceLength - len(review)))
70 trainIndex = int(len(x) * rate)
71 trainReviews = np.asarray(reviews[:trainIndex], dtype="int64")
72 trainLabels = np.array(y[:trainIndex], dtype="float32")
73 evalReviews = np.asarray(reviews[trainIndex:], dtype="int64")
74 evalLabels = np.array(y[trainIndex:], dtype="float32")
75 return trainReviews, trainLabels, evalReviews, evalLabels
76
77 def _getWordEmbedding(self, words):
78 """
79 按照我们的数据集中的单词取出预训练好的word2vec中的词向量
80 """
81 wordVec = gensim.models.KeyedVectors.load_word2vec_format("../word2vec/word2Vec.bin", binary=True)
82 vocab = []
83 wordEmbedding = []
84 # 添加 "pad" 和 "UNK",
85 vocab.append("PAD")
86 vocab.append("UNK")
87 wordEmbedding.append(np.zeros(self._embeddingSize))
88 wordEmbedding.append(np.random.randn(self._embeddingSize))
89
90 for word in words:
91 try:
92 vector = wordVec.wv[word]
93 vocab.append(word)
94 wordEmbedding.append(vector)
95 except:
96 print(word + "不存在于词向量中")
97
98 return vocab, np.array(wordEmbedding)
99
100 def _genVocabulary(self, reviews, labels):
101 """
102 生成词向量和词汇-索引映射字典,可以用全数据集
103 """
104 allWords = [word for review in reviews for word in review]
105
106 # 去掉停用词
107 subWords = [word for word in allWords if word not in self.stopWordDict]
108 wordCount = Counter(subWords) # 统计词频
109 sortWordCount = sorted(wordCount.items(), key=lambda x: x[1], reverse=True)
110 # 去除低频词
111 words = [item[0] for item in sortWordCount if item[1] >= 5]
112
113 vocab, wordEmbedding = self._getWordEmbedding(words)
114 self.wordEmbedding = wordEmbedding
115 word2idx = dict(zip(vocab, list(range(len(vocab)))))
116
117 uniqueLabel = list(set(labels))
118 label2idx = dict(zip(uniqueLabel, list(range(len(uniqueLabel)))))
119 self.labelList = list(range(len(uniqueLabel)))
120 # 将词汇-索引映射表保存为json数据,之后做inference时直接加载来处理数据
121 with open("../data/wordJson/word2idx.json", "w", encoding="utf-8") as f:
122 json.dump(word2idx, f)
123
124 with open("../data/wordJson/label2idx.json", "w", encoding="utf-8") as f:
125 json.dump(label2idx, f)
126
127 return word2idx, label2idx
128
129 def _readStopWord(self, stopWordPath):
130 """
131 读取停用词
132 """
133
134 with open(stopWordPath, "r") as f:
135 stopWords = f.read()
136 stopWordList = stopWords.splitlines()
137 # 将停用词用列表的形式生成,之后查找停用词时会比较快
138 self.stopWordDict = dict(zip(stopWordList, list(range(len(stopWordList)))))
139
140 def dataGen(self):
141 """
142 初始化训练集和验证集
143 """
144 # 初始化停用词
145 self._readStopWord(self._stopWordSource)
146
147 # 初始化数据集
148 reviews, labels = self._readData(self._dataSource)
149
150 # 初始化词汇-索引映射表和词向量矩阵
151 word2idx, label2idx = self._genVocabulary(reviews, labels)
152
153 # 将标签和句子数值化
154 labelIds = self._labelToIndex(labels, label2idx)
155 reviewIds = self._wordToIndex(reviews, word2idx)
156
157 # 初始化训练集和测试集
158 trainReviews, trainLabels, evalReviews, evalLabels = self._genTrainEvalData(reviewIds, labelIds, word2idx,
159 self._rate)
