
AI开发-python-langchain框架(1-8-1 缓存机制——让 AI 应用“记住”高频问题)
想象一下,你现在是一家大型电商平台的AI架构师。双十一期间,你的智能客服系统每天要处理千万级的用户咨询。每个问题都要调用昂贵的GPT-API,响应慢、成本高,用户投诉飙升……这时候,你会怎么做?"
"我们会发现一个奇怪的现象——每天有30%的问题是完全相同的!用户都在问:'快递几天能到?'、'怎么退货?'、'商品有保修吗?'……每个问题都要调用GPT-4,每次花费0.03美元,一天就是数万美元!更糟的是,相同的回答,用户要等3-5秒才能看到……"
解决方案:引入缓存机制(如下使用sqlite当缓存数据库),当用户问道相同问题时,从缓存里直接给出答案不用将问题在送给大模型,既节约金钱成本也节约时间成本。
直接看代码:
from langchain_community.cache import SQLiteCache
from langchain.globals import set_llm_cache
from langchain_openai import ChatOpenAI
import os
#指定缓存 对比提问同样的问题,返回时间
set_llm_cache(SQLiteCache(database_path="langchain_demo.db"))
llm = ChatOpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url=os.getenv("DEEP_URL"), # Deepseek 的 API 基础地址
model="deepseek-v3:671b", # Deepseek 对话模型(可选:deepseek-chat-pro 等高级模型)
temperature=0.7, # 温度参数(0-1,越低越稳定)
max_tokens=1024 # 最大生成 tokens
)
#这时会向数据库里插入一条数据
response =llm.invoke("hello world")
print(response.content)
#再插入一条数据 注:是否插入要根据提示词和调用的模型(模型参数改变也会认为是不同)
response =llm.invoke("how are you")
print(response.content)
#这时就会从缓存里直接出结果不会送往大模型,数据库里也不会新插入一条数据
response =llm.invoke("hello world")
print(response.content)
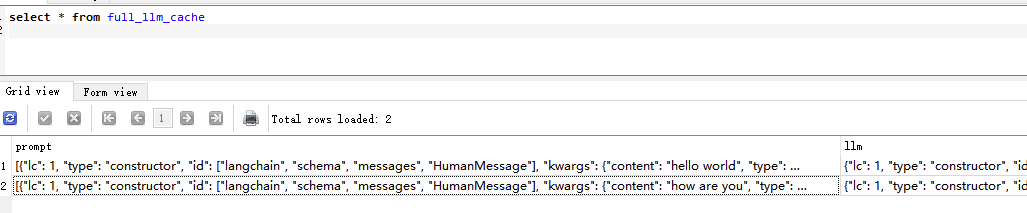
运行结果:可以看到 第一次的回答和第三次的回答是完全一样的。
Hello! 🌍 How can I assist you today? Whether you have questions, need help with a task, or just want to chat, I'm here for you! 😊 Hey there! Thanks for asking! I'm functioning at full capacity and ready to help you out. While I don't experience feelings in the way humans do, I genuinely enjoy our conversations and am always excited to learn and assist. How can I support you today? I'm all ears! 🌟 Hello! 🌍 How can I assist you today? Whether you have questions, need help with a task, or just want to chat, I'm here for you! 😊
我们可以看到,虽然我么提问了三次问题,但是缓存数据库里只有两条数据,说明第三次提问,回答是从缓存里走的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号