深度学习素材
1.人工智能发展历史
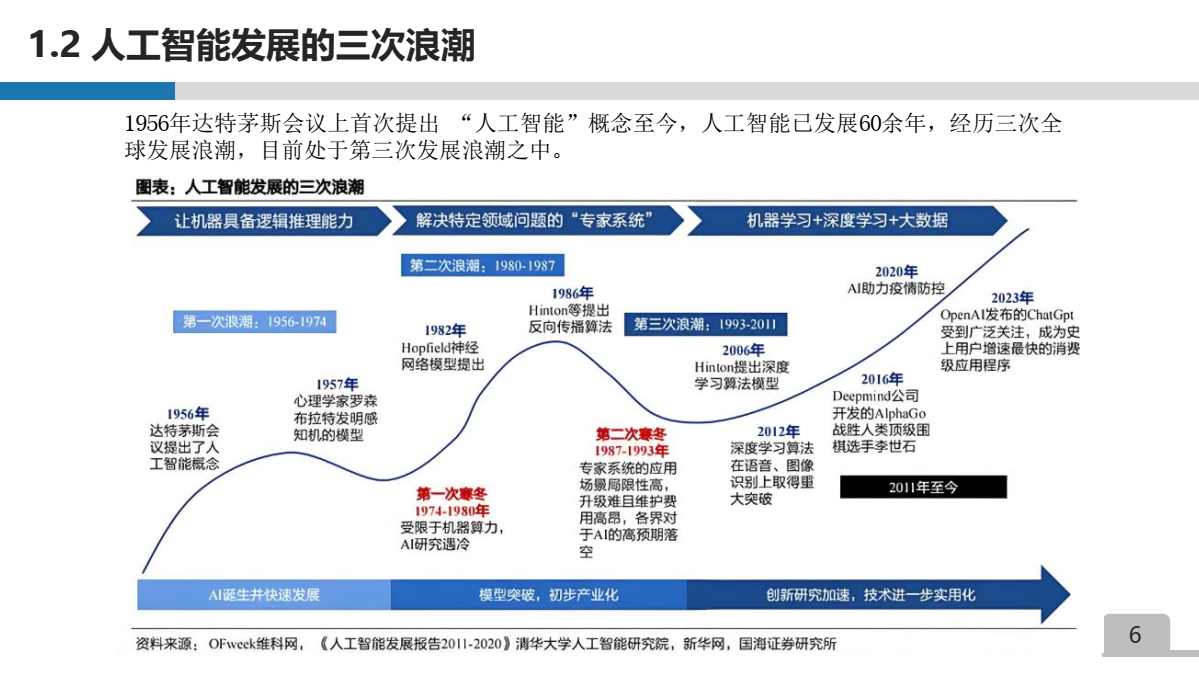
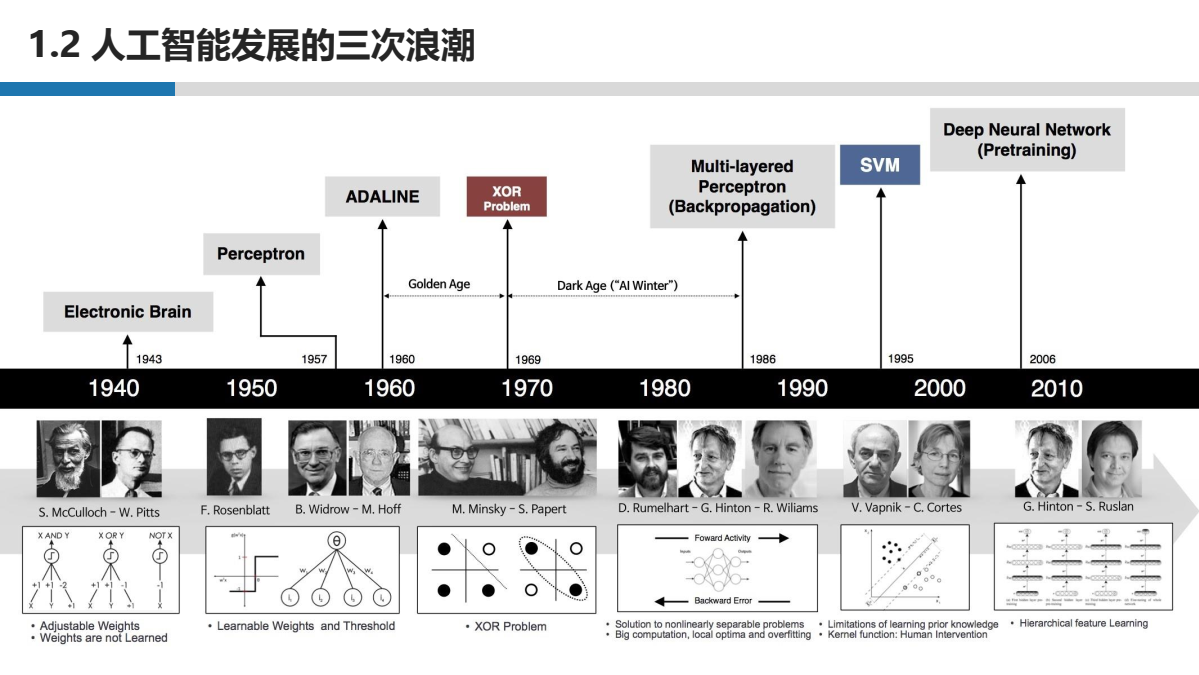
1956年达特茅斯会议上首次提出 “人工智能” 概念至今, 人工智能已发展60余年, 经历三次全球发展浪潮, 目前处于第三次发展浪潮之中。
人工智能三次浪潮 [文章1]

2.神经网络基础
(1)线性回归 & 多元线性回归:[视频1]
(3)神经元与简单神经网络
(4)激活函数:[视频1]
(5)梯度下降算法
(6)前向过程 与 反向传播: 2分钟带你手撕神经网络 的前向 反向 求导 更参~
(7)神经网络训练过程:
神经网络训练过程(1/3)---梯度下降法。 深度学习必经之路。
(7)感知机模型MLP :
3. Pytorch基础(前置:Python基础、Numpy、OpenCV)
(1)环境配置 (Anaconda版本不变,其虚拟环境可以拷贝到不同的机器上复用,PyCharm选择最新版本)
(2)张量(Tensor)
(3)基于Numpy库实现线性回归OLS
(4)基于Pytorch实现OLS
4.卷积神经网络CNN
什么是卷积,卷积核
(1)“卷积”在计算机中是如何进行计算的? 一张图告诉你卷积神经网络"香"在哪里?
(2)想搞定卷积神经网络 ,一定要弄清楚卷积核 步长 池化 填充这四个概念的用法和意义!