160 self.trainReviews = trainReviews
161 self.trainLabels = trainLabels
162
163 self.evalReviews = evalReviews
164 self.evalLabels = evalLabels
165
166 #获取前些模块的数据
167 config =parameter_config.Config()
168 data = Dataset(config)
169 data.dataGen()
3.3 模型构建:mode_structure.py
1 import tensorflow as tf
2 import parameter_config
3 # 3 构建模型 Bi-LSTM模型
4 class BiLSTM(object):
5 """
6 Bi-LSTM 用于文本分类
7 """
8 def __init__(self, config, wordEmbedding):
9 # 定义模型的输入
10 self.inputX = tf.placeholder(tf.int32, [None, config.sequenceLength], name="inputX")
11 self.inputY = tf.placeholder(tf.int32, [None], name="inputY")
12 self.dropoutKeepProb = tf.placeholder(tf.float32, name="dropoutKeepProb")
13
14 # 定义l2损失
15 l2Loss = tf.constant(0.0)
16
17 # 词嵌入层
18 with tf.name_scope("embedding"):
19 # 利用预训练的词向量初始化词嵌入矩阵
20 self.W = tf.Variable(tf.cast(wordEmbedding, dtype=tf.float32, name="word2vec"), name="W")
21 # 利用词嵌入矩阵将输入的数据中的词转换成词向量,维度[batch_size, sequence_length, embedding_size]
22 self.embeddedWords = tf.nn.embedding_lookup(self.W, self.inputX)
23
24 # 定义两层双向LSTM的模型结构
25 with tf.name_scope("Bi-LSTM"):
26 for idx, hiddenSize in enumerate(config.model.hiddenSizes):
27 with tf.name_scope("Bi-LSTM" + str(idx)):
28 # 定义前向LSTM结构
29 lstmFwCell = tf.nn.rnn_cell.DropoutWrapper(
30 tf.nn.rnn_cell.LSTMCell(num_units=hiddenSize, state_is_tuple=True),
31 output_keep_prob=self.dropoutKeepProb)
32 # 定义反向LSTM结构
33 lstmBwCell = tf.nn.rnn_cell.DropoutWrapper(
34 tf.nn.rnn_cell.LSTMCell(num_units=hiddenSize, state_is_tuple=True),
35 output_keep_prob=self.dropoutKeepProb)
36
37 # 采用动态rnn,可以动态的输入序列的长度,若没有输入,则取序列的全长
38 # outputs是一个元祖(output_fw, output_bw),其中两个元素的维度都是[batch_size, max_time, hidden_size],fw和bw的hidden_size一样
39 # self.current_state 是最终的状态,二元组(state_fw, state_bw),state_fw=[batch_size, s],s是一个元祖(h, c)
40 outputs, self.current_state = tf.nn.bidirectional_dynamic_rnn(lstmFwCell, lstmBwCell,
41 self.embeddedWords, dtype=tf.float32,
42 scope="bi-lstm" + str(idx))
43
44 # 对outputs中的fw和bw的结果拼接 [batch_size, time_step, hidden_size * 2]
45 self.embeddedWords = tf.concat(outputs, 2)
46
47 # 去除最后时间步的输出作为全连接的输入
48 finalOutput = self.embeddedWords[:, 0, :]
49
50 outputSize = config.model.hiddenSizes[-1] * 2 # 因为是双向LSTM,最终的输出值是fw和bw的拼接,因此要乘以2
51 output = tf.reshape(finalOutput, [-1, outputSize]) # reshape成全连接层的输入维度
52
53 # 全连接层的输出
54 with tf.name_scope("output"):
55 outputW = tf.get_variable(
56 "outputW",
57 shape=[outputSize, config.numClasses],
58 initializer=tf.contrib.layers.xavier_initializer())
59
60 outputB = tf.Variable(tf.constant(0.1, shape=[config.numClasses]), name="outputB")
61 l2Loss += tf.nn.l2_loss(outputW)
62 l2Loss += tf.nn.l2_loss(outputB)
63 self.logits = tf.nn.xw_plus_b(output, outputW, outputB, name="logits")
64 if config.numClasses == 1:
65 self.predictions = tf.cast(tf.greater_equal(self.logits, 0.0), tf.float32, name="predictions")
66 elif config.numClasses > 1:
67 self.predictions = tf.argmax(self.logits, axis=-1, name="predictions")
68
69 # 计算二元交叉熵损失
70 with tf.name_scope("loss"):
71 if config.numClasses == 1:
72 losses = tf.nn.sigmoid_cross_entropy_with_logits(logits=self.logits,
73 labels=tf.cast(tf.reshape(self.inputY, [-1, 1]),
74 dtype=tf.float32))
75 elif config.numClasses > 1:
76 losses = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=self.logits, labels=self.inputY)
77
78 self.loss = tf.reduce_mean(losses) + config.model.l2RegLambda * l2Loss
3.4 模型训练:mode_trainning.py
import os
import datetime
import numpy as np
import tensorflow as tf
import parameter_config
import get_train_data
import mode_structure
#因为电脑内存较小,只能选择CPU去训练了
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
#获取前些模块的数据
config =parameter_config.Config()
data = get_train_data.Dataset(config)
data.dataGen()
#4生成batch数据集
def nextBatch(x, y, batchSize):
# 生成batch数据集,用生成器的方式输出
perm = np.arange(len(x))
np.random.shuffle(perm)
x = x[perm]
y = y[perm]
numBatches = len(x) // batchSize
for i in range(numBatches):
start = i * batchSize
end = start + batchSize
batchX = np.array(x[start: end], dtype="int64")
batchY = np.array(y[start: end], dtype="float32")
yield batchX, batchY
# 5 定义计算metrics的函数
"""
定义各类性能指标
"""
"""
定义各类性能指标
"""
def mean(item: list) -> float:
"""
计算列表中元素的平均值
:param item: 列表对象
:return:
"""
res = sum(item) / len(item) if len(item) > 0 else 0
return res
def accuracy(pred_y, true_y):
"""
计算二类和多类的准确率
:param pred_y: 预测结果
:param true_y: 真实结果
:return:
"""
if isinstance(pred_y[0], list):
pred_y = [item[0] for item in pred_y]
corr = 0
for i in range(len(pred_y)):
if pred_y[i] == true_y[i]:
corr += 1
acc = corr / len(pred_y) if len(pred_y) > 0 else 0
return acc
def binary_precision(pred_y, true_y, positive=1):
"""
二类的精确率计算
:param pred_y: 预测结果
:param true_y: 真实结果
:param positive: 正例的索引表示
:return:
"""
corr = 0
pred_corr = 0
for i in range(len(pred_y)):
if pred_y[i] == positive:
pred_corr += 1
if pred_y[i] == true_y[i]:
corr += 1
prec = corr / pred_corr if pred_corr > 0 else 0
return prec
def binary_recall(pred_y, true_y, positive=1):
"""
二类的召回率
:param pred_y: 预测结果
:param true_y: 真实结果
:param positive: 正例的索引表示
:return:
"""
corr = 0
true_corr = 0
for i in range(len(pred_y)):
if true_y[i] == positive:
true_corr += 1
if pred_y[i] == true_y[i]:
corr += 1
rec = corr / true_corr if true_corr > 0 else 0
return re
def binary_f_beta(pred_y, true_y, beta=1.0, positive=1):
"""
二类的f beta值
:param pred_y: 预测结果
:param true_y: 真实结果
:param beta: beta值
:param positive: 正例的索引表示
:return:
"""
precision = binary_precision(pred_y, true_y, positive)
recall = binary_recall(pred_y, true_y, positive)
try:
f_b = (1 + beta * beta) * precision * recall / (beta * beta * precision + recall)
except:
f_b = 0
return f_b
def multi_precision(pred_y, true_y, labels):
"""
多类的精确率
:param pred_y: 预测结果
:param true_y: 真实结果
:param labels: 标签列表
:return:
"""
if isinstance(pred_y[0], list):
pred_y = [item[0] for item in pred_y]