单通道卷积与多通道卷积
(4)卷积的关键组件 -- 卷积层 (卷积、池化、全连接层)
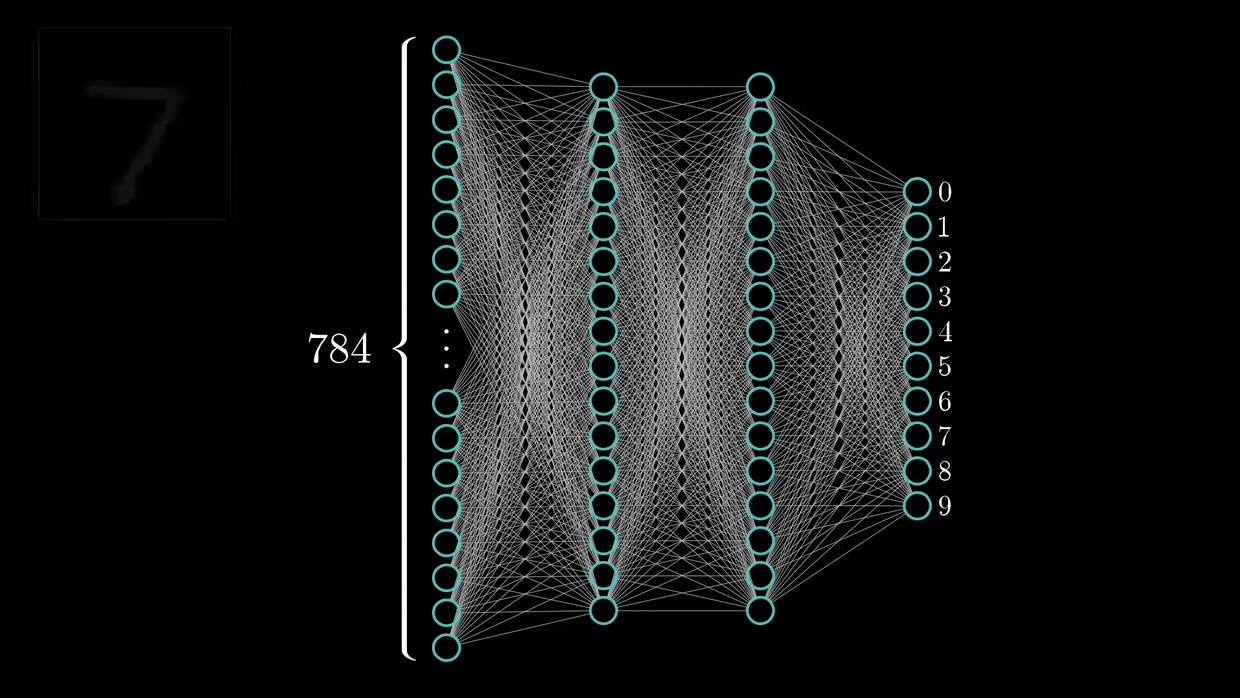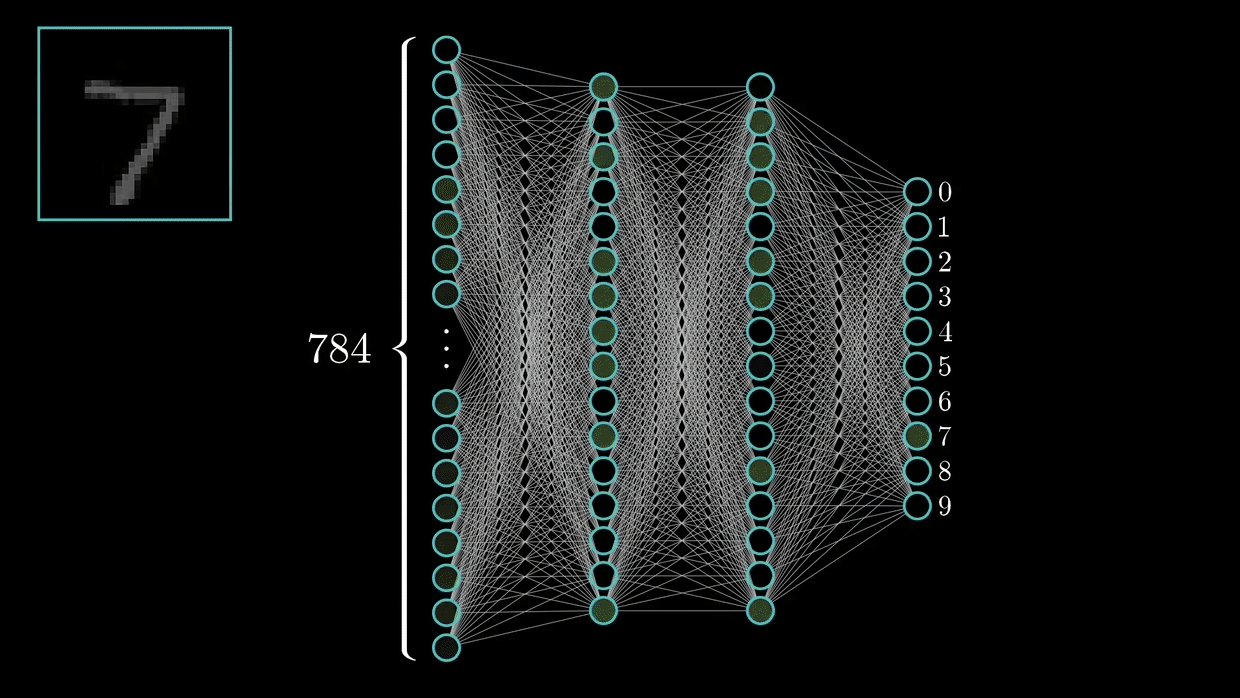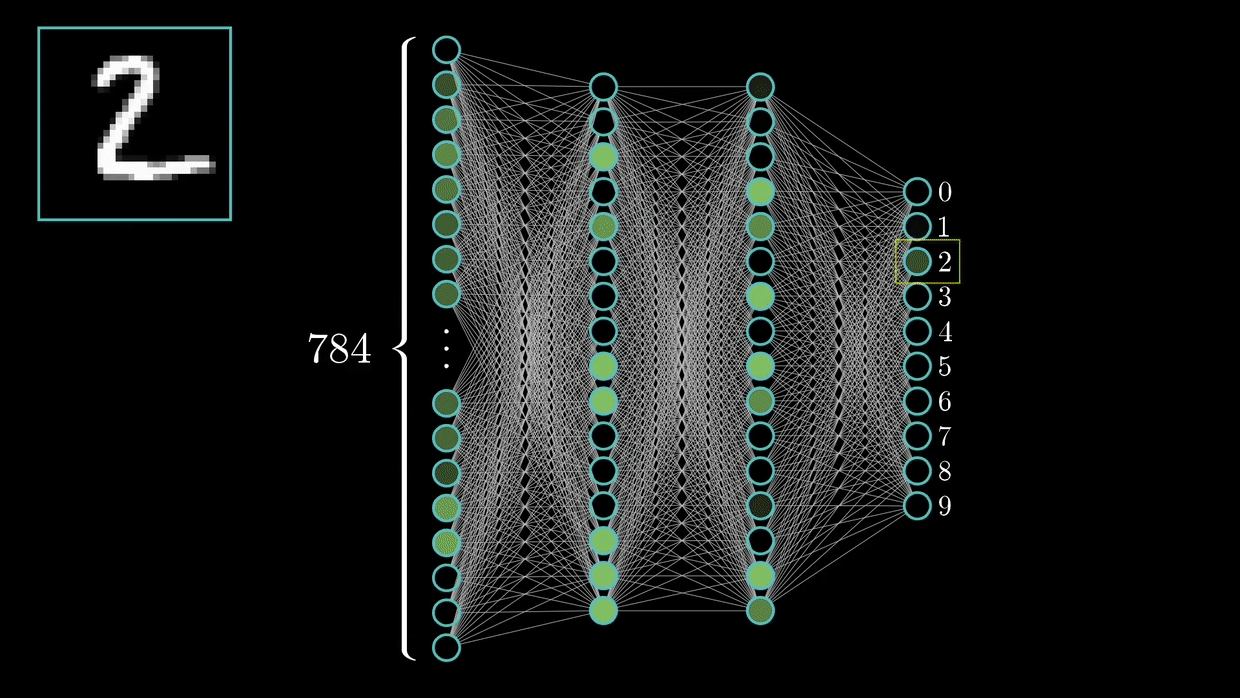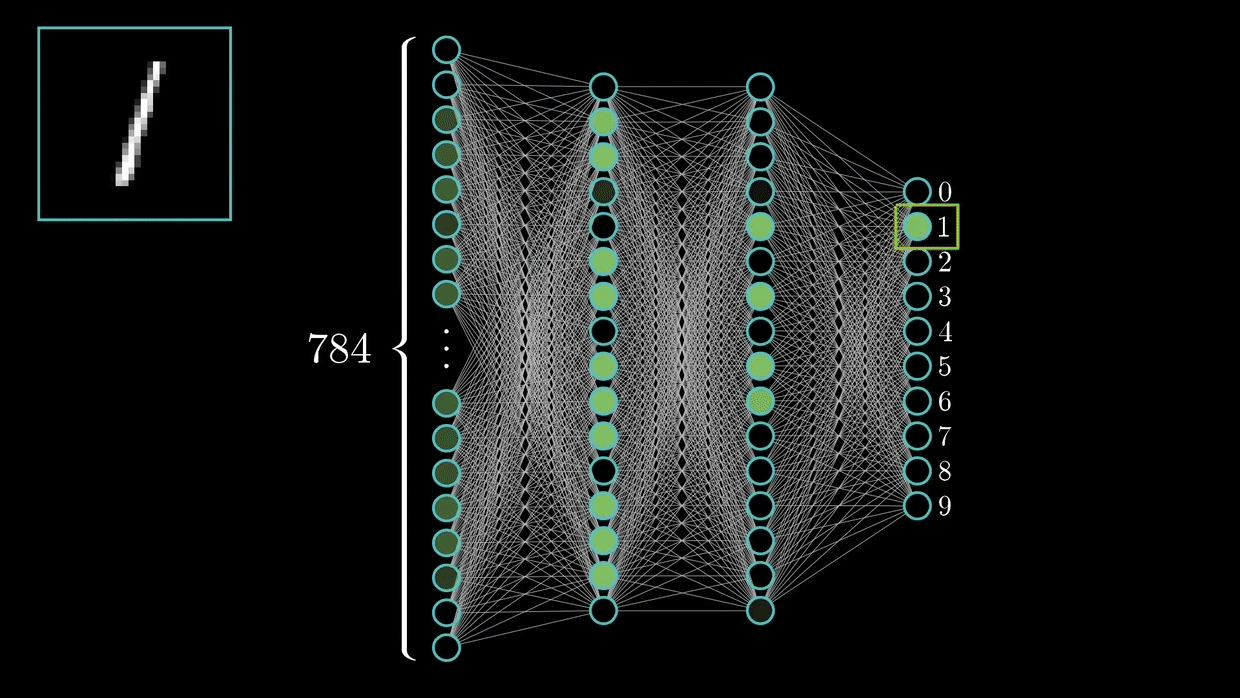
(5)手写数字识别(LeNet5)
(6)猫狗识别 (VGG-Net)

(7)全卷积神经网络FCN
(8)遥感图像建筑分类(U-Net)
(9)空洞卷积
(10)语义分类与语义分割
(12)自注意力与Transformer [视频2] [视频3]
注意力机制(Attention Mechanism),就是在大量输入信息中,根据当前任务的相关性(Q*K),赋予不同部分不同的“权重”,让模型更加关注与目标相关的内容。
自注意力机制(Self-Attention),是注意力机制的一种特例。在同一个序列内部,不同位置之间相互计算注意力权重,以捕捉各个元素之间的依赖关系。[文章]
自注意力机制的核心原理是通过计算序列中每个元素与其他元素之间的相似度,来分配不同的注意力权重。这些权重反映了模型在处理序列时对不同元素的关注程度。通过这种方式,模型能够聚焦于序列中的重要信息,并忽略无关的噪声,实现对序列的精细化处理。
在 Transformer 中,序列中每个词都会通过自注意力机制重新编码,融合整个句子的上下文信息,这种特性是 Transformer 能够有效建模长距离依赖关系的关键
5. 点云深度学习
(1)PointNet & PointNet++ [文章1] [视频2] [[5分钟点云学习] #02 PointNet 开山之作]
(2)Randla-Net [视频1]
(3)Voxel-net [视频1] [视频2] [视频3]
(4)Point Transformer [v3 视频]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号