precisions = [binary_precision(pred_y, true_y, label) for label in labels]
prec = mean(precisions)
return prec
def multi_recall(pred_y, true_y, labels):
"""
多类的召回率
:param pred_y: 预测结果
:param true_y: 真实结果
:param labels: 标签列表
:return:
"""
if isinstance(pred_y[0], list):
pred_y = [item[0] for item in pred_y]
recalls = [binary_recall(pred_y, true_y, label) for label in labels]
rec = mean(recalls)
return rec
def multi_f_beta(pred_y, true_y, labels, beta=1.0):
"""
多类的f beta值
:param pred_y: 预测结果
:param true_y: 真实结果
:param labels: 标签列表
:param beta: beta值
:return:
"""
if isinstance(pred_y[0], list):
pred_y = [item[0] for item in pred_y]
f_betas = [binary_f_beta(pred_y, true_y, beta, label) for label in labels]
f_beta = mean(f_betas)
return f_beta
def get_binary_metrics(pred_y, true_y, f_beta=1.0):
"""
得到二分类的性能指标
:param pred_y:
:param true_y:
:param f_beta:
:return:
"""
acc = accuracy(pred_y, true_y)
recall = binary_recall(pred_y, true_y)
precision = binary_precision(pred_y, true_y)
f_beta = binary_f_beta(pred_y, true_y, f_beta)
return acc, recall, precision, f_beta
def get_multi_metrics(pred_y, true_y, labels, f_beta=1.0):
"""
得到多分类的性能指标
:param pred_y:
:param true_y:
:param labels:
:param f_beta:
:return:
"""
acc = accuracy(pred_y, true_y)
recall = multi_recall(pred_y, true_y, labels)
precision = multi_precision(pred_y, true_y, labels)
f_beta = multi_f_beta(pred_y, true_y, labels, f_beta)
return acc, recall, precision, f_beta
# 6 训练模型
# 生成训练集和验证集
trainReviews = data.trainReviews
trainLabels = data.trainLabels
evalReviews = data.evalReviews
evalLabels = data.evalLabels
wordEmbedding = data.wordEmbedding
labelList = data.labelList
# 定义计算图
with tf.Graph().as_default():
session_conf = tf.ConfigProto(allow_soft_placement=True, log_device_placement=False)
session_conf.gpu_options.allow_growth = True
session_conf.gpu_options.per_process_gpu_memory_fraction = 0.9 # 配置gpu占用率
sess = tf.Session(config=session_conf)
# 定义会话
with sess.as_default():
lstm = mode_structure.BiLSTM(config, wordEmbedding)
globalStep = tf.Variable(0, name="globalStep", trainable=False)
# 定义优化函数,传入学习速率参数
optimizer = tf.train.AdamOptimizer(config.training.learningRate)
# 计算梯度,得到梯度和变量
gradsAndVars = optimizer.compute_gradients(lstm.loss)
# 将梯度应用到变量下,生成训练器
trainOp = optimizer.apply_gradients(gradsAndVars, global_step=globalStep)
# 用summary绘制tensorBoard
gradSummaries = []
for g, v in gradsAndVars:
if g is not None:
tf.summary.histogram("{}/grad/hist".format(v.name), g)
tf.summary.scalar("{}/grad/sparsity".format(v.name), tf.nn.zero_fraction(g))
outDir = os.path.abspath(os.path.join(os.path.curdir, "summarys"))
print("Writing to {}\n".format(outDir))
lossSummary = tf.summary.scalar("loss", lstm.loss)
summaryOp = tf.summary.merge_all()
trainSummaryDir = os.path.join(outDir, "train")
trainSummaryWriter = tf.summary.FileWriter(trainSummaryDir, sess.graph)
evalSummaryDir = os.path.join(outDir, "eval")
evalSummaryWriter = tf.summary.FileWriter(evalSummaryDir, sess.graph)
# 初始化所有变量
saver = tf.train.Saver(tf.global_variables(), max_to_keep=5)
# 保存模型的一种方式,保存为pb文件
savedModelPath = "../model/Bi-LSTM/savedModel"
if os.path.exists(savedModelPath):
os.rmdir(savedModelPath)
builder = tf.saved_model.builder.SavedModelBuilder(savedModelPath)
sess.run(tf.global_variables_initializer())
def trainStep(batchX, batchY):
"""
训练函数
"""
feed_dict = {
lstm.inputX: batchX,
lstm.inputY: batchY,
lstm.dropoutKeepProb: config.model.dropoutKeepProb
}
_, summary, step, loss, predictions = sess.run(
[trainOp, summaryOp, globalStep, lstm.loss, lstm.predictions],
feed_dict)
timeStr = datetime.datetime.now().isoformat()
if config.numClasses == 1:
acc, recall, prec, f_beta = get_binary_metrics(pred_y=predictions, true_y=batchY)
elif config.numClasses > 1:
acc, recall, prec, f_beta = get_multi_metrics(pred_y=predictions, true_y=batchY,
labels=labelList)
trainSummaryWriter.add_summary(summary, step)
return loss, acc, prec, recall, f_beta
def devStep(batchX, batchY):
"""
验证函数
"""
feed_dict = {
lstm.inputX: batchX,
lstm.inputY: batchY,
lstm.dropoutKeepProb: 1.0
}
summary, step, loss, predictions = sess.run(
[summaryOp, globalStep, lstm.loss, lstm.predictions],
feed_dict)
if config.numClasses == 1:
acc, precision, recall, f_beta = get_binary_metrics(pred_y=predictions, true_y=batchY)
elif config.numClasses > 1:
acc, precision, recall, f_beta = get_multi_metrics(pred_y=predictions, true_y=batchY, labels=labelList)
evalSummaryWriter.add_summary(summary, step)
return loss, acc, precision, recall, f_beta
for i in range(config.training.epoches):
# 训练模型
print("start training model")
for batchTrain in nextBatch(trainReviews, trainLabels, config.batchSize):
loss, acc, prec, recall, f_beta = trainStep(batchTrain[0], batchTrain[1])
currentStep = tf.train.global_step(sess, globalStep)
print("train: step: {}, loss: {}, acc: {}, recall: {}, precision: {}, f_beta: {}".format(
currentStep, loss, acc, recall, prec, f_beta))
if currentStep % config.training.evaluateEvery == 0:
print("\nEvaluation:")
losses = []
accs = []
f_betas = []
precisions = []
recalls = []
for batchEval in nextBatch(evalReviews, evalLabels, config.batchSize):
loss, acc, precision, recall, f_beta = devStep(batchEval[0], batchEval[1])
losses.append(loss)
accs.append(acc)
f_betas.append(f_beta)
precisions.append(precision)
recalls.append(recall)
time_str = datetime.datetime.now().isoformat()
print("{}, step: {}, loss: {}, acc: {},precision: {}, recall: {}, f_beta: {}".format(time_str,
currentStep,
mean(losses),
mean(accs),
mean(
precisions),
mean(recalls),
mean(f_betas)))
if currentStep % config.training.checkpointEvery == 0:
# 保存模型的另一种方法,保存checkpoint文件
path = saver.save(sess, "../model/Bi-LSTM/model/my-model", global_step=currentStep)
print("Saved model checkpoint to {}\n".format(path))
inputs = {"inputX": tf.saved_model.utils.build_tensor_info(lstm.inputX),
"keepProb": tf.saved_model.utils.build_tensor_info(lstm.dropoutKeepProb)}
outputs = {"predictions": tf.saved_model.utils.build_tensor_info(lstm.predictions)}#这里应该是lstm.binaryPreds。
prediction_signature = tf.saved_model.signature_def_utils.build_signature_def(inputs=inputs, outputs=outputs,
method_name=tf.saved_model.signature_constants.PREDICT_METHOD_NAME)
legacy_init_op = tf.group(tf.tables_initializer(), name="legacy_init_op")
builder.add_meta_graph_and_variables(sess, [tf.saved_model.tag_constants.SERVING],
signature_def_map={"predict": prediction_signature},
legacy_init_op=legacy_init_op)
builder.save()
3.5 预测:predict.py
1 # Author:yifan
2 import os
3 import csv
4 import time
5 import datetime
6 import random
7 import json
8 from collections import Counter
9 from math import sqrt
10 import gensim
11 import pandas as pd
12 import numpy as np
13 import tensorflow as tf
14 from sklearn.metrics import roc_auc_score, accuracy_score, precision_score, recall_score
15 import parameter_config
16 config =parameter_config.Config()
17
18 #7预测代码
19 x = "this movie is full of references like mad max ii the wild one and many others the ladybug´s face it´s a clear reference or tribute to peter lorre this movie is a masterpiece we´ll talk much more about in the future"
20
21 # 注:下面两个词典要保证和当前加载的模型对应的词典是一致的
22 with open("../data/wordJson/word2idx.json", "r", encoding="utf-8") as f:
23 word2idx = json.load(f)
24
25 with open("../data/wordJson/label2idx.json", "r", encoding="utf-8") as f:
26 label2idx = json.load(f)
27 idx2label = {value: key for key, value in label2idx.items()}
28
29 xIds = [word2idx.get(item, word2idx["UNK"]) for item in x.split(" ")]
30 if len(xIds) >= config.sequenceLength:
31 xIds = xIds[:config.sequenceLength]
32 else:
33 xIds = xIds + [word2idx["PAD"]] * (config.sequenceLength - len(xIds))
34
35 graph = tf.Graph()
36 with graph.as_default():
37 gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.333)
38 session_conf = tf.ConfigProto(allow_soft_placement=True, log_device_placement=False, gpu_options=gpu_options)
39 sess = tf.Session(config=session_conf)
40
41 with sess.as_default():
42 checkpoint_file = tf.train.latest_checkpoint("../model/Bi-LSTM/model/")
43 saver = tf.train.import_meta_graph("{}.meta".format(checkpoint_file))
44 saver.restore(sess, checkpoint_file)
45
46 # 获得需要喂给模型的参数,输出的结果依赖的输入值
47 inputX = graph.get_operation_by_name("inputX").outputs[0]
48 dropoutKeepProb = graph.get_operation_by_name("dropoutKeepProb").outputs[0]
49
50 # 获得输出的结果
51 predictions = graph.get_tensor_by_name("output/predictions:0")
52
53 pred = sess.run(predictions, feed_dict={inputX: [xIds], dropoutKeepProb: 1.0})[0]
54
55 # print(pred)
56 pred = [idx2label[item] for item in pred]
57 print(pred)
结果
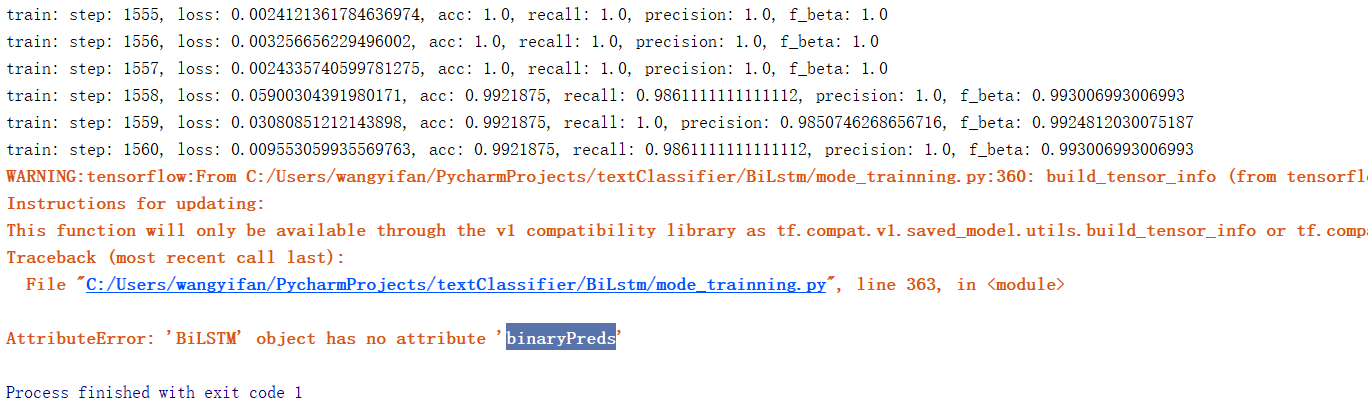
相关代码可见:https://github.com/yifanhunter/NLP_textClassifier

 浙公网安备 33010602011771号
浙公网安备 33010602011771